






xpath解析
xpath解析是最常用且最便捷高效的一种解析方式,通用性最强。
xpath解析原理:
- 实例化一个etree的对象,且需要将被解析的页面源码数据加载到该对象中。
- 调用etree对象中的xpath方法接个着xpath表达式实现标签的定位和内容的捕获。
—如何实例化一个etree对象:from lxml import etree
将本地的html文档中的源码数据加载到etree对象中:etree.parse(filePath)
可以将从互联网上获取的源码数据加载到该对象中:etree.HTML('page_text')
xpath('xpath表达式'):
— /:表示的是从根节点开始定位,表示的是一个层级
— //:表示的是多个层级,可以表示从任意位置开始定位
— 属性定位://div[@class='song'] tag[@attrName='attrValue']
— 索引定位: //div[@class='song'] /p[3]索引是从1开始的,不是0.
— 取文本:
— /text() 获取的是标签中直系的文本内容
— //text() 获取的是标签中的非直系的文本内容(所有文本内容)
— 去属性值:
/@attrName ==>img/src
一个很重要的点,在我们进行局部解析的时候,也就是说这个时候我们不是以html为根节点了,这是后要用 ./开头,而不是/ 或者 // ,不然的话,会直接把你定位到html标签去。
响应数据的乱码问题
当我们想要在网站上获取中文内容的时候会发现,有时候会出现乱码,是因为网页上的默认编码都是ISO编码,而不是我们pycharm磨人的UTF-8,因此我们有两种方式改变编码。
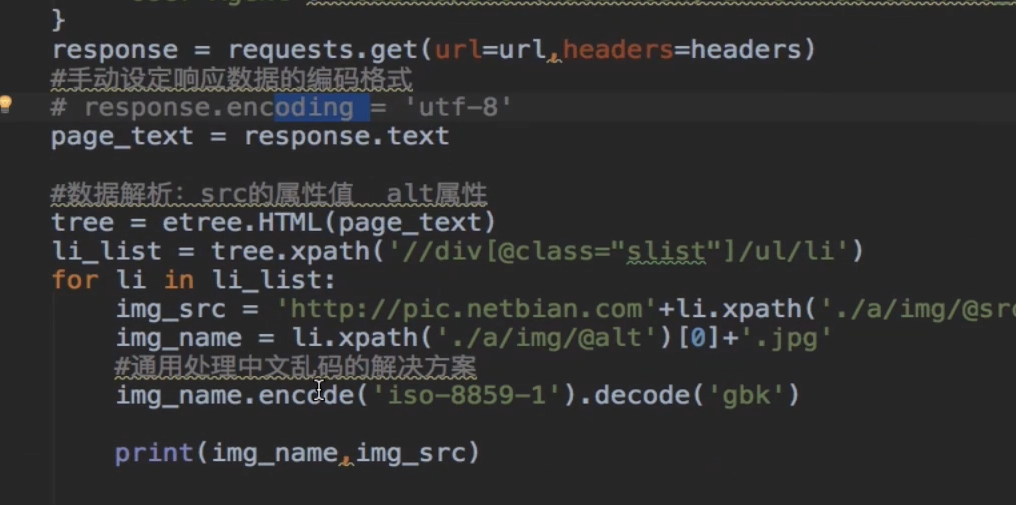
一种是直接把获取的响应数据用.encoding来改,如果没有用的话,就用下面,你想要的中文内容进行编码改变。
标签里的 id是唯一的,所以有id的时候就用id,不要用class吧。














 1196
1196











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









