






spark内存按用途分为两大类:execution memory和storage memory。其中execution memory是spark任务用来进行shuffle,join,sort,aggregation等运算所使用的内存;storage memory是用来缓存和传播集群数据所使用的内存。在storage memory中还存在一个unroll memory。这个memory存在于将非序列化的数据保存到storage代表的内存的过程中。由于可能要存储的非序列化数据过大,为了避免直接读取所有非序列化数据造成内存溢出,Spark采用逐步读取的策略,将读取的数据预估大小保存到unroll memory中,如果unroll memory不足则向storage申请内存。如果最终内存可以成功读取传入的数据,则清空unroll memory(将内存还回storage memory),并从storage memory中申请对应大小的内存,并实际将数据保存到内存中。(注意的是这里的unroll memory和storage memory内存的更新都只是数值的变化,并不实际分配或释放内存)
spark在1.6开始启用了新的动态内存管理模型代替了之前的静态内存管理模型,新的内存模型如下:
设JVM一共的内存为T,其中JVM有300MB的保留内存,execution和storage共享内存占比可以通过spark.memory.fraction配置(默认为0.6),在execution和storage共享内存中,storage的占比可以通过spark.memory.storageFraction配置(默认为0.5),在storage内存中每个任务的unroll初始为1MB,上限与storage的上限相同。
新老模型的区别主要在于新模型中,execution和storage的内存可以互相使用,且unroll内存不再设置上限;而老模型中execution和storage的内存是相互隔离的,如果出现一方内存不足,而另一方内存充足的情况,内存不足的一方也不能使用内存充足一方的内存。
Spark可以指定使用堆内内存存储模式还是堆外内存存储模式。但是storage内存好像只使用了堆内存储模式,只有execution内存可以选择是使用堆内存储还是堆外存储。Spark使用名为tungsten的内存管理机制来管理内存的分配和回收。tungsten主要使用类似操作系统的页管理模式将内存分成多个页,实现逻辑内存地址到物理内存地址的转换,统一了堆内和堆外内存的管理。
spark内存管理配置
| 配置参数 | 默认值 | 说明 |
|---|---|---|
| spark.memory.fraction | 0.6 | 设置spark的execution和storage memory一共使用(JVM堆内存-300MB)的比例。 |
| spark.memory.storageFraction | 0.5 | execution&storage共享内存中storage内存所占比例。默认是一半,即storage内存默认为(JVM堆内存-300MB) 0.6 0.5 |
| spark.memory.offHeap.enabled | false | 是否开启堆外存储模式 |
| spark.memory.offHeap.size | 0 | 在开启堆外存储模式时,堆外存储的内存大小。这个配置需要spark.memory.offHeap.enabled=true |
spark内存管理流程图
MemoryStore是Spark缓存数据(使用storage memory)的入口,由BlockManager调用。MemoryStore有两类数据的保存形式:将序列化数据保存到storage内存中,和将非序列化数据保存到内存中。对于非序列化数据,由于可能传入的数据过大,为了避免内存溢出,需要先估算传入的非序列化数据大小,并申请unroll内存,如果发现非序列化数据可以放入内存则再实际将数据保存到内存中。Spark当前存在两种内存管理器(通过spark.memory.useLegacyMode指定,默认使用新的内存管理方法即UnifiedMemoryManager),内存管理器管理着StorageMemoryPool和ExecutionMemoryPool,负责向其申请和释放内存,每个JVM中只有一个内存管理器。流程如下: 
- 对于保存序列化数据(putBytes),首先向StorageMemoryPool申请storage内存,如果内存不足则StorageMemoryPool会收回借用给execution并还没有被使用的内存。对于保存非序列化数据(putIterator),首先预估存入的数据大小,并向StorageMemoryPool申请unroll内存,如果内存充足,则释放unroll内存,并申请数据大小的storage内存
- 如果内存充足则将数据封装为MemoryEntry保存到MemoryStore的map中
MemoryConsumer是Spark任务运行申请内存(使用execution memory)的入口,MemoryConsumer为抽象类,需要申请内存进行计算的类继承自MemoryConsumer。TaskMemoryManager是管理每个任务申请的execution内存的类,每一个executor对应一个TaskMemoryManager。任务运行可以使用堆内内存也可以使用堆外内存(根据配置文件参数spark.memory.offHeap.enabled指定)。流程如下: 
- MemoryConsumer向TaskMemoryManager申请execution内存
- TaskMemoryManager向ExecutionMemoryPool申请内存,如果execution内存不足,会借用storage内存,如果还不足会强制将storage中缓存的数据刷新到磁盘上释放内存
- 如果ExecutionMemoryPool返回的内存不足,则调用MemoryConsumer.spill方法,将MemoryConsumer占用的内存数据刷新到磁盘上释放内存
- 根据配置的内存模式,为MemoryConsumer分配堆内/堆外内存
- 分配的内存会被包装为MemoryBlock,每个MemoryBlock对应一个page
- TaskMemoryManager中维护了任务的pageTable,任务可以通过page number查询到对应的MemoryBlock
源码解析
spark内存管理相关的模块/包比较多,总体包括:
- core/java/org.apache.spark.memory
- core/scala/org.apache.spark.memory
- core/scala/org.apache.spark.storage/memory
- common/unsafe/java/org.apache.spark.unsafe.memory
其中core/scala/org.apache.spark.memory包包含的是内存管理的核心类,包括MemoryManager、MemoryPool以及具体实现类。
core/scala/org.apache.spark.storage/memory包只有一个类MemoryStore,主要用来将数据块以序列化/非序列化的形式写入storage memory中
core/java/org.apache.spark.memory包包含了三个类:MemoryConsumer,TaskMemoryManager,MemoryMode,主要用来处理spark任务申请/释放execution memory的逻辑。
common/unsafe/java/org.apache.spark.unsafe.memory包被TaskMemoryManager申请/释放内存方法调用,用来实际申请内存。
这里首先介绍内存管理核心类(core/scala/org.apache.spark.memory包内存),然后再按execution和storage分别介绍申请/释放execution memory和storage memory相关类。
内存管理核心类(core/scala/org.apache.spark.memory)
MemoryPool
memoryPool是组成MemoryManager的类,它包括两个具体实现类:ExecutionMemoryPool和StorageMemoryPool,分别对应execution memory和storage memory。memoryPool及其子类的主要用途是用来标记execution/storage内存的使用情况(已使用内存大小,剩余内存大小,总内存大小等)。当需要新的内存时,spark通过memoryPool来判断内存是否充足。需要注意的是memoryPool以及子类方法只是用来标记内存使用情况,而不实际分配/回收内存。
/**
* 返回当前pool的大小
*/
final def poolSize: Long = lock.synchronized { _poolSize } /** * 返回当前pool可用内存大小 */ final def memoryFree: Long = lock.synchronized { _poolSize - memoryUsed } /** * 增大pool大小 */ final def incrementPoolSize(delta: Long): Unit = lock.synchronized { require(delta >= 0) _poolSize += delta } /** * 减小pool大小 */ final def decrementPoolSize(delta: Long): Unit = lock.synchronized { require(delta >= 0) require(delta <= _poolSize) require(_poolSize - delta >= memoryUsed) _poolSize -= delta } ExecutionMemoryPool
ExecutionMemoryPool被用来记录被任务使用的内存情况。ExecutionMemoryPool保证每个任务都能获取到一定的内存大小,避免先来的任务直接占用绝大部分内存导致后来的任务为了获取到足够的内存而频繁的进行刷磁盘操作。如果有N个任务,ExecutionMemoryPool保证任务所占有的内存在被收回前可至少获取到1 / 2N大小的内存,最多可以获取1 / N大小的内存,其中N是处于active状态的任务数。由于N是动态变化的,这个类会跟踪N的变化,在N改变时通过notifyAll的方法通知处于等待状态的任务重算1 / 2N和1 / N。
acquireMemory
acquireMemory为每个任务分配内存,返回实际分配的内存大小,如果不能分配内存,则返回0。这个方法在某些场景下会阻塞任务直到获取到足够的空闲内存(如当任务数量增多,而老任务已经占据大量内存时,新来的任务不能获取到至少1 / 2N的内存时),来保证每个任务都有机会获取到execution总内存的1 / 2N
private[memory] def acquireMemory(
numBytes: Long, taskAttemptId: Long, maybeGrowPool: Long => Unit = (additionalSpaceNeeded: Long) => Unit, computeMaxPoolSize: () => Long = () => poolSize): Long = lock.synchronized { assert(numBytes > 0, s"invalid number of bytes requested: $numBytes") // 如果memoryForTask中不包含当前任务,说明当前任务是新加入的,则唤醒等待的任务来重新计算maxMemoryPerTask // 和minMemoryPerTask if (!memoryForTask.contains(taskAttemptId)) { memoryForTask(taskAttemptId) = 0L lock.notifyAll() } // 保持循环直到任务已经获得到可获取的任务最大内存,或者当前有足够的内存分配给任务(可用内存大于任务最小内存) while (true) { val numActiveTasks = memoryForTask.keys.size val curMem = memoryForTask(taskAttemptId) // 首先从storage中释放足够的内存(直接获取storage空闲内存 || 收回之前storage借出的内存) maybeGrowPool(numBytes - memoryFree) // Maximum size the pool would have after potentially growing the pool. // This is used to compute the upper bound of how much memory each task can occupy. This // must take into account potential free memory as well as the amount this pool currently // occupies. Otherwise, we may run into SPARK-12155 where, in unified memory management, // we did not take into account space that could have been freed by evicting cached blocks. // 计算每个任务可使用的最大&最小内存 val maxPoolSize = computeMaxPoolSize() val maxMemoryPerTask = maxPoolSize / numActiveTasks val minMemoryPerTask = poolSize / (2 * numActiveTasks) // 理论上可以分配给当前任务的最大内存(min(申请内存数,任务可获得的内存数)) val maxToGrant = math.min(numBytes, math.max(0, maxMemoryPerTask - curMem)) // 实际可以分配给任务的内存(min(可分配最大内存数,当前剩余内存数)) val toGrant = math.min(maxToGrant, memoryFree) // 如果可以分配的内存<任务需要的内存 && 一共分配给任务的内存<任务最少可分配的内存,则阻塞任务,直到其他任务来释放内存 if (toGrant < numBytes && curMem + toGrant < minMemoryPerTask) { logInfo(s"TID $taskAttemptId waiting for at least 1/2N of $poolName pool to be free") lock.wait() } else { // 否则,返回实际分配给任务的内存 memoryForTask(taskAttemptId) += toGrant return toGrant } } 0L // Never reached } releaseMemory
releaseMemory方法用来释放给定的taskAttemptId的任务内存,释放的大小为numBytes。这个类会在最后调用notifyAll方法来唤醒等待内存的任务重新计算1 / 2N和1 / N。
def releaseMemory(numBytes: Long, taskAttemptId: Long): Unit = lock.synchronized { val curMem = memoryForTask.getOrElse(taskAttemptId, 0L) var memoryToFree = if (curMem < numBytes) { logWarning( s"Internal error: release called on $numBytes bytes but task only has $curMem bytes " + s"of memory from the $poolName pool") curMem } else { numBytes } if (memoryForTask.contains(taskAttemptId)) { memoryForTask(taskAttemptId) -= memoryToFree if (memoryForTask(taskAttemptId) <= 0) { memoryForTask.remove(taskAttemptId) } } lock.notifyAll() // Notify waiters in acquireMemory() that memory has been freed } StorageMemoryPool
用来记录被用来存储(缓存)的内存大小的内存池。分为堆内和堆外存储模式,主要对外提供了申请和释放内存的方法(acquireMemory,releaseMemory,freeSpaceToShrinkPool),需要注意的是这个类只作为内存记账,只是记录内存的使用情况,而不实际分配和释放物理内存。由于StorageMemoryPool中的内存相关的参数可被多个线程同时访问进行加减,所以StorageMemoryPool中涉及内存操作的方法都是同步方法。
acquireMemory
acquireMemory用来为缓存block提供内存空间,当Pool中的内存不足时,需要首先释放部分空间。
/**
* @param blockId
* @param numBytesToAcquire 需要保存的block的大小
* @param numBytesToFree StorageMemoryPool需要释放的空间大小(现有的剩余存储空间不足)
* @return 是否足够提供numBytesToAcquire的内存空间
*/
def acquireMemory(
blockId: BlockId, numBytesToAcquire: Long, numBytesToFree: Long): Boolean = lock.synchronized { assert(numBytesToAcquire >= 0) assert(numBytesToFree >= 0) assert(memoryUsed <= poolSize) // 如果当前Pool的内存空间不足,需要释放numBytesToFree的空间才能放下block if (numBytesToFree > 0) { memoryStore.evictBlocksToFreeSpace(Some(blockId), numBytesToFree, memoryMode) } // 判断现有剩余内存是否大于等于申请的内存空间 val enoughMemory = numBytesToAcquire <= memoryFree if (enoughMemory) { _memoryUsed += numBytesToAcquire } enoughMemory } releaseMemory
releaseMemory用来释放Pool的内存,这个方法只是简单的进行内存数字上的加减,不实际释放空间。
def releaseMemory(size: Long): Unit = lock.synchronized { if (size > _memoryUsed) { logWarning(s"Attempted to release $size bytes of storage " + s"memory when we only have ${_memoryUsed} bytes") _memoryUsed = 0 } else { _memoryUsed -= size } } freeSpaceToShrinkPool
freeSpaceToShrinkPool方法用来缩小StorageMemoryPool的大小,作为Spark的ExecutionMemoryPool和StorageMemoryPool动态调整大小的支撑。首先判断StorageMemoryPool是否有足够的空间可以释放,如果剩余空间不足需要释放的空间,则调用memoryStore.evictBlocksToFreeSpace来释放空间,最后返回StorageMemoryPool可释放空间大小。
def freeSpaceToShrinkPool(spaceToFree: Long): Long = lock.synchronized { val spaceFreedByReleasingUnusedMemory = math.min(spaceToFree, memoryFree) val remainingSpaceToFree = spaceToFree - spaceFreedByReleasingUnusedMemory if (remainingSpaceToFree > 0) { // If reclaiming free memory did not adequately shrink the pool, begin evicting blocks: val spaceFreedByEviction = memoryStore.evictBlocksToFreeSpace(None, remainingSpaceToFree, memoryMode) // When a block is released, BlockManager.dropFromMemory() calls releaseMemory(), so we do // not need to decrement _memoryUsed here. However, we do need to decrement the pool size. spaceFreedByReleasingUnusedMemory + spaceFreedByEviction } else { spaceFreedByReleasingUnusedMemory } } MemoryManger
MemoryManager是管理execution内存和storage内存的抽象类。其中execution内存主要被任务使用,用来进行计算、转换等操作,如shuffle,join,排序,聚合等。storage内存被BlockManager所使用,用来保存block数据。每一个JVM只有一个MemoryManager。MemoryManager提供了获取和释放execution内存和storage内存的方法
Spark提供了两种内存模型,即堆内内存和堆外内存。堆内内存即使用JVM来管理内存,堆外内存则直接调用java的Unsafe方法,直接对内存进行存取,从而避免了GC并节省了内存空间。
UnifiedMemoryManager
MemoryManager有两个实现类:StaticMemoryManager和UnifiedMemoryManager。其中StaticMemoryManager是1.6之前的内存管理类,他的execution内存和storage内存是固定的不能动态调整。而UnifiedMemoryManager是新的内存管理类,execution内存和storage内存可以相互借用,动态调整。
execution和storage共享内存的大小设置为(JVM总内存-300MB)* spark.memory.fraction (default 0.6),其中storage默认的大小为spark.memory.storageFraction (default 0.5)。也就是说,storage大小默认是JVM堆空间的0.3。storage可以无限制的借用execution未使用的内存空间,直到execution需要的内存不够时。当execution内存不够需要回收storage之前借用的内存时,storage被缓存的块会被从内存移到磁盘上,释放之前借用的execution的内存。同样的,execution也可以无限制的借用storage未使用的内存空间。但是execution已借用的内存不会被storage收回。
getMaxMemory
getMaxMemory方法用来获取MemoryManager管理的execution和storage共享内存的最大值。计算方式为:首先系统默认保留有300MB的内存空间,其次操作系统的总内存不能小于默认保留内存的1.5倍,记为最小系统内存。再次如果设置了spark.execution.memory,则大小不能小于最小系统内存。最终execution和storage的共享内存为
$$ 可用内存 = (系统内存-保留内存) * spark.memory.fraction
$$
private def getMaxMemory(conf: SparkConf): Long = { // 系统内存 val systemMemory = conf.getLong("spark.testing.memory", Runtime.getRuntime.maxMemory) // 保留内存(默认300MB) val reservedMemory = conf.getLong("spark.testing.reservedMemory", if (conf.contains("spark.testing")) 0 else RESERVED_SYSTEM_MEMORY_BYTES) // 最小系统内存为保留内存的1.5倍 val minSystemMemory = (reservedMemory * 1.5).ceil.toLong if (systemMemory < minSystemMemory) { throw new IllegalArgumentException(s"System memory $systemMemory must " + s"be at least $minSystemMemory. Please increase heap size using the --driver-memory " + s"option or spark.driver.memory in Spark configuration.") } // executor设置的内存不能小于最小系统内存 if (conf.contains("spark.executor.memory")) { val executorMemory = conf.getSizeAsBytes("spark.executor.memory") if (executorMemory < minSystemMemory) { throw new IllegalArgumentException(s"Executor memory $executorMemory must be at least " + s"$minSystemMemory. Please increase executor memory using the " + s"--executor-memory option or spark.executor.memory in Spark configuration.") } } // 最大可用内存为(系统内存-保留内存)*(execution&storage所占百分比) val usableMemory = systemMemory - reservedMemory val memoryFraction = conf.getDouble("spark.memory.fraction", 0.6) (usableMemory * memoryFraction).toLong } acquireExecutionMemory
用来申请execution内存。execution最大内存=execution和storage共享内存最大值-min(storage已使用内存, storage初始大小)。即execution可以使用storage中的全部剩余内存,而且还可以收回之前借给storage的属于execution的内存。
override private[memory] def acquireExecutionMemory( numBytes: Long, taskAttemptId: Long, memoryMode: MemoryMode): Long = synchronized { assertInvariants() assert(numBytes >= 0) val (executionPool, storagePool, storageRegionSize, maxMemory) = memoryMode match { case MemoryMode.ON_HEAP => ( onHeapExecutionMemoryPool, onHeapStorageMemoryPool, onHeapStorageRegionSize, maxHeapMemory) case MemoryMode.OFF_HEAP => ( offHeapExecutionMemoryPool, offHeapStorageMemoryPool, offHeapStorageMemory, maxOffHeapMemory) } /** * 通过移除缓存的块来增大execution pool的内存,这会减少storage pool的内存 */ def maybeGrowExecutionPool(extraMemoryNeeded: Long): Unit = { if (extraMemoryNeeded > 0) { val memoryReclaimableFromStorage = math.max( storagePool.memoryFree, storagePool.poolSize - storageRegionSize) if (memoryReclaimableFromStorage > 0) { // 调用storagePool.freeSpaceToShrinkPool来释放storage占用的内存 val spaceToReclaim = storagePool.freeSpaceToShrinkPool( math.min(extraMemoryNeeded, memoryReclaimableFromStorage)) storagePool.decrementPoolSize(spaceToReclaim) executionPool.incrementPoolSize(spaceToReclaim) } } } /** * execution可用的最大内存(execution可以使用storage中全部的剩余内存,而且还可以收回storage * 之前借出的属于execution的内存) */ def computeMaxExecutionPoolSize(): Long = { maxMemory - math.min(storagePool.memoryUsed, storageRegionSize) } executionPool.acquireMemory( numBytes, taskAttemptId, maybeGrowExecutionPool, computeMaxExecutionPoolSize) } acquireStorageMemory
用来申请storage内存方法。如果storage内存不足,则可以从execution的空闲内存中借用部分,如果在借用了内存后storage的可用内存仍然不满足申请的内存大小,则将storage上的块刷新到磁盘上来释放内存。
override def acquireStorageMemory(
blockId: BlockId, numBytes: Long, memoryMode: MemoryMode): Boolean = synchronized { assertInvariants() assert(numBytes >= 0) val (executionPool, storagePool, maxMemory) = memoryMode match { case MemoryMode.ON_HEAP => ( onHeapExecutionMemoryPool, onHeapStorageMemoryPool, maxOnHeapStorageMemory) case MemoryMode.OFF_HEAP => ( offHeapExecutionMemoryPool, offHeapStorageMemoryPool, maxOffHeapMemory) } // 如果请求的内存大于最大内存直接返回 if (numBytes > maxMemory) { // Fail fast if the block simply won't fit logInfo(s"Will not store $blockId as the required space ($numBytes bytes) exceeds our " + s"memory limit ($maxMemory bytes)") return false } // 如果请求的内存大于storage现有剩余内存,则从execution的空闲内存中借用 if (numBytes > storagePool.memoryFree) { val memoryBorrowedFromExecution = Math.min(executionPool.memoryFree, numBytes) executionPool.decrementPoolSize(memoryBorrowedFromExecution) storagePool.incrementPoolSize(memoryBorrowedFromExecution) } // 这里调用方法,如果空闲内存还是不够,需要将storage上的块刷新到磁盘上,来释放足够的内存 storagePool.acquireMemory(blockId, numBytes) } MemoryStore(core/scala/org.apache.spark.storage/memory)
MemoryStore是Spark申请storage内存的类,用来将数据块保存到申请的storage内存中,并提供了从内存/磁盘获取保存的数据的方法。在storage内存不足时,负责将内存中保存的数据刷新到磁盘上并释放占用的内存。MemoryStore在保存数据之前,会调用MemoryManager的相关acquire方法,判断StorageMemoryPool中是否有足够的内存可以分配,如果可用内存不足则直接返回false,由调用者调用BlockEvictionHandler.dropFromMemory来移除内存中缓存的数据块,释放内存空间。如果可用内存充足则直接将数据块保存到内存中。
putBytes
用来将数据以序列化的方式保存。首先通过MemoryManager从StorageMemoryPool中获取到足够的内存空间,然后将数据封装为SerializedMemoryEntry保存到内存中,并建立blockId到内存地址的映射,便于查找。
def putBytes[T: ClassTag]( blockId: BlockId, size: Long, memoryMode: MemoryMode, _bytes: () => ChunkedByteBuffer): Boolean = { require(!contains(blockId), s"Block $blockId is already present in the MemoryStore") // 这里判断是否有足够的内存,如果不够会最终调用BlockEvictionHandler里面的方法将内存中 // 的内容刷新到磁盘上,释放内存空间 if (memoryManager.acquireStorageMemory(blockId, size, memoryMode)) { // We acquired enough memory for the block, so go ahead and put it val bytes = _bytes() assert(bytes.size == size) // 创建memoryEntry并放到map中管理 val entry = new SerializedMemoryEntry[T](bytes, memoryMode, implicitly[ClassTag[T]]) entries.synchronized { entries.put(blockId, entry) } logInfo("Block %s stored as bytes in memory (estimated size %s, free %s)".format( blockId, Utils.bytesToString(size), Utils.bytesToString(maxMemory - blocksMemoryUsed))) true } else { false } putIteratorAsBytes
尝试将给定的非序列化块以非序列化的形式保存到内存中。为了防止由于放入的数据块过大导致的内存溢出,这个方法在遍历块中数据时,定期的检测是否还有足够的unroll内存,如果不足则向storage申请内存(这个过程不会真正保存数据,只是保存数据的预估大小)。如果最终计算出数据块的大小可以保存到内存中,则表明storage内存充足,直接从storage中扣除这部分内存数值,然后这时才真正将数据块保存到内存中,这个方法在真正保存内存之前都是内存数值的计算,并不会真正申请内存,所以这个方法不会申请比实际需要内存更多的内存来存储块。
private[storage] def putIteratorAsValues[T]( blockId: BlockId, values: Iterator[T], classTag: ClassTag[T]): Either[PartiallyUnrolledIterator[T], Long] = { require(!contains(blockId), s"Block $blockId is already present in the MemoryStore") var elementsUnrolled = 0 var keepUnrolling = true val initialMemoryThreshold = unrollMemoryThreshold val memoryCheckPeriod = 16 // 当前任务保留的为展开操作的内存 var memoryThreshold = initialMemoryThreshold val memoryGrowthFactor = 1.5 var unrollMemoryUsedByThisBlock = 0L var vector = new SizeTrackingVector[T]()(classTag) keepUnrolling = reserveUnrollMemoryForThisTask(blockId, initialMemoryThreshold, MemoryMode.ON_HEAP) // 如果成功从storage memory中获取展开的内存,则更新当前任务使用的展开内存大小 if (!keepUnrolling) { logWarning(s"Failed to reserve initial memory threshold of " + s"${Utils.bytesToString(initialMemoryThreshold)} for computing block $blockId in memory.") } else { unrollMemoryUsedByThisBlock += initialMemoryThreshold } while (values.hasNext && keepUnrolling) { vector += values.next() // 每读取memoryCheckPeriod个元素后,检查一下内存是否足够 if (elementsUnrolled % memoryCheckPeriod == 0) { // 如果当前读入的数据预估大小超过了展开内存的大小,则扩容 val currentSize = vector.estimateSize() if (currentSize >= memoryThreshold) { // 一次多申请一些空间 val amountToRequest = (currentSize * memoryGrowthFactor - memoryThreshold).toLong // 尝试再申请amountToRequest大小的空间 keepUnrolling = reserveUnrollMemoryForThisTask(blockId, amountToRequest, MemoryMode.ON_HEAP) // 申请成功则更新使用的展开内存总量,如果失败则退出循环 if (keepUnrolling) { unrollMemoryUsedByThisBlock += amountToRequest } // 不论申请是否成功都更新memoryThreshold memoryThreshold += amountToRequest } } elementsUnrolled += 1 } // 到这如果keepUnrolling还是true,则说明成功分配了所有的unroll需要的内存 if (keepUnrolling) { val arrayValues = vector.toArray vector = null // 将values包装成memoryEntry val entry = new DeserializedMemoryEntry[T](arrayValues, SizeEstimator.estimate(arrayValues), classTag) val size = entry.size def transferUnrollToStorage(amount: Long): Unit = { memoryManager.synchronized { // 释放unroll内存 releaseUnrollMemoryForThisTask(MemoryMode.ON_HEAP, amount) // 申请storage 内存 val success = memoryManager.acquireStorageMemory(blockId, amount, MemoryMode.ON_HEAP) assert(success, "transferring unroll memory to storage memory failed") } } // Acquire storage memory if necessary to store this block in memory. val enoughStorageMemory = { // 如果展开的内存小于values实际的大小(这是因为上面的while循环取得都是预估的大小) if (unrollMemoryUsedByThisBlock <= size) { // 再申请额外的内存 val acquiredExtra = memoryManager.acquireStorageMemory( blockId, size - unrollMemoryUsedByThisBlock, MemoryMode.ON_HEAP) // 将unroll的内存数据迁移到storage内存上 if (acquiredExtra) { transferUnrollToStorage(unrollMemoryUsedByThisBlock) } acquiredExtra } else { // unrollMemoryUsedByThisBlock > size // If this task attempt already owns more unroll memory than is necessary to store the // block, then release the extra memory that will not be used. // 如果unroll的内存大于values的大小,则释放多余的内存 val excessUnrollMemory = unrollMemoryUsedByThisBlock - size releaseUnrollMemoryForThisTask(MemoryMode.ON_HEAP, excessUnrollMemory) transferUnrollToStorage(size) true } } // 如果将unroll的内存成功迁移到storage,则将memoryEntry放入entries中 if (enoughStorageMemory) { entries.synchronized { entries.put(blockId, entry) } logInfo("Block %s stored as values in memory (estimated size %s, free %s)".format( blockId, Utils.bytesToString(size), Utils.bytesToString(maxMemory - blocksMemoryUsed))) Right(size) } else { assert(currentUnrollMemoryForThisTask >= currentUnrollMemoryForThisTask, "released too much unroll memory") Left(new PartiallyUnrolledIterator( this, unrollMemoryUsedByThisBlock, unrolled = arrayValues.toIterator, rest = Iterator.empty)) } } else { // 如果没有获取到足够的unroll 内存,则报错,并返回PariallyUnrolledIterator // We ran out of space while unrolling the values for this block logUnrollFailureMessage(blockId, vector.estimateSize()) Left(new PartiallyUnrolledIterator( this, unrollMemoryUsedByThisBlock, unrolled = vector.iterator, rest = values)) } } evictBlocksToFreeSpace
当storage内存不足时,会调用evictBlocksToFreeSpace方法来移除内存中的块释放内存空间。如果在释放空间之后,申请存储的块的大小还是大于内存大小或者申请存储的块与移除的块属于同一个RDD,则移除失败。
private[spark] def evictBlocksToFreeSpace(
blockId: Option[BlockId], space: Long, memoryMode: MemoryMode): Long = { assert(space > 0) memoryManager.synchronized { var freedMemory = 0L val rddToAdd = blockId.flatMap(getRddId) // 保存需要移除的块 val selectedBlocks = new ArrayBuffer[BlockId] // 判断block是否可以被移除: // block内存模式==传入的内存模式 && block所属的rdd != 传入block所属的rdd def blockIsEvictable(blockId: BlockId, entry: MemoryEntry[_]): Boolean = { entry.memoryMode == memoryMode && (rddToAdd.isEmpty || rddToAdd != getRddId(blockId)) } entries.synchronized { val iterator = entries.entrySet().iterator() // 如果申请的空间大于内存可用空间,并且entries里面还有块, // 则尝试将entries中的块移除来释放内存空间 while (freedMemory < space && iterator.hasNext) { val pair = iterator.next() val blockId = pair.getKey val entry = pair.getValue // 判断当前entry的块是否可以被移除: // 块的内存模式与申请的内存模式相同 && 块所在rdd != 申请块所在rdd if (blockIsEvictable(blockId, entry)) { // 为防止移除正在读的块,这里需要加写锁,lockForWriting方法为非阻塞方法,如果获取不到 // 写锁,则直接跳过 if (blockInfoManager.lockForWriting(blockId, blocking = false).isDefined) { selectedBlocks += blockId freedMemory += pair.getValue.size } } } } // 删除内存中的块 def dropBlock[T](blockId: BlockId, entry: MemoryEntry[T]): Unit = { val data = entry match { case DeserializedMemoryEntry(values, _, _) => Left(values) case SerializedMemoryEntry(buffer, _, _) => Right(buffer) } // 调用blockEvictionHandler移除内存块(刷磁盘,最终调用remove方法删entries) val newEffectiveStorageLevel = blockEvictionHandler.dropFromMemory(blockId, () => data)(entry.classTag) if (newEffectiveStorageLevel.isValid) { blockInfoManager.unlock(blockId) } else { blockInfoManager.removeBlock(blockId) } } // 如果最终有足够的空间 if (freedMemory >= space) { logInfo(s"${selectedBlocks.size} blocks selected for dropping " + s"(${Utils.bytesToString(freedMemory)} bytes)") for (blockId <- selectedBlocks) { // 遍历删除选中要移除的内存块 val entry = entries.synchronized { entries.get(blockId) } if (entry != null) { dropBlock(blockId, entry) } } logInfo(s"After dropping ${selectedBlocks.size} blocks, " + s"free memory is ${Utils.bytesToString(maxMemory - blocksMemoryUsed)}") freedMemory } else { blockId.foreach { id => logInfo(s"Will not store $id") } selectedBlocks.foreach { id => blockInfoManager.unlock(id) } 0L } } } tungsten(common/unsafe/java/org.apache.spark.unsafe.memory)
Spark的内存模式称为tungsten,统一管理堆内内存分配和堆外内存分配两种内存分配方式,负责内存的实际分配和回收,以及内存的访问寻址。虽然storageMemoryPool也包括了堆外内存方式,但是好像storage只用到了堆内内存存储(保存到storage内存的数据只是封装为MemoryEntry直接保存到LinkedHashMap中)。tungsten的内存管理模式只是在execution内存使用时用到,即任务相关的内存申请可以使用堆外或堆内内存。
对于堆外内存来说,由于是Spark直接对物理内存进行管理(申请/释放),内存的偏移地址就是数据实际存储地址,所以可以直接用指向内存地址的指针来访问数据。而对于堆内存储来说,由于内存管理是交由JVM管理的,而由于GC,对象的存储地址会发生变化,所以不能直接将数据的物理地址保存到指针中来访问。
Spark的tungsten内存管理机制使用了类似于操作系统的页和页内偏移量的方式来统一管理堆内和堆外内存地址,由页来保存逻辑地址到物理地址的映射。tungsten将物理内存分为一系列的页来管理,页内的数据具体再通过页内偏移量来实际访问。tungsten使用一个64 bits的long型来代表数据的内存地址。long型的高13位为页码,即tungsten最多支持8192个页,long型的低51位为页内偏移量。访问内存数据流程:首先根据tungsten的long型内存地址解析出页号和页内偏移量,然后根据页号获取到对应页的物理地址,则数据的实际物理地址为页物理地址+页内偏移量(这里说的逻辑和物理地址是在应用层面上进行的又一次抽象,不同于操作系统的逻辑和物理地址,但是思想是一致的)。流程图如下:
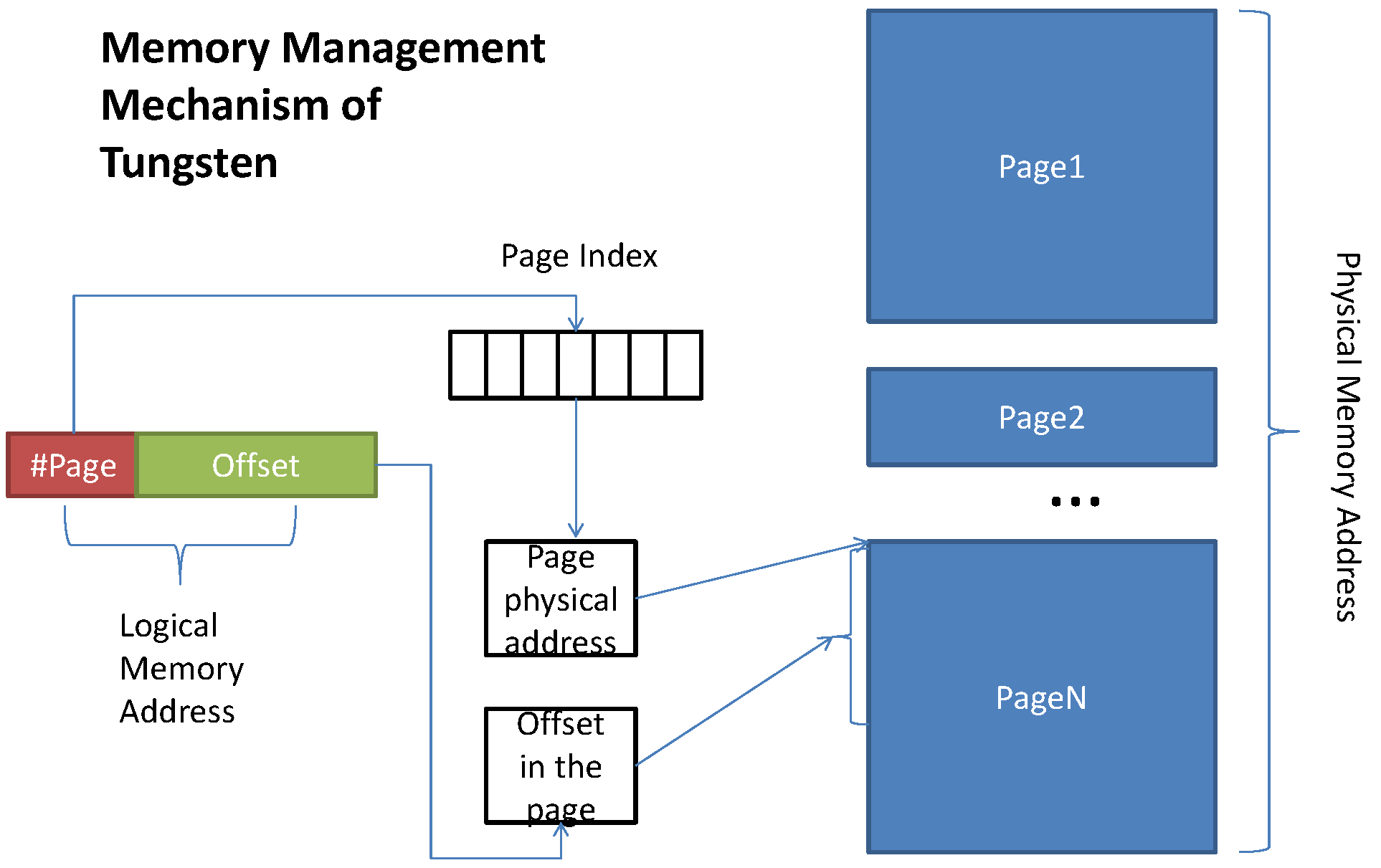
对于堆内和堆外模式来说,逻辑地址是一致的,而物理地址是不同的。对于堆外模式来说,物理地址直接由一个64 bits的绝对内存地址来表示,对于堆内模式来说,物理地址由相对于JVM对象的偏移量来表示。为了统一这两个内存模式,tungsten使用MemoryLocation来表示堆内和堆外的内存地址。
MemoryLocation
MemoryLocation来表示堆内和堆外的物理内存地址。对于堆内模式来说,obj是JVM对象的基地址,offset是相对于obj的偏移量(默认为0),对于堆外模式来说,obj为空,offset为绝对内存地址。
public class MemoryLocation {
// 堆内内存标记内存的地址
@Nullable Object obj; // 堆外内存标记内存的地址 long offset; public MemoryLocation(@Nullable Object obj, long offset) { this.obj = obj; this.offset = offset; } public MemoryLocation() { this(null, 0); } public void setObjAndOffset(Object newObj, long newOffset) { this.obj = newObj; this.offset = newOffset; } public final Object getBaseObject() { return obj; } public final long getBaseOffset() { return offset; } } MemoryBlock
MemoryBlock是MemoryLocation的子类,用来表示tungsten中的内存。其中增加了记录内存大小的length和记录内存对应页号的pageNumber变量。
public class MemoryBlock extends MemoryLocation { private final long length; public int pageNumber = -1; public MemoryBlock(@Nullable Object obj, long offset, long length) { super(obj, offset); this.length = length; } public long size() { return length; } public static MemoryBlock fromLongArray(final long[] array) { return new MemoryBlock(array, Platform.LONG_ARRAY_OFFSET, array.length * 8L); } } MemoryAllocator
tungsten实际的内存分配和回收由MemoryAllocator接口的实现类完成。MemoryAllocator有两个实现类:HeapMemoryAllocator和UnsafeMemoryAllocator,分别负责堆内模式和堆外模式的内存分配和回收。MemoryAllocator有两个接口allocate和free来实现内存的分配和回收。
HeapMemoryAllocator
HeapMemoryAllocator负责堆内内存模式的内存分配和回收,具体来说new一个long型数组来实现内存的分配,而由于JVM是自动进行内存回收的,所以HeapMemoryAllocator的free方法不负责内存的回收。HeapMemoryAllocator在实现时,针对大内存的分配和回收进行了优化,会将回收的大内存直接缓存在map中,之后如果再有申请相同大小的内存的请求时,直接返回缓存中的内存而不用每次都new一个对象,从而减少GC。
// 内存缓存
private final Map<Long, LinkedList<WeakReference<MemoryBlock>>> bufferPoolsBySize = new HashMap<>(); public MemoryBlock allocate(long size) throws OutOfMemoryError { // 如果需要启用缓存机制 if (shouldPool(size)) { // 则从缓存池中找到第一个可用的内存块,直接返回 synchronized (this) { final LinkedList<WeakReference<MemoryBlock>> pool = bufferPoolsBySize.get(size); if (pool != null) { while (!pool.isEmpty()) { final WeakReference<MemoryBlock> blockReference = pool.pop(); final MemoryBlock memory = blockReference.get(); if (memory != null) { assert (memory.size() == size); return memory; } } bufferPoolsBySize.remove(size); } } } // 申请一个size+7/8大小的long数组 long[] array = new long[(int) ((size + 7) / 8)]; // 将数组的起始位置,作为占位用的使用堆外内存的offset(这里是0),和偏移量传入MemoryBlock return new MemoryBlock(array, Platform.LONG_ARRAY_OFFSET, size); } public void free(MemoryBlock memory) { final long size = memory.size(); // 是否需要启用缓存机制 if (shouldPool(size)) { // 将当前释放的内存块缓存起来,以便下次申请同样大小的内存时直接返回 synchronized (this) { LinkedList<WeakReference<MemoryBlock>> pool = bufferPoolsBySize.get(size); if (pool == null) { pool = new LinkedList<>(); bufferPoolsBySize.put(size, pool); } pool.add(new WeakReference<>(memory)); } } else { // Do nothing } } UnsafeMemoryAllocator
UnsafeMemoryAllocator负责堆外模式的内存分配和回收,直接调用java Unsafe包的方法直接对内存进行申请和释放操作。
@Override
public MemoryBlock allocate(long size) throws OutOfMemoryError {
long address = Platform.allocateMemory(size); return new MemoryBlock(null, address, size); } @Override public void free(MemoryBlock memory) { assert (memory.obj == null) : "baseObject not null; are you trying to use the off-heap allocator to free on-heap memory?"; Platform.freeMemory(memory.offset); } execution memory分配(core/java/org.apache.spark.memory)
TaskMemoryManager
TaskMemoryManager管理每个任务的内存使用,在其中维护了任务可用所有内存页,已分配的内存页,任务中的consumers等。主要用来实现execution内存的分配,回收,tungsten地址到实际内存地址映射的转换。
acquireExecutionMemory
为指定的consumer分配N bytes的内存,如果内存不足,则会调用consumer的spill方法来释放内存。这个方法不真正分配内存,只是进行内存数值的加减(实际调用ExecutionMemoryPool)执行流程如下:
- 首先从execution memory获取当前任务的内存,如果内存充足则到3(可能触发将内存块刷到磁盘)
- 如果内存不足,尝试从其他consumer那释放内存(调用consumer的spill方法,将consumer占用的内存刷新到磁盘),如果内存满足条件,则到3
- 如果内存还是不足,尝试从自身释放部分内存,最终返回分配给consumer的内存大小
public long acquireExecutionMemory(long required, MemoryConsumer consumer) {
assert(required >= 0);
assert(consumer != null);
MemoryMode mode = consumer.getMode();
synchronized (this) { long got = memoryManager.acquireExecutionMemory(required, taskAttemptId, mode); // 如果内存不足,且存在调用过spill的consumer,首先尝试从这些consumer中释放一些内存 if (got < required) { for (MemoryConsumer c: consumers) { if (c != consumer && c.getUsed() > 0 && c.getMode() == mode) { try { // 释放内存 long released = c.spill(required - got, consumer); if (released > 0) { logger.debug("Task {} released {} from {} for {}", taskAttemptId, Utils.bytesToString(released), c, consumer); // 重新向execution memory申请required - got内存 got += memoryManager.acquireExecutionMemory(required - got, taskAttemptId, mode); // 如果获取到足够内存,则直接返回 if (got >= required) { break; } } } catch (IOException e) { logger.error("error while calling spill() on " + c, e); throw new OutOfMemoryError("error while calling spill() on " + c + " : " + e.getMessage()); } } } } // 如果没有consumer || 已有的spill consumer释放的内存不足,则尝试释放自己占用的内存 if (got < required) { try { long released = consumer.spill(required - got, consumer); if (released > 0) { logger.debug("Task {} released {} from itself ({})", taskAttemptId, Utils.bytesToString(released), consumer); got += memoryManager.acquireExecutionMemory(required - got, taskAttemptId, mode); } } catch (IOException e) { logger.error("error while calling spill() on " + consumer, e); throw new OutOfMemoryError("error while calling spill() on " + consumer + " : " + e.getMessage()); } } consumers.add(consumer); logger.debug("Task {} acquired {} for {}", taskAttemptId, Utils.bytesToString(got), consumer); return got; } } allocatePage
由MemoryConsumer调用来申请内存页,流程如下:
-
调用acquireExecutionMemory获取内存
-
分配一个pageNumber
-
调用allocate方法实际分配内存(堆内直接new一个acquired大小的数组,堆外直接手动申请内存,并包装为
MemoryBlock)
-
设置pageTable[pageNumber]=page,并返回包装好的MemoryBlock
public MemoryBlock allocatePage(long size, MemoryConsumer consumer) {
assert(consumer != null);
assert(consumer.getMode() == tungstenMemoryMode);
if (size > MAXIMUM_PAGE_SIZE_BYTES) { throw new IllegalArgumentException( "Cannot allocate a page with more than " + MAXIMUM_PAGE_SIZE_BYTES + " bytes"); } long acquired = acquireExecutionMemory(size, consumer); if (acquired <= 0) { return null; } final int pageNumber; synchronized (this) { // 获取可用的页号 pageNumber = allocatedPages.nextClearBit(0); if (pageNumber >= PAGE_TABLE_SIZE) { releaseExecutionMemory(acquired, consumer); throw new IllegalStateException( "Have already allocated a maximum of " + PAGE_TABLE_SIZE + " pages"); } allocatedPages.set(pageNumber); } MemoryBlock page = null; try { // 实际申请内存,封装成MemoryBlock返回 page = memoryManager.tungstenMemoryAllocator().allocate(acquired); } catch (OutOfMemoryError e) { logger.warn("Failed to allocate a page ({} bytes), try again.", acquired); synchronized (this) { acquiredButNotUsed += acquired; allocatedPages.clear(pageNumber); } return allocatePage(size, consumer); } page.pageNumber = pageNumber; pageTable[pageNumber] = page; if (logger.isTraceEnabled()) { logger.trace("Allocate page number {} ({} bytes)", pageNumber, acquired); } return page; } freePage
释放内存块流程:
- 将page table 设为null
- 清除allocatePage对应的pageNumber
- 清除申请的内存(堆外模式需要手动清除,堆内模式无需做,因为已经没有引用memoryBlock的地方了,会被gc回收)
- 重置execution memory(简单的将当前任务使用的内存减去,并执行notifyAll方法,唤醒其他由于没有获得最少内存而被阻塞的线程)
public void freePage(MemoryBlock page, MemoryConsumer consumer) {
assert (page.pageNumber != -1) :
"Called freePage() on memory that wasn't allocated with allocatePage()";
assert(allocatedPages.get(page.pageNumber));
pageTable[page.pageNumber] = null; synchronized (this) { allocatedPages.clear(page.pageNumber); } if (logger.isTraceEnabled()) { logger.trace("Freed page number {} ({} bytes)", page.pageNumber, page.size()); } long pageSize = page.size(); memoryManager.tungstenMemoryAllocator().free(page); releaseExecutionMemory(pageSize, consumer); } 地址转换
TaskMemoryManager提供了物理地址和逻辑地址的相互转换
public long encodePageNumberAndOffset(MemoryBlock page, long offsetInPage) {
if (tungstenMemoryMode == MemoryMode.OFF_HEAP) {
// 在堆外内存模式中,offset就是绝对内存地址,这里转换成页内的相对地址,保证offset在51bits之内 offsetInPage -= page.getBaseOffset(); } return encodePageNumberAndOffset(page.pageNumber, offsetInPage); } @VisibleForTesting public static long encodePageNumberAndOffset(int pageNumber, long offsetInPage) { assert (pageNumber != -1














 1517
1517


 到【灌水乐园】发言
到【灌水乐园】发言








