







八爪鱼Xpath自定义数字翻页
常规数字翻页
常规的数字翻页设置后,抓取的页面停留在第一页。这是因为页码的html编码采用了li的列表式的数字。

这时候需要据此手动设置翻页的循环中的Xpath.
自定义Xpath数字翻页
流程图
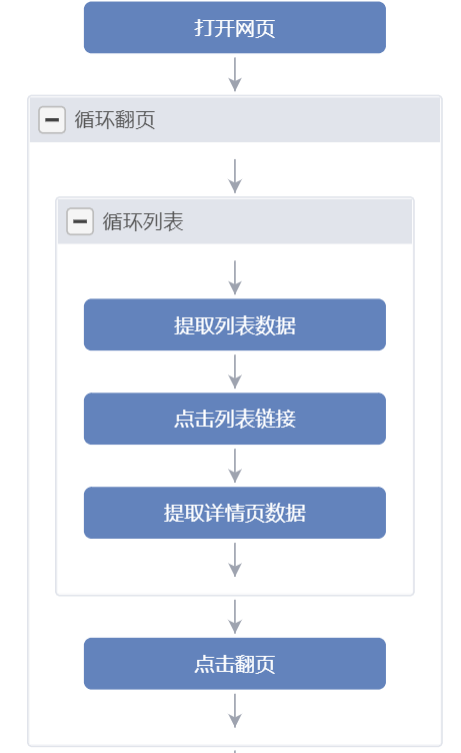
自定义Xpath
与上述html源码图对应的Xpath,取当前页的下一页。当前页的li的class属性为"page-number active"。将上述Xpath添加到“循环翻页”的设置中的“循环方式”定义为“单个元素”下的方框。
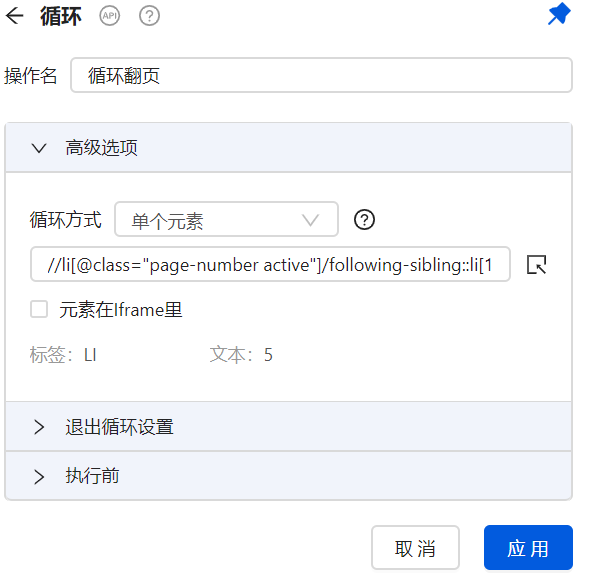
Xpath如下(需要根据当前页的属性进行定位后选取下一页):
//li[@class="page-number active"]/following-sibling::li[1]
调试Xpath
建议
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









