






在安装Hive时,需要在hive-site.xml文件中配置元数据相关信息。与传统关系型数据库不同的是,hive表中的数据都是保存的HDFS上,也就是说hive中的数据库、表、分区等都可以在HDFS找到对应的文件。这里说到的元数据可以理解成hive中用于保存数据库、表、分区或者表字段等基本属性,以及这些属性与HDFS文件对应关系的一个映射。
这些映射关系比较常见的一个场景是保存在mysql数据库中。接下来会分析hive安装时的一些配置信息,以及元数据库中主要表的用途。
一、hive配置
有关hive的配置都在hive-site.xml文件中。
| 属性 | 描述 | 默认值 |
|---|---|---|
| hive.metastore.warehouse.dir | 指定hive表在hdfs上的存储路径 | /user/hive/warehouse |
| javax.jdo.option.ConnectionURL | 配置元数据的连接URL | |
| javax.jdo.option.ConnectionUserName | 元数据库连接用户名 | |
| javax.jdo.option.ConnectionPassword | 元数据库连接密码 |
比如如下的配置:
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://m000:3306/hive</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hiveuser</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hiveuser</value>
<description>password to use against metastore database</description>
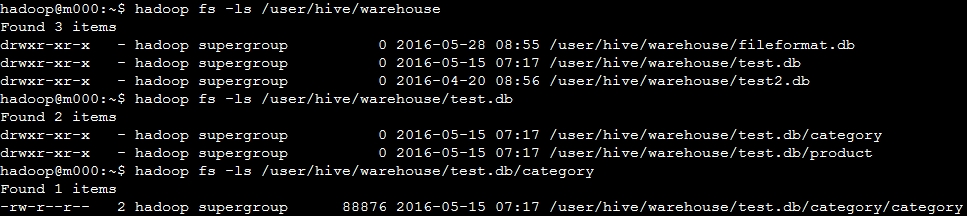
</property> 在hive中,默认情况下新建的数据库以及表都位于HDFS的hive.metastore.warehouse.dir路径下。如下图分别显示了数据库,表,以及表文件在HDFS上的文件路径
根据javax.jdo.option.ConnectionURL中设置的数据库,以及用户名和密码,hive就可以写入和读取其元数据信息。
连接元数据库除了配置URL,username,password之外,还有一种间接的方式。可以在hive客户端A上用hive --service metastore启动一个metastore服务,然后在另外一个hive客户端B的hive-site.xml文件中配置hive.metastore.uris=thrift://A:9083也可以访问到元数据信息(9083端口为默认,可使用-p参数手动指定)。
二、元数据库表描述
这一节描述hive元数据库中比较重要的一些表的作用,随着后续对hive的使用逐渐补充更多的内容。
mysql元数据库hive中的表:
| 表名 | 作用 |
|---|---|
| BUCKETING_COLS | 存储bucket字段信息,通过SD_ID与其他表关联 |
| CDS | 一个字段CD_ID,与SDS表关联 |
| COLUMNS_V2 | 存储字段信息,通过CD_ID与其他表关联 |
| DATABASE_PARAMS | 空 |
| DBS | 存储hive的database信息 |
| DELETEME1410257703262 | 空 |
| FUNCS | 空 |
| FUNC_RU | 空 |
| GLOBAL_PRIVS | 全局变量,与表无关 |
| IDXS | 空 |
| INDEX_PARAMS | 空 |
| PARTITIONS | 分区记录,SD_ID, TBL_ID关联 |
| PARTITION_KEYS | 存储分区字段,TBL_ID关联 |
| PARTITION_KEY_VALS | 分区的值,通过PART_ID关联。与PARTITION_KEYS共用同一个字段INTEGER_IDX来标示不同的分区字段。 |
| PARTITION_PARAMS | 存储某分区相关信息,包括文件数,文件大小,记录条数等。通过PART_ID关联 |
| PART_COL_PRIVS | 空 |
| PART_COL_STATS | 空 |
| PART_PRIVS | 空 |
| ROLES | 角色表,和GLOBAL_PRIVS配合,与表无关 |
| SDS | 存储输入输出format等信息,包括表的format和分区的format。关联字段CD_ID,SERDE_ID |
| SD_PARAMS | 空 |
| SEQUENCE_TABLE | 存储sqeuence相关信息,与表无关 |
| SERDES | 存储序列化反序列化使用的类 |
| SERDE_PARAMS | 序列化反序列化相关信息,通过SERDE_ID关联 |
| SKEWED_COL_NAMES | 空 |
| SKEWED_COL_VALUE_LOC_MAP | 空 |
| SKEWED_STRING_LIST | 空 |
| SKEWED_STRING_LIST_VALUES | 空 |
| SKEWED_VALUES | 空 |
| SORT_COLS | 排序字段,通过SD_ID关联 |
| TABLE_PARAMS | 表相关信息,是否外部表,通过TBL_ID关联 |
| TAB_COL_STATS | 空 |
| TBLS | 存储表信息,关联字段DB_ID,SD_ID, |
| TBL_COL_PRIVS | 空 |
| TBL_PRIVS | 表赋权限相关信息,通过TBL_ID关联 |
| VERSION | 版本 |
| VERSION_copy | 版本,通过VER_ID关联 |
这里补充介绍hive的一个工具脚本metatool。如果需要大量修改元数据库中的相关记录,可以具体查看metatool脚本的使用方法。
比如说,对一个HDFS做HA的时候,如果之前hdfs完整路径是hdfs://m000,做完HA之后把dfs.nameservices设置为my-cluster之后,hdfs的访问路径就变成了hdfs://my-cluster,此时就需要对hive元数据库中所有记录作更新,这时可以参考下面的操作,
使用metatool脚本,先是新路径,然后是旧路径 /usr/local/bigdata/hive/bin/metatool -updateLocation hdfs://my-cluster hdfs://m000
三、元数据库一些查询
有时根据需求,需要对hive中的表批量处理,这时可以到元数据库中进行一些查询操作,操作请慎重!!
下面会根据元数据库中的表结构和关联关系,陆续补充一些工作中使用到的查询语句。
1、查询某表的分区
在Spark-sql查询hive表时,会由于元数据中文件与hdfs文件不一致而出现TreeNodeException的异常。比如说,在hive中show partitions时有分区pt=20160601,但是对应HDFS路径下并没有这个子文件夹时,在Spark-sql中就会出现该异常。这时如果需要查询某表的分区,就可以使用如下语句
SELECT p.* from PARTITIONS p
JOIN TBLS t
ON t.TBL_ID=p.TBL_ID
WHERE t.TBL_NAME='table'
AND PART_NAME like '%pt=20160601%';
2、查询指定库中stored as textfile类型的所有表名
select
d.NAME,
t.TBL_NAME,
s.INPUT_FORMAT,
s.OUTPUT_FORMAT
from TBLS t
join DBS d
join SDS s
where t.DB_ID = d.DB_ID
and t.SD_ID = s.SD_ID
and d.NAME='test'
and s.INPUT_FORMAT like '%TextInputFormat%';3、查询指定库中的分区表
select
db.NAME,
tb.TBL_NAME,
pk.PKEY_NAME
from TBLS tb
join DBS db
join PARTITION_KEYS pk
where tb.DB_ID = db.DB_ID
and tb.TBL_ID=pk.TBL_ID
and db.NAME='test';4、查询指定库的非分区表
select
db.NAME,
tb.TBL_NAME
from TBLS tb
join DBS db
where tb.DB_ID = db.DB_ID
and db.NAME='test'
and tb.TBL_ID not in (
select distinct TBL_ID from PARTITION_KEYS
) ;5、查询指定库中某种存储类型的分区表
select
db.NAME,
tb.TBL_NAME,
pk.PKEY_NAME,
s.INPUT_FORMAT,
s.OUTPUT_FORMAT
from TBLS tb
join DBS db
join PARTITION_KEYS pk
join SDS s
where tb.DB_ID = db.DB_ID
and tb.TBL_ID=pk.TBL_ID
and tb.SD_ID = s.SD_ID
and db.NAME='test'
and s.INPUT_FORMAT like '%TextInputFormat%';6、查询指定库中某种存储类型的非分区表
select
db.NAME,
tb.TBL_NAME,
s.INPUT_FORMAT,
s.OUTPUT_FORMAT
from TBLS tb
join DBS db
join SDS s
where tb.DB_ID = db.DB_ID
and tb.SD_ID = s.SD_ID
and db.NAME='test'
and s.INPUT_FORMAT like '%TextInputFormat%'
and tb.TBL_ID not in (select distinct TBL_ID from PARTITION_KEYS);














 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









