






上篇文章最后提了个问题
假设某个表有一个复合索引(c1,c2,c3,c4),问以下查询中只能使用该复合索引的c1,c2,c3部分的有那些
1. where c1=x and c2=x and c4>x and c3=x
2. where c1=x and c2=x and c4=x order by c3
3. where c1=x and c4=x group by c3,c2
4. where c1=? and c5=? order by c2,c3
5. where c1=? and c2=? and c5=? order by c2,c3
建表测试
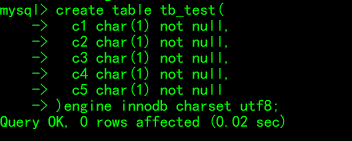
测试表中有五个列(c1,c2,c3,c4,c5),均为char(1)类型且不为空。字符集为utf8(索引长度以字节数计算)
创建复合索引

插入几条测试数据
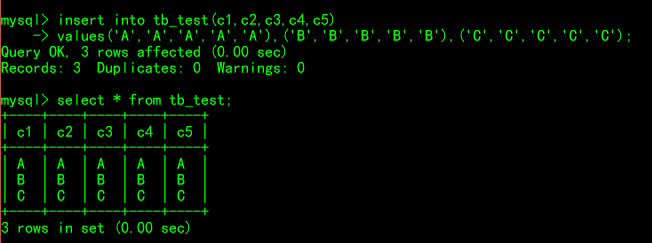
这里插几条数据,主要是为了防止空表对SQL优化器的影响
where c1=x and c2=x and c4>x and c3=x
用到了索引的所有部分,其中c1,c2,c3精确匹配,c4范围查询:
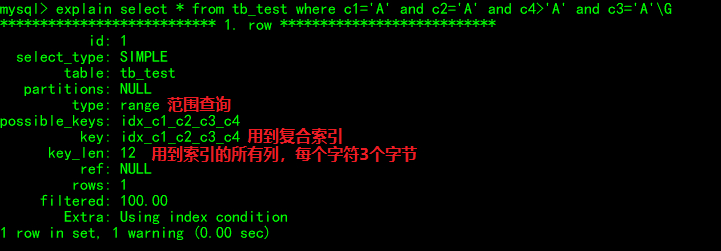
这里key_len=12,因为每个utf8字符占3个字节(BMP平面字符)。
虽然utf8对A、B、C这几个英文字符的编码方式与ASCII是兼容的(也就是一个字节),但char(1)为了保证能有足够的空间存储完整的utf8字符(比如中文),它会尽量申请一个最大的单字符空间,不然将来修改字符比较麻烦。也就是说MySQL会将原本utf8变长编码使用定长存储。
而utf8四字节以上的字符都属于补充平面,几乎不可能用到,所以MySQL就取了3个字节一个字符,这三字节utf8在mysql中叫做utf8mb3,mysql也支持4字节的utf8编码——utf8mb4。MySQL中utf8指的就是utf8mb3。另外我们建表时对每个字段都指定了not null的约束,如果使用默认的default null会多出一个字节。
关于utf-8编码原理可以参考《从ASCII、ISO-8859、GB2312、GBK到Unicode的UCS-2、UCS-4、UTF-8、UTF-16、UTF-32》
关于MySQL对Unicode编码的支持可以参考《Unicode Support》
Using index condition
出现Using index condition意味着没有达到索引覆盖。
查询语句通过索引过滤出几条记录,但是查询的内容超出索引范围,需要读取完整的数据行(这个过程也被叫做ICP,Index Condition Pushdown)。
出现ICP主要是因为我们用了select *。我们把SQL稍微改动一下,让它能达到索引覆盖
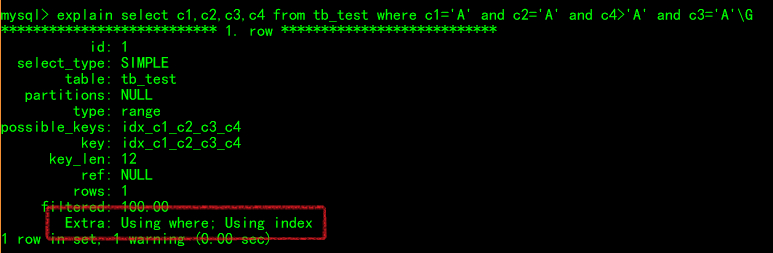
where c1=x and c2=x and c4=x order by c3
用到了索引的c1,c2,c3列,其中c1、c2列用于查询,c3用于排序。由于c3列没有精确匹配,导致c4列无法用到索引。

type: ref
ref指的是从表中读取匹配索引值的所有行。type=ref说明使用了索引的左前缀,或者完整地使用了索列但是索引不是primary key或unique key。
换句话说type=ref表明,查询语句不能通过索引查找到单独一行数据。
相反type: eq_ref就是使用了primary key或unique key的查询,这种查询能从表中唯一一条记录。
where c1=x and c4=x group by c3,c2
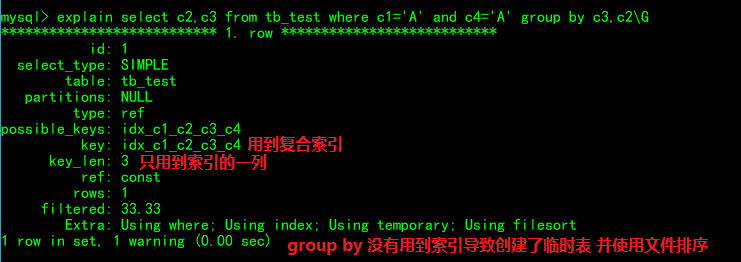
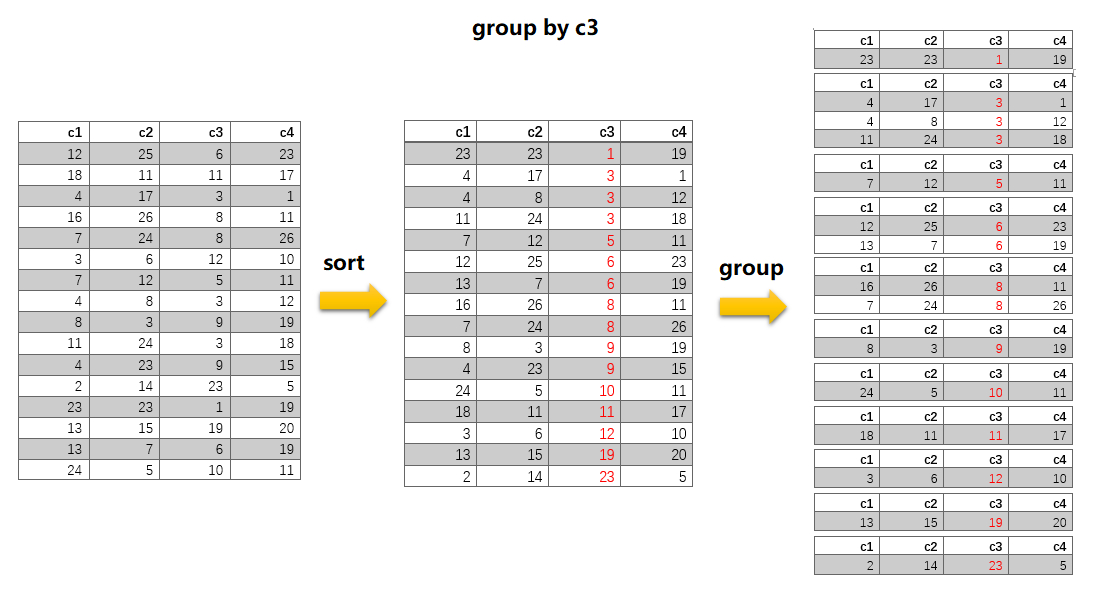
group by子句执行时会先排序,再分组。这条语句由于group by的顺序为c3,c2与索引顺序不匹配,所以没用到索引。
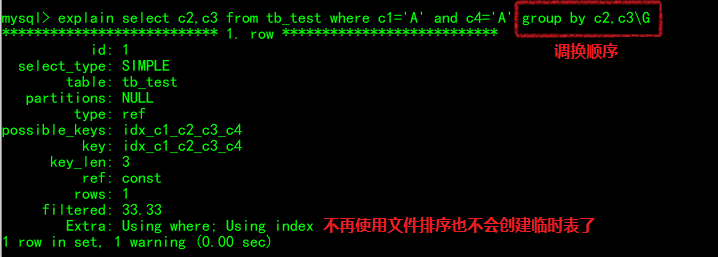
我们把group by的顺序调换一下就能然c2和c3列能用上索引进行排序分组。
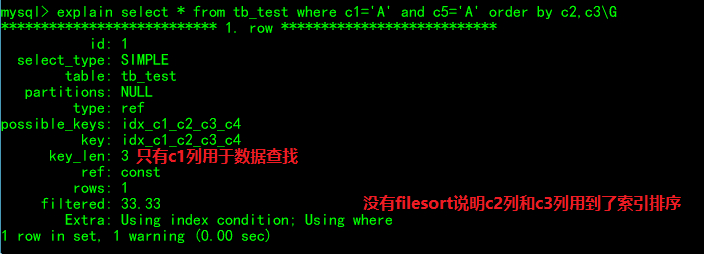
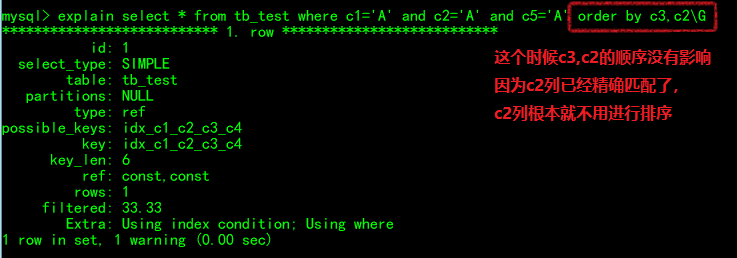
where c1=? and c5=? order by c2,c3
因为group by本质上也会执行order by操作,所以这条语句原理上和上面的差不多。
where c1=? and c2=? and c5=? order by c2,c3
这条查询和上条略有不同c1列和c2列已经使用索引精确匹配了,而order by再对c2进行排序已经没有意义了,因为过滤后的数据c2都是相等的,所以实际上只有c3列才用到排序。
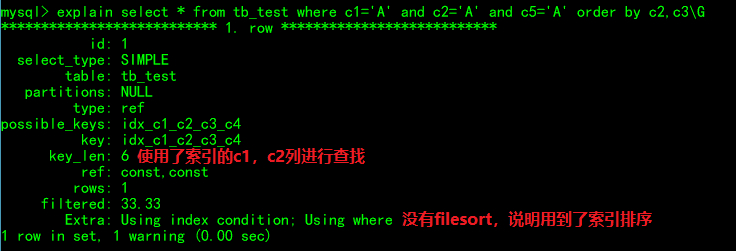
这个时候的修改order by中c2、c3列的顺序没有任何关系,因为c2列已经精确匹配了。
1. where c1=x and c2=x and c4>x and c3=x
用到(c1,c2,c3,c4)列进行数据查找
2. where c1=x and c2=x and c4=x order by c3
用到(c1,c3)列进行数据查找,c3列索引排序
3. where c1=x and c4=x group by c3,c2
只是用了(c1)列进行数据查找
4. where c1=? and c5=? order by c2,c3
使用(c1)列进行数据查找,c2,c3列索引排序
5. where c1=? and c2=? and c5=? order by c2,c3
使用(c1,c2)列进行数据查找,c3列索引排序
这个问题原出自一个论坛,这里重新测试并对结果稍作整理
参考:
https://dev.mysql.com/doc/refman/5.7/en/explain-output.html















 1347
1347











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









