






1. MNIST数据集介绍
MNIST是一个手写数字数据库,样本收集的是美国中学生手写样本,比较符合实际情况,大体上样本是这样的:

MNIST数据库有以下特性:
- 包含了60000个训练样本集和10000个测试样本集;
- 分4部分,分别是一个训练图片集,一个训练标签集,一个测试图片集,一个测试标签集,每个标签的值是0~9之间的数字;
- 原始图像归一化大小为28*28,以二进制形式保存
2. Windows+caffe框架下MNIST数据集caffemodel分类模型训练及测试
1. 下载mnist数据
MNIST官网下载链接:http://yann.lecun.com/exdb/mnist/
打开之后可以看到包含红字部分的4个下载包:
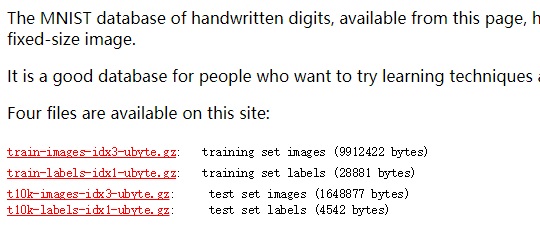
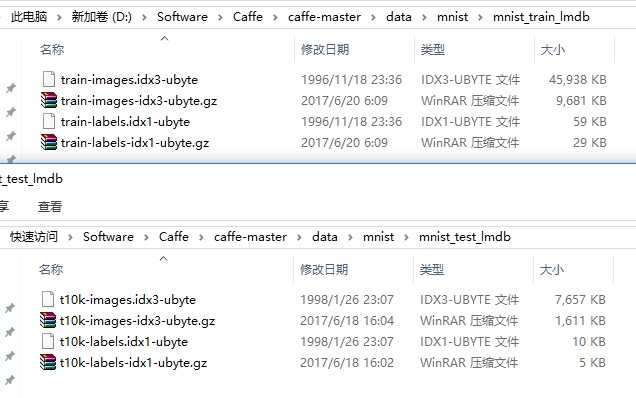
下载之后解压,我的caffe安装路径是 D:\Software\Caffe\caffe-master,所以训练数据和测试数据分别解压到了 D:\Software\Caffe\caffe-master\data\mnist\mnist_train_lmdb 和 D:\Software\Caffe\caffe-master\data\mnist\mnist_test_lmdb:
2. 将MNIST数据集转换为lmdb数据文件
caffe直接处理的数据分为两种格式: lmdb和leveldb,两者关系:
- 它们都是键/值对嵌入式数据库管理系统编程库
- 虽然lmdb的内存消耗是leveldb的1.1倍,但是lmdb的处理速度比leveldb快10%到15%,另外lmdb允许多种训练模型同时读取同一组数据集。
- lmdb取代了leveldb成为了caffe默认的数据集生成格式。
在caffe-master目录下新建一个create_mnist.bat脚本文件,输入以下内容:
.\Build\x64\Debug\convert_mnist_data.exe .\data\mnist\mnist_train_lmdb\train-images.idx3-ubyte .\data\mnist\mnist_train_lmdb\train-labels.idx1-ubyte .\examples\mnist\mnist_train_lmdb
echo.
.\Build\x64\Debug\convert_mnist_data.exe .\data\mnist\mnist_test_lmdb\t10k-images.idx3-ubyte .\data\mnist\mnist_test_lmdb\t10k-labels.idx1-ubyte .\examples\mnist\mnist_test_lmdb
pause
双击运行create_mnist.bat脚本文件,执行结果:
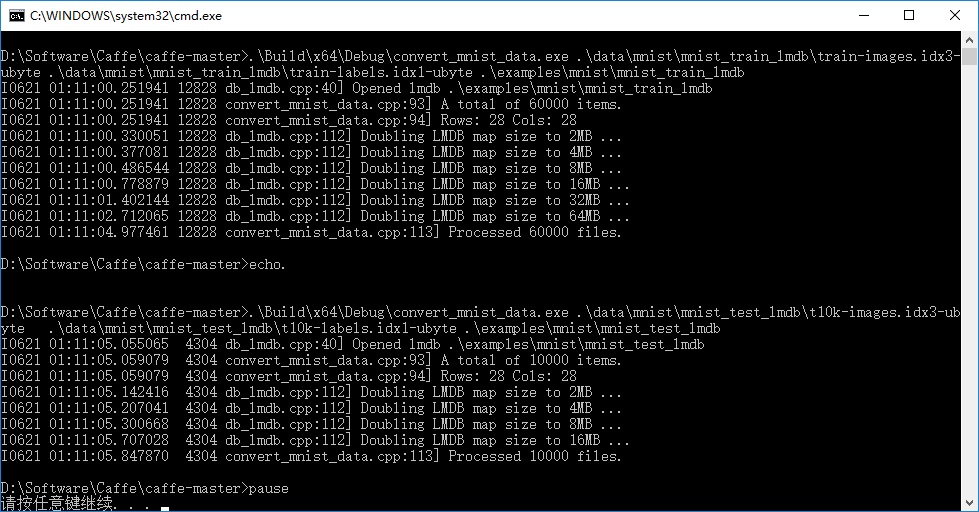
上述指令包括四部分内容,第一部分指定转换mnist数据集的.exe工具,第二部分传入mnist训练数据集的位置,第三部分传入mnist训练数据集的标签,第四部分指定lmdb文件的生成路径.
注意mnist_train_lmdb和mnist_test_lmdb两个文件夹是训练自动生成的,如果原文件下已经有这两个文件夹了,会报错。
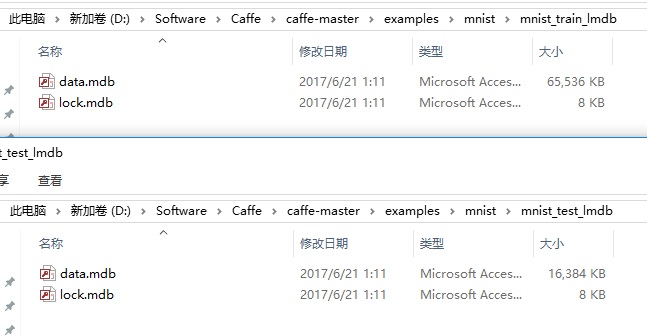
执行完成之后会在指定的文件夹目录下生成mdb文件。
3. 计算数据库的均值文件
均值文件实际上就是所有训练样本计算出来的平均值,在目标识别领域使用caffe时,一般都有一个减去均值的操作,这样可以提高训练速度和识别精度。编译后的caffe会在Debug/Release下生成计算均值文件的工具——cmpute_image_mean.exe,caffe里均值文件的数据格式是binaryproto。
在caffe-master目录下,新建一个mnist_mean.bat脚本文件,输入如下内容:
.\Build\x64\Debug\compute_image_mean.exe .\examples\mnist\mnist_train_lmdb .\examples\mnist\mean.binaryproto
pause 双击运行,执行结果:
执行完成之后会在mnist目录下生成mean.binaryproto均值文件:
4. lenet训练参数设置
lenet-5是一个经典的CNN网络模型,最初是在1986年设计的,主要是为了识别手写字体和计算机打印字符,特别是在手写字体识别领域非常成功,曾经被广泛应用在美国银行系统的支票手写字体识别上。
设置lmdb文件路径
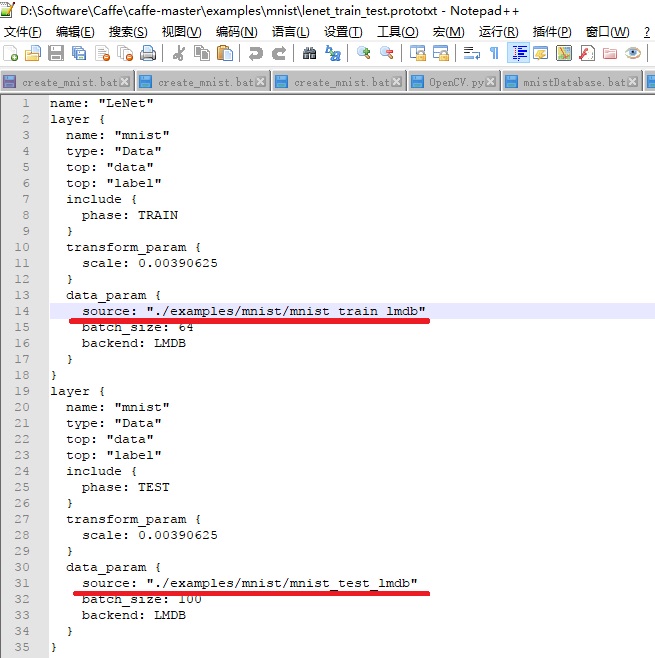
打开examples\mnist文件夹下的lenet_train_test.prototxt文件,两处source处输入lmdb文件夹的相对路径:
设置lenet训练参数
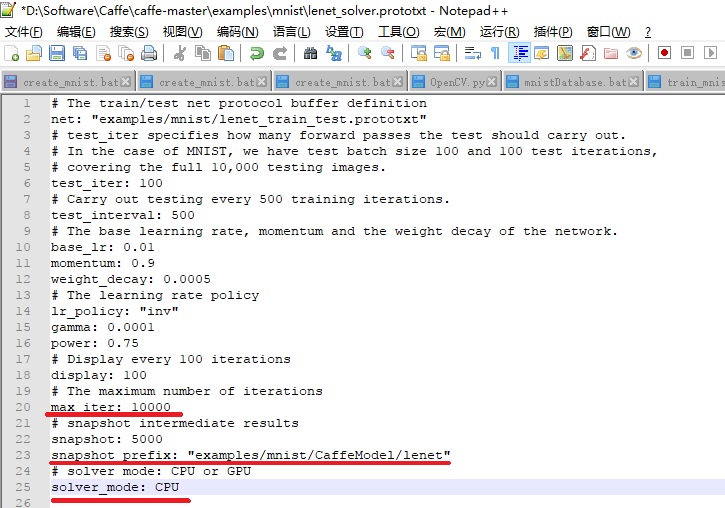
lenet训练参数设置是在examples\minst文件夹下的lenet_solver.prototxt文件内。基本设置有如下3个:
- GPU or CPU: caffe中lenet的训练参数默认是使用GPU,这里修改为CPU;
- 最大迭代次数: 最大迭代次数默认是10000,一般情况下最大迭代次数越大,训练的模型越准确,训练耗时也越长,这里max_iter的值10000不做修改。
- caffemodel生成路径:训练完成之后会生成caffemodel分类模型,默认生成路径是在mnist根目录,这里修改为mnist目录下的CaffeModel文件夹内,snapshot_prefix: "examples/mnist/CaffeModel/lenet";
3处修改的对应位置如下:
5. 执行lenet模型训练,生成caffemodel
在caffe-master目录下,新建一个train_mnist.bat脚本文件,输入以下内容:
.\Build\x64\Debug\caffe.exe train --solver=examples/mnist/lenet_solver.prototxt
pause双击运行,开始训练:
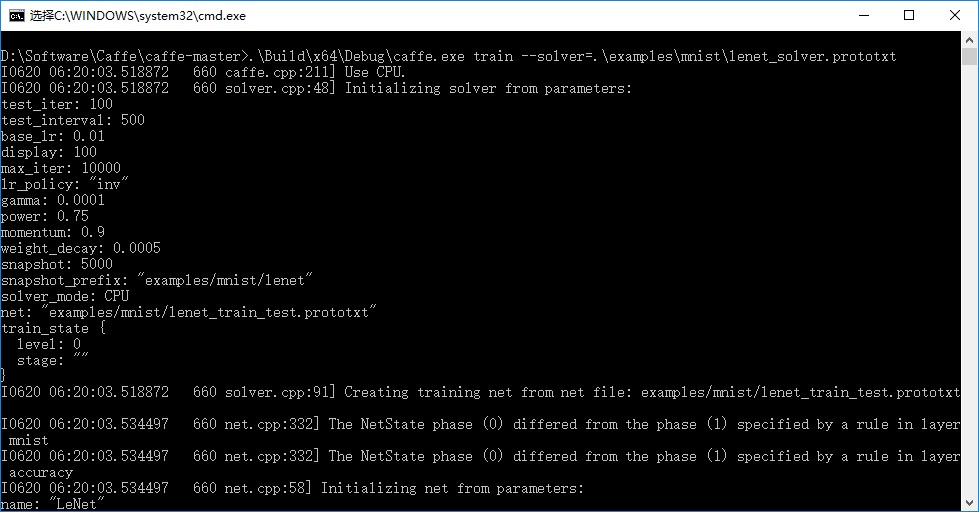
使用CPU,最大迭代次数10000情况下,训练耗时约25min,训练完成之后会输出该模型的识别准确率和损失率:
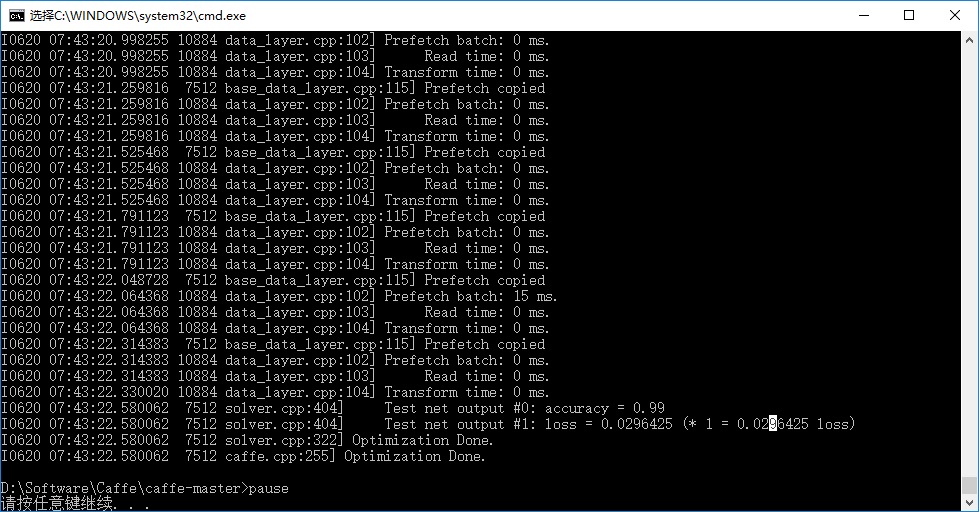
准确率约为99%, 训练完成后在设置的caffemodel生成路径 examples/minist/CaffeModel文件夹下生成caffemodel模型文件:
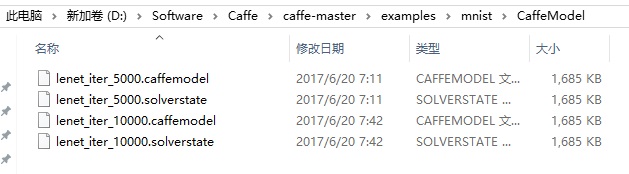
一共包含4个文件:
- lenet_iter_10000.caffemodel 和 lenet_iter_5000.caffemodel: 这两个文件是最终生成的caffemodel分类模型;
- lenet_iter_10000.solverstate 和 lenet_iter_5000.solverstate : 这两个文件是记录当前训练状态信息文件。在跑训练模型的时候遇到断电等异常情况导致训练中断,再次训练的时候就不必浪费时间从头开始训练,只需要调用 .solverstate文件,从上次训练中断的位置处继续训练即可,具体使用方法略过。
6. 使用caffemodel测试一下mnist测试数据集的分类准确率
这里使用上一步训练生成的caffemodel模型测试一下对mnist测试数据集的分类准确率。
在caffe-master目录下新建一个test-mnist.bat的脚本文件,输入以下内容:
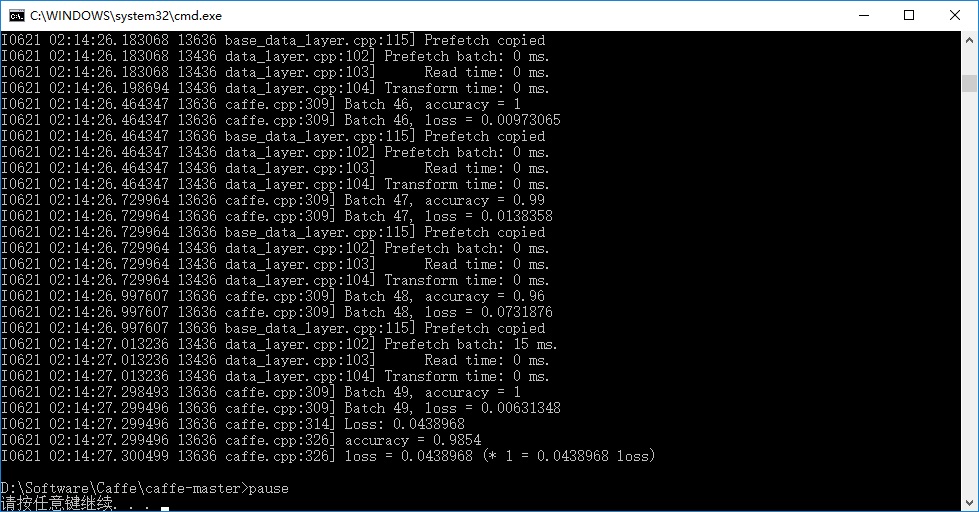
.\Build\x64\Debug\caffe.exe test --model=.\examples\mnist\lenet_train_test.prototxt -weights=.\examples\mnist\CaffeModel\lenet_iter_10000.caffemodel
pause 程序会根据lenet_train_test.prototxt文件里设置的测试数据集的路径自动加载到测试数据,双击运行,完成之后得到测试数据集的识别准确率,约为98.5%:















 3876
3876











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









