






分布式系统海量日志,如何获取并进行各种分析得出实时或者非实时的分析结果
活动流数据:页面访问量(Page View)、被查看内容方面的信息以及搜索情况等内容。这种数据通常的处理方式是先把各种活动以日志的形式写入某种文件,然后周期性地对这些文件进行统计分析。
运营数据指的是服务器的性能数据(CPU、IO使用率、请求时间、服务日志等等数据)。
常见的分布式日志收集系统:
linkedin的kafka(可以用来做消息队列、流式处理(一般结合storm)、日志聚合等):
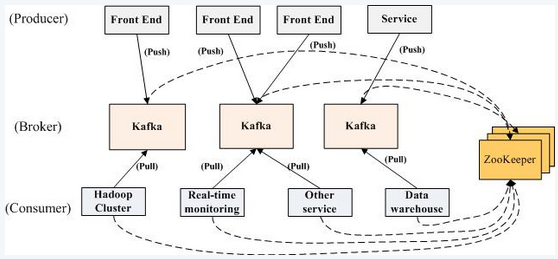
水平扩展和高吞吐率的消息系统,以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间复杂度的访问性能,支持消息分区,分布式消费,保证每个partition内的消息顺序传输。Scala编写,push/pull,发布订阅系统,producer(可以是web前端产生的Page View,或者是服务器日志,系统CPU、Memory等)向broker发送数据,即向topic发布消息,consumer订阅每个topic,每个topic又分为多个partition(任一partition都可以被且只被一个消费者消费)便于管理和负载均衡,通过zookeeper协调。消费逻辑保存在客户端,对消息进行分区,利用文件系统顺序性提升效率,0-copy/send file系统调用提升效率,充分利用操作系统缓存,减少系统内用户区和系统区的复制。
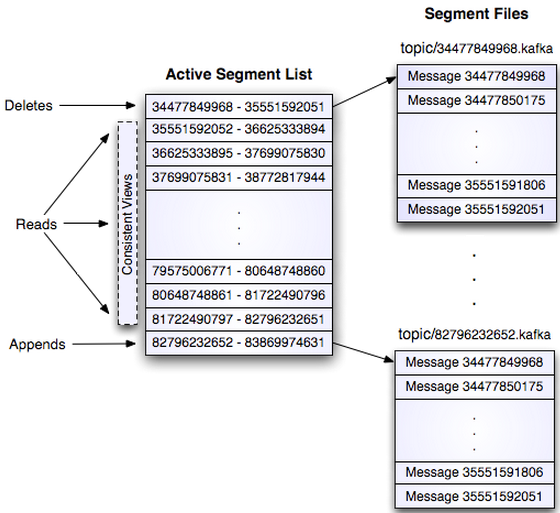
每条消息都被append到该Partition中,属于顺序写磁盘,因此效率非常高,顺序写磁盘效率比随机写内存还要高
每个partition内的消息是有序的,而一个partition只能被一个消费者消费,因此Kafka能提供partition层面的消息有序,而传统的队列在多个consumer的情况下是完全无法保证有序的。
物理上把Topic分成一个或多个Partition,每个Partition在物理上对应一个文件夹,该文件夹下存储这个Partition的所有消息和索引文件。
现代操作系统都乐于将空闲内存转作磁盘缓存(页面缓存),想不用都难;对于这样的系统,他的数据在内存中保存了一份,同时也在OS的页面缓存中保存了一份,这样不但多了一个步骤还让内存的使用率下降了一半;因此,Kafka决定直接使用页面缓存;但是随机写入的效率很慢,为了维护彼此的关系顺序还需要额外的操作和存储,而线性的写入可以避免这些,实际上,线性写入(linear write)的速度大约是300MB/秒,但随即写入却只有50k/秒,其中的差别接近10000倍。这样,Kafka以页面缓存为中间的设计在保证效率的同时还提供了消息的持久化,每个消费者自己维护当前读取数据的offser(也可委托给zookeeper),以此可同时支持在线和离线的消费。
Kafka集群会保留所有的消息,无论其被消费与否,两种策略删除旧数据。一是基于时间,二是基于Partition文件大小。可以通过配置$KAFKA_HOME/config/server.properties,让Kafka删除一周前的数据,也可在Partition文件超过1GB时删除旧数据。
Kafka读取特定消息的时间复杂度为O(1),即与文件大小无关
每一个Consumer Group保留一些metadata信息——当前消费的消息的position,也即offset。这个offset由Consumer控制。正常情况下Consumer会在消费完一条消息后递增该offset。当然,Consumer也可将offset设成一个较小的值,重新消费一些消息。因为offet由Consumer控制,所以Kafka broker是无状态的,它不需要标记哪些消息被哪些消费过,也不需要通过broker去保证同一个Consumer Group只有一个Consumer能消费某一条消息,因此也就不需要锁机制,这也为Kafka的高吞吐率提供了有力保障。
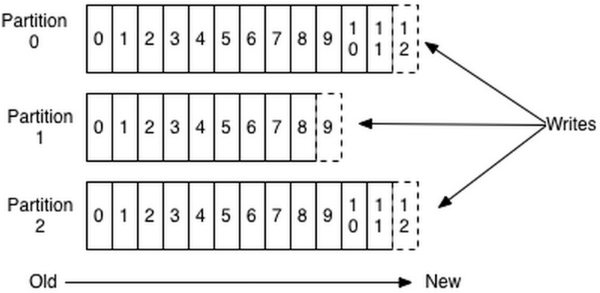
Producer发送消息到broker时,会根据Paritition机制选择将其存储到哪一个Partition。如果Partition机制设置合理,所有消息可以均匀分布到不同的Partition里,这样就实现了负载均衡。如果一个Topic对应一个文件,那这个文件所在的机器I/O将会成为这个Topic的性能瓶颈,而有了Partition后,不同的消息可以并行写入不同broker的不同Partition里,极大的提高了吞吐率。可以在$KAFKA_HOME/config/server.properties中通过配置项num.partitions来指定新建Topic的默认Partition数量,也可在创建Topic时通过参数指定,同时也可以在Topic创建之后通过Kafka提供的工具修改。
在发送一条消息时,可以指定这条消息的key,Producer根据这个key和Partition机制来判断应该将这条消息发送到哪个Parition。Paritition机制可以通过指定Producer的paritition. class这一参数来指定,该class必须实现kafka.producer.Partitioner接口。本例中如果key可以被解析为整数则将对应的整数与Partition总数取余,该消息会被发送到该数对应的Partition。(每个Parition都会有个序号,序号从0开始)
使用Consumer high level API时,同一Topic的一条消息只能被同一个Consumer Group内的一个Consumer消费,但多个Consumer Group可同时消费这一消息。
Kafka默认保证At least once,并且允许通过设置Producer异步提交来实现At most once。而Exactly once要求与外部存储系统协作,幸运的是Kafka提供的offset可以非常直接非常容易得使用这种方式。
cloudera的flume:
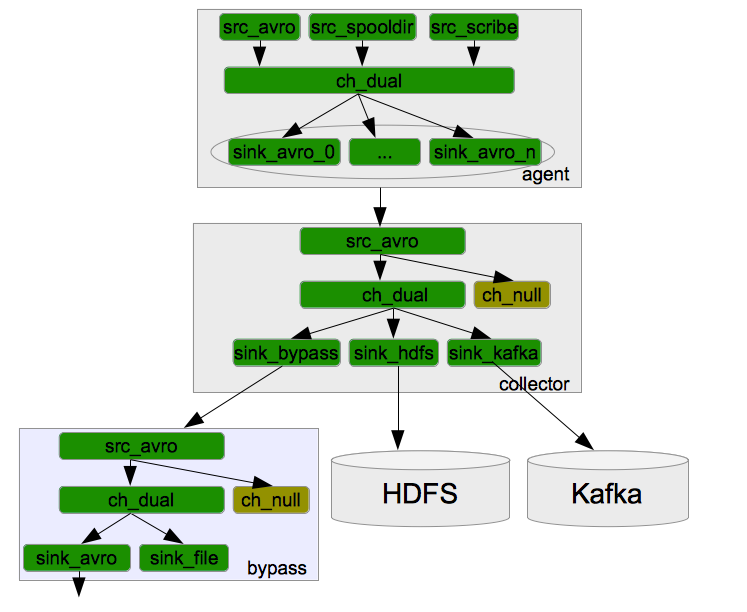
Flume采用了分层架构,由三层组成,分别为agent,collector和storage。其中Agent层每个机器部署一个进程,负责对单机的日志收集工作;Collector层部署在中心服务器上,负责接收Agent层发送的日志,并且将日志根据路由规则写到相应的Store层中;Store层负责提供永久或者临时的日志存储服务,或者将日志流导向其它服务器
当节点出现故障时,日志能够被传送到其他节点上而不会丢失。Flume提供了三种级别的可靠性保障,从强到弱依次分别为:end-to-end(收到数据
agent首先将event写到磁盘上,当数据传送成功后,再删除;如果数据发送失败,可以重新发送。),Store on failure(这也是scribe采用的策略,当数据接收方crash时,将数据写到本地,待恢复后,继续发送),Best effort(数据发送到接收方后,不会进行确认)。Flume采用了三层架构,分别问agent,collector和storage,每一层均可以水平扩展。其中,所有agent和collector由master统一管理,这使得系统容易监控和维护,且master允许有多个(使用ZooKeeper进行管理和负载均衡),这就避免了单点故障问题。
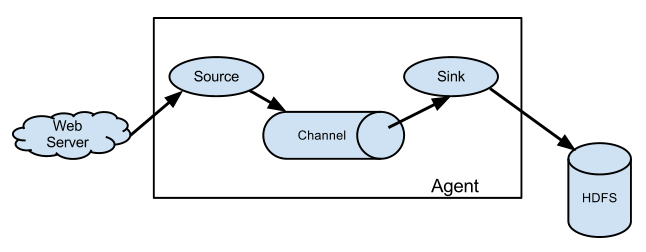
Source:
从数据发生器接收数据,并将接收的数据以Flume的event格式传递给一个或者多个通道channal,Flume提供多种数据接收的方式,比如Avro,Thrift,twitter等
Channel:
channal是一种短暂的存储容器,它将从source处接收到的event格式的数据缓存起来,直到它们被sinks消费掉,它在source和sink间起着一共桥梁的作用,channal是一个完整的事务,这一点保证了数据在收发的时候的一致性. 并且它可以和任意数量的source和sink链接. 支持的类型有: JDBC channel , File System channel , Memort channel等.
sink:
sink将数据存储到集中存储器比如Hbase和HDFS,它从channals消费数据(events)并将其传递给目标地. 目标地可能是另一个sink,也可能HDFS,HBase.
美团的日志收集系统的模块分解图,详解Agent, Collector和Bypass中的Source, Channel和Sink的关系
参考自 http://www.aboutyun.com/thread-8317-1-1.html
日志监控时如果机器死掉,则日志也不产生了,无影响,如果是agent进程死掉,则可以监控设置重启,或日志持久化磁盘,重启后重读
中心服务器提供的是对等的且无差别的服务,且Agent访问Collector做了LoadBalance和重试机制。所以当某个Collector无法提供服务时,Agent的重试策略会将数据发送到其它可用的Collector上面。所以整个服务不受影响。
Target可以配置双目标,当hdfs不可用则临时用FileChannel缓存,如果文件缓存太慢,则利用MemChannel传递数据减少延时
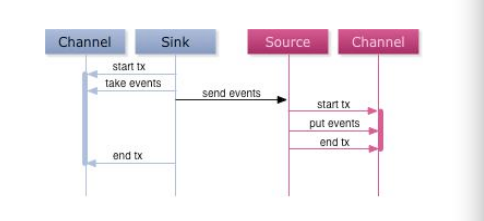
所有的events都被保存在Agent的Channel中,然后被发送到数据流中的下一个Agent或者最终的存储服务中。那么一个Agent的Channel中的events什么时候被删除呢?当且仅当它们被保存到下一个Agent的Channel中或者被保存到最终的存储服务中。这就是Flume提供数据流中点到点的可靠性保证的最基本的单跳消息传递语义。Agent间的事务交换。Flume使用事务的办法来保证event的可靠传递。Source和Sink分别被封装在事务中,这些事务由保存event的存储提供或者由Channel提供。这就保证了event在数据流的点对点传输中是可靠的。
facebook的scribe(epoll方式):
从各种日志源上收集数据,存储到中央系统,集中统计分析处理,容错性好。当后端的存储系统crash时,scribe会将数据写到本地磁盘上,当存储系统恢复正常后,scribe将日志重新加载到存储系统中
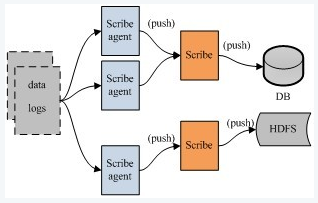
Agent是thrift client,向scribe发送数据用,Scribe接受agent发来的数据,根据配置将不同topic的数据发送给不同的对象,进行各种存储
apache的chukwa:
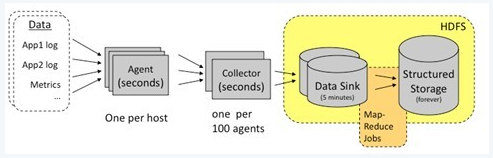
Adapter这里没有,封装其他数据源,文件命令 系统参数 hadoop log等,HDFS初衷是支持大文件和小并发高速写,日志系统是高并发低速写和大量小文件存储,所以增加collector和agent,agent给adapter提供各种服务,包括启动关闭adapter,将数据通过HTTP传递给Collector,定期记录adapter的状态便于故障恢复。collector对多个数据源发来的数据进行合并,加载到HDFS,隐藏HDFS细节。
Splunk:
好用,贵
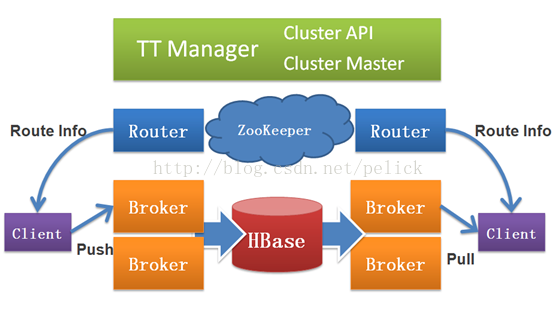
淘宝Time Tunnel:
基于thrift通讯框架搭建的实时数据传输平台,具有高性能、实时性、顺序性、高可靠性、高可用性、可扩展性等特点(基于Hbase)
logstash:
ELK(ElasticSearch, LogStash, Kibana)
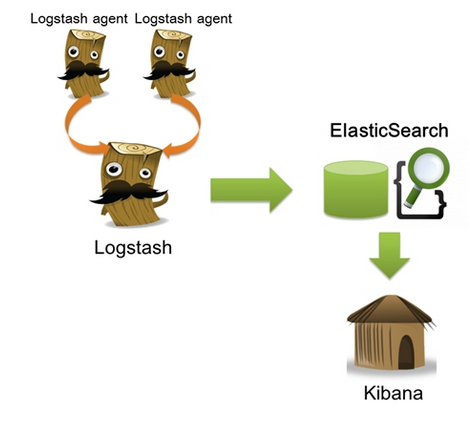
input 数据输入端,可以接收来自任何地方的源数据。
Filter 数据中转层,主要进行格式处理,数据类型转换、数据过滤、字段添加,修改等。
output 是logstash工作的最后一个阶段,负责将数据输出到指定位置,兼容大多数应用。
参考:
http://www.mincoder.com/article/3942.shtml














 4086
4086











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









