







AI 技术栈,包含编程语言、模型、LLM 框架、数据库等,能够快速大规模构建 AI 应用。
译自 The Evolution of the AI Stack: From Foundations to Agents,作者 Richmond Alake。
随着人工智能的重点从基础模型开发转向使软件工程师和开发人员能够快速且大规模地构建人工智能应用程序,人工智能工具领域出现了一种新的范式。这体现在“ 人工智能堆栈”中,这是一个综合的集成工具、解决方案和组件集合,旨在简化人工智能应用程序的开发和管理。
这种情况发生得非常快,与人工智能的最新发展同步。由于人工智能堆栈很大程度上建立在现有技术之上,因此在分解其组件和展望之前,值得回顾一下它是如何出现的。
建立基础
冒着听起来过于简化的风险,传统的 人工智能开发涉及使用随机森林、决策树和神经网络等技术构建回归和分类模型。典型的堆栈包括数据操作工具(如 Pandas)、机器学习库(如 Scikit-Learn)和深度学习框架(如 TensorFlow(Keras)、PyTorch 和 Caffe)。还有一些实验跟踪工具,例如 TensorBoard、MLflow 和 Neptune.ai。最后,部署工具将训练后的模型推广到生产环境中,并通过推理 API 端点授予消费者访问这些模型的权限。
可以说,还没有一个确立的通用堆栈。当然,研究和开发团队有首选的工具来完成特定任务,但还没有一个默认的堆栈。研究人员和从业人员通常分为两类,要么是 TensorFlow,要么是 PyTorch。
直到最近,研究成果和行业应用之间还存在着巨大的差距。
这种情况开始随着 AlexNet 的突破在 2012 年 ImageNet 大规模视觉识别挑战赛 (ILSVRC) 中发生改变,这在计算机视觉领域带来了更大的乐观情绪。虽然在图像分类方面取得了重大进展,但研究人员认识到,诸如目标检测之类的复杂任务仍然面临着相当大的挑战。此外,从研究突破到广泛的现实世界应用的路径比最初预期的要困难得多。
换句话说,引入研究突破并没有转化为快速采用,因为将尖端研究转化为适合消费设备的实用、可扩展和高效的应用程序存在复杂性。计算需求、缺乏标准化工具和框架以及需要针对不同硬件平台进行大量调整和优化等因素都导致了这种延迟。
2017 年在论文“ Attention Is All You Need”中引入的 Transformer 架构至关重要。它使开发能够跨不同领域处理大量数据的、大规模的通用语言模型成为可能。它克服了以前循环神经网络和长短期记忆架构的局限性。
缩小研究与实践之间的差距
第一代 GPT(生成式预训练 Transformer)于 2018 年发布,GPT-2 于 2019 年发布,GPT-3 于 2020 年发布。在 GPT 版本之间,其他基础模型(以及它们的代码)通过研究论文被引入。这些模型在几个月甚至几周内就找到了进入创意网络应用程序的方法。
随着研究与行业之间的差距缩小,新的工具使研究人员能够构建和试验新颖的神经网络。反过来,应用程序和系统基础设施方面的创新使工程师和开发人员能够在现实生活中的应用程序中利用这些强大的新模型。
人工智能领域的转变现在集中在寻找方法来赋予开发人员快速且大规模地构建人工智能应用程序的能力。这是一个重要的考虑因素,因为今天的人工智能堆栈并不关注开发和部署人工智能模型这一重要但相对已解决的任务,而是关注实现、优化、评估和监控人工智能应用程序和系统。
如今,基础模型开发方面的新研究经常发表,而针对大型语言模型 (LLM) 应用程序的工具每月都会出现。更重要的是,现代人工智能应用程序几乎可以立即利用研究成果。此外,数据丰富,计算设备越来越强大,这使得生成式人工智能 ( GenAI) 领域中扩展定律的充分应用成为可能。 大型语言模型 (LLM) 的供应格局已演变为一个分叉的生态系统。开源计划越来越专注于发布模型权重和超参数,促进微调而不是架构修改。专有模型在 REST API后面抽象实现细节。这种范式转变优化了开放模型的特定领域适应性和封闭系统的无缝集成,反映了在平衡模型可访问性和部署效率方面采取的细致入微的方法。
拆解 AI 堆栈
如前所述, 现代 AI 堆栈是一个集成的工具、解决方案和组件集合,使工程师和开发人员能够构建具有生成能力的 AI 应用程序,例如大规模的音频、图像和文本生成。它包括编程语言、模型提供商、LLM 框架、向量数据库、操作数据库、监控和评估工具以及部署解决方案。
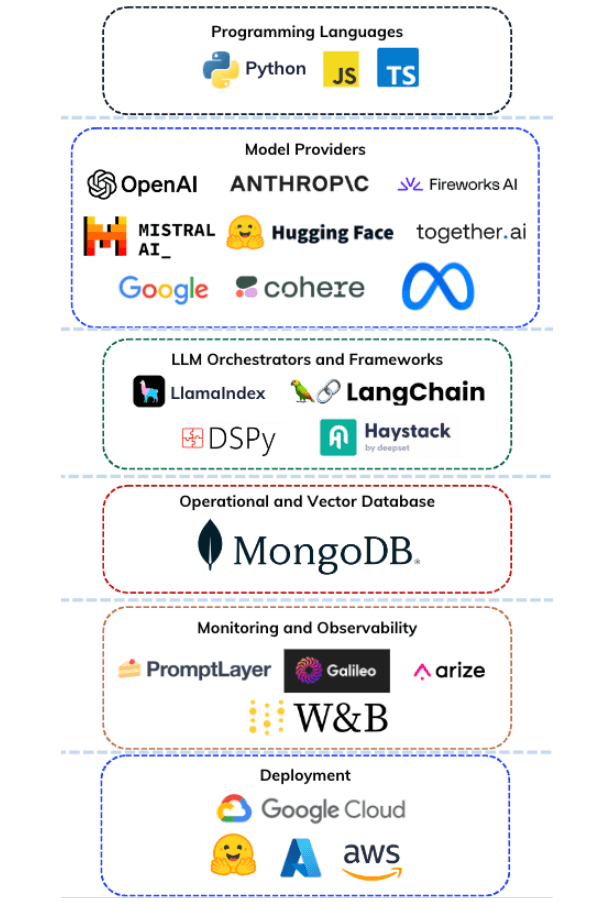
AI 堆栈基础设施使用来自基础模型的参数化知识和来自 PDF、数据库和搜索引擎等信息源的非参数化知识来执行 GenAI 功能。
AI 堆栈的关键组件包括:
- 编程语言: 用于开发堆栈组件的语言,包括集成代码和 AI 应用程序的源代码。
- 模型提供商: 通过推理端点或其他方式提供对基础模型访问权限的组织。嵌入模型和基础模型是 GenAI 应用程序中常用的模型。
- LLM 编排器和框架: 通过提供实现方法和集成包来抽象现代 AI 应用程序组件集成复杂性的库。这些组件中的操作员还提供工具来创建、修改和操作提示,并根据不同的目的对 LLM 进行条件化。
- 向量数据库: 用于向量嵌入的数据存储解决方案。此组件中的操作员提供有助于管理、存储和有效搜索向量嵌入的功能。
- 操作数据库: 用于事务和操作数据的数据库存储解决方案。
- 监控和评估: 用于跟踪 AI 模型性能和可靠性的工具,提供分析和警报以改进 AI 应用程序。
- 部署解决方案: 使 AI 模型能够轻松部署的服务,管理扩展并与现有基础设施集成。
现代 AI 堆栈代表了从传统机器学习的碎片化工具格局向更具凝聚力和专业化的生态系统的演变,该生态系统针对 LLM 和 GenAI 时代进行了优化。该堆栈旨在解决现代 AI 应用程序的独特而有趣的挑战,例如处理大型语言模型、管理向量嵌入以及在检索增强生成 (RAG) 管道或代理系统中编排复杂的 AI 工作流,这些系统利用 LLM 及其函数调用功能来自主执行任务。
介绍 POLM AI 堆栈
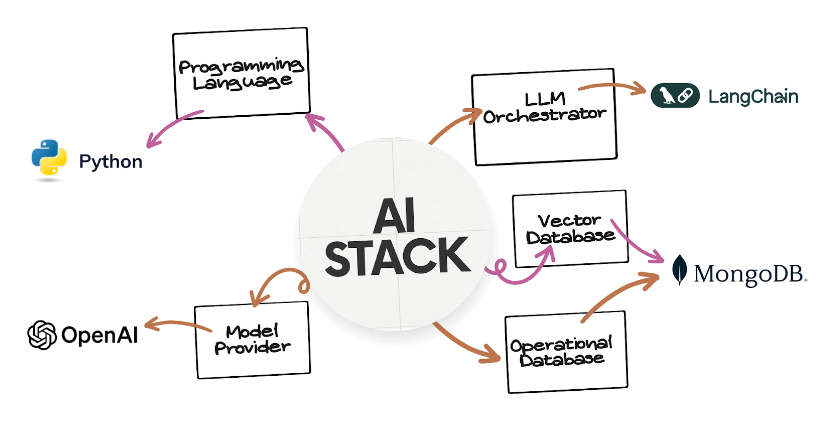
POLM ( Python, OpenAI, LlamaIndex/LangChain 和 MongoDB) AI 堆栈是使用 Python 编程语言实现的工具、解决方案和框架的集合。它旨在使现代 AI 应用程序的有效开发成为可能,处理与 AI 相关数据的非结构化性质,并满足现代应用程序的实时需求。其组件包括:
- 编程语言: Python
- 模型提供商: OpenAI (例如,GPT-3.5、GPT-4)
- LLM 编排器和集成器: LlamaIndex、LangChain
- 操作和向量数据库: MongoDB Atlas
POLM AI 堆栈提供了一个框架来开发 GenAI 应用程序,促进从概念验证到生产就绪系统的过渡。其针对 RAG 应用程序和基于代理的系统设计的架构使用统一的数据模型和语言一致性来提高开发效率。
POLM 堆栈的一个关键组件是其 基于文档的数据模型,它与 AI 生成的数据的非结构化性质相一致。该模型允许有效地存储和检索 AI 应用程序中常见的复杂嵌套数据结构,例如对话历史记录、嵌入向量和代理工具定义。
POLM 堆栈提供了一些功能,可以增强 GenAI 应用程序的开发过程:
- 统一数据库架构: 一个用于操作数据和向量嵌入的单一数据库解决方案,可以通过减少对多个存储解决方案的需求来简化 AI 基础设施。
- 统一编程语言: POLM 堆栈优先使用 Python 实现,这可以防止工具和库之间的代码切换,从而减少开发工作流程中的碎片化。
- 统一数据模型: 文档模型在不同的 AI 组件中提供一致的数据表示,从数据摄取到 LLM 函数调用功能的工具定义。这种方法简化了数据管理并通过允许支持单个数据库实例中各种查询类型的优化索引策略来提高查询性能。
本 教程提供了使用 LangChain作为 LLM 编排器和框架的分步说明。它演示了如何使用内存和语义缓存实现 RAG 系统,这些是 RAG 系统的成熟组件。同时,本第二个 教程使用 LlamaIndex 作为 LLM 框架展示了 POLM 堆栈。
面向代理系统的未来 AI 堆栈
AI 领域正在从 RAG 支持的聊天机器人发展到具有“人机交互”界面的代理系统。这种进步是由基础模型不断增长的能力推动的,包括工具使用和改进的推理能力。
像 LangChain 和 LlamaIndex 这样的 LLM 抽象框架正在扩展以支持基于代理的架构。同时,像 CreAI 和 AutoGen 这样的专门库正在出现以促进多代理系统开发。该堆栈还包含新的组件,例如用于实时搜索的 Tavily,它增强了 AI 代理收集数据和做出决策的能力。
虽然面向代理系统开发的专门库已经出现,但 AI 堆栈的核心组件对于这些系统来说基本保持不变。但是,面向代理系统的数据库基础设施需要更高的通用性,处理对话历史记录、操作数据和向量嵌入,以及语义缓存和数据流等功能。
随着 AI 应用不断成熟,代理系统将需要 AI 工具的进一步发展,特别是在数据库方面,这些数据库可以执行广泛的功能以支持这些复杂、动态的系统。我们预计下一波创新将出现在这里。
本文在 云云众生( https://yylives.cc/)首发,欢迎大家访问。















 825
825

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









