






上文提到MapReduce、HDFS是Hadoop的主要内容。本文简略翻译了<MapReduce:Simplified Data Processing on LargeClusters>,并对hadoop中org.apache.hadoop.mapreduce包的api分析,来概述MapReduce的思想。
1.翻译部分MapReduce
概念:MapReduce 是一个编程模型,处理和产生大数据集。使用这个模型写出的程序自动在一个大集群上并行执行。运行时系统负责分割输入数据/分配程序在不同的机器上运行/处理机器出错/管理机器间的通信。mapreduce可以让没有任何分布式和并行经验的程序员很容易地利用大分布式系统的资源。
使用:用户要指定两个函数:map函数和reduce函数。map处理一个键/值对生成一个中间键值对集合;reduce合并有相同中间键的中间值。Map接收一个key/value,产生一个key/value集合。MapReduce库把有相同key的值分成一组,Reduce接收一个中间key和它对应的值集合,然后合并这些值来形成一个可能较小的值集合。通常每次调用Reduce,仅仅产生0或1个输出值。这些中间值通过一个迭代器(iterator)传给reduce函数。
总之:整个MapReduce计算的输入是一个key/value集合,输出也是一个key/value集合。其中数据的分割、key对应值的分组、排序、数据的传递等都有系统(hadoop)负责。用户只负责写map/reduce函数。
抽象公式来简单表示:map (k1,v1)->list(k2,v2) reduce(k2,list(v2))->list(v2)。
具体例子来解释:统计url被访问的次数。map接收网页请求日志,输出一系列的<url,1>,如<google.com,1><baidu.com,1> <google.com,1>。
reduce把具有相同url的值加起来,产生<url,total count>。如<google.com,2> <baidu.com 1>。
2.API解释
常用到的类有:org.apache.hadoop.mapreduce.Job,Mapper,Reducer。
Job类是提交给集群执行的一个工作,通过Job可以配置、提交、控制工作的执行,也可以查询工作的状态。注:Job只能在提交前进行设置!
常用方法:void setJarByClass(Class)-指定包含执行类的Jar包;
void setMapperClass(class)-为工作指定Mapper类;void setReducerClass(Class)-指定Reducer类。
void setOutputKeyClass(Class)-指定最后输出的键(key)的数据类型;void setOutputValueClass(Class)-指定输出的值(value)类型。
void submit()-提交工作,然后立即返回;boolean waitForCompletion(boolean verbose)-提交工作,并等待执行结束,返回true表示job执行成功。verbose表示是否打印执行过程,true-打印。
Mapper类负责把输入的key/value映射为中间key/value。Maps are the individualtasks which transform input records into a intermediate records. The transformed intermediate records need not be of the same type as the inputrecords. A given input pair may map to zero or many output pairs.
主要方法:protected void map(KEYIN key, VALUEIN value,Mapper.Context context)-对每一个key/value对都会被调用一次。常常写新类继承Mapper来自定义该函数。
Reducer类用于简化中间键值集。主要有3个阶段:shuffle(暂译为聚合)-通过HTTP网络汇聚Mapper的输出;排序-将还有相同key的合并一组,排序和聚合是同时进行的;reduce简约。
主要方法:protected void reduce(KEYIN key, Iterable<VALUEIN> values,Reducer.Context context),该方法对每一个key都调用一次,通过继承Reducer来重写该方法。这其中的(key, collection of values)就是sort的结果。Reducer的输出值是不会重新排序的。
Mapper.Context,Reducer.Context,Job都继承自JobContext。字面意思理解是Job的上下文环境,保存着Job各种信息的数据结构。
3.流程图
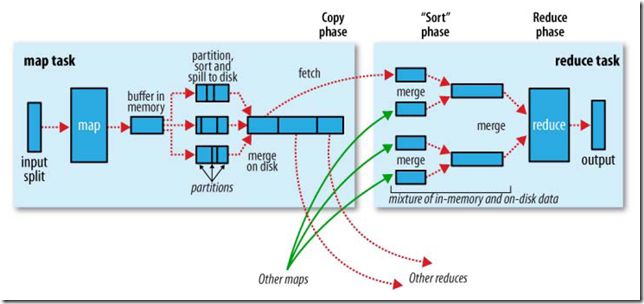
4.实例
Mapper类
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class CountWordMaper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key,Text value,
Context context)
throws IOException,InterruptedException {
String text=value.toString();
StringTokenizer tokens=new StringTokenizer(text);
while(tokens.hasMoreTokens()){
String str=tokens.nextToken();
context.write(newText(str), new IntWritable(1));
}
}
}
Reducer类
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class CountWordReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key,Iterable<IntWritable> values, Context context)
throws IOException,InterruptedException {
int total=0;
Iterator<IntWritable>it=values.iterator();
while(it.hasNext()){
it.next();
++total;
}
context.write(key, newIntWritable(total));
}
}
Main类:定义Job
import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class CountWord {
public static void main(String[] args)throws IOException, InterruptedException, ClassNotFoundException {
Job job=new Job();
//Set the Jar by finding where agiven class came from.
job.setJarByClass(CountWord.class);
//Add a Path to the list ofinputs for the map-reduce job.
FileInputFormat.addInputPath(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
job.setMapperClass(CountWordMaper.class);
job.setReducerClass(CountWordReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
System.exit(job.waitForCompletion(true)?0:1);
}
}
对于hadoop编程,只需引入hadoop-core.jar到项目中就可以了。但使用时需要打成jar包,把他们的Map Reduce代码捆绑到jar文件中,本人用eclipse打的,jar包类型要选择“seal the jar",指定包含主函数的类。运行时指定输入文件、输出目录即可。
用法:hadoop jar <jar> [mainClass] args...
hadoop jar CountWord.jar test.hadoop.CountWord input output1
结果:无图无真相!!!
输入文件

结果

补充下:使用前,要先启动hadoop:start-all.sh。直接使用hadoop命令,要把hadoop的bin目录加到环境变量path中去。
也注意到key是按照字母升序排列的,这都归功于reduce操作前的shuffle/sort。















 923
923

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









