






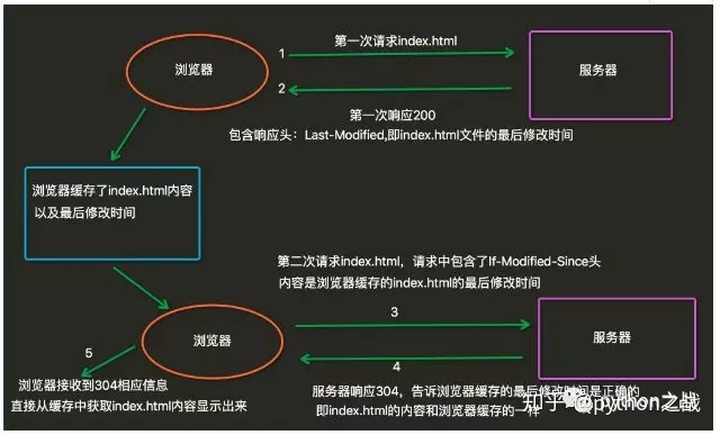
机器之间的协议就是机器通信的语法,只有按照这种语法发来的信息,机器之间才能相互理解内容,也可以理解为信息的一种格式。
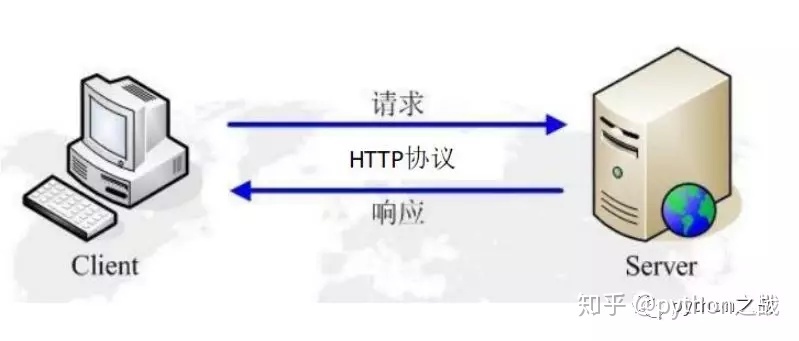
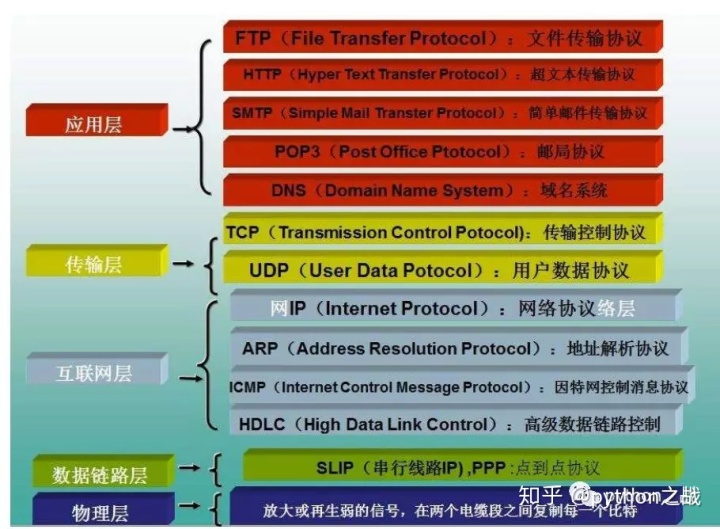
HTTP/IP协议是互联网最为重要的协议,没有HTTP/IP协议,也就没有互联跟不会有网,对于爬虫而言一切数据、请求都是围绕HTTP协议展开。
但是在python实现的网络爬虫中都是使用封装好了的请求库如:requests、scrapy、urllib等,这些是对socket的封装,而socket是除了机器语言外最底层的协议。
HTTP是公认的协议,但是并不是所有的终端通信都使用HTTP协议,也有处于保密需求而自定义协议,我们要通过对HTTP协议的分析理解来认来掌握自定义协议的分析思路。
在浏览器开发者模式下,任意截获一个数据包点击view parsed,显示出来的就是原始的HTTP请求头格式及协议请求头格式。
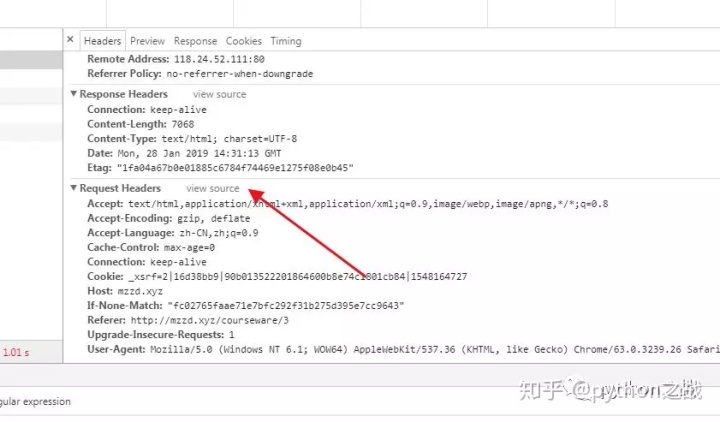
最主要的头两行分析如下,第一行:
GET / HTTP/1.1 分别是请求方式 请求路径 协议及其版本/就表示首页,最后的HTTP/1.1指示采用的HTTP协议版本是1.1
从第二行开始,每一行都类似于Xxx: abcdefg:
Host: mzzd.xyz表示请求的域名是mzzd.xyz,如果一台服务器有多个网站,服务器就需要通过Host来区分浏览器请求的是哪个网站。
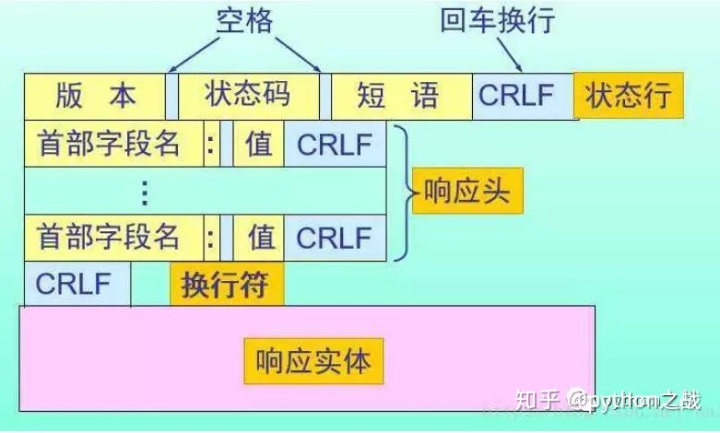
再看HTTP响应及其格式:
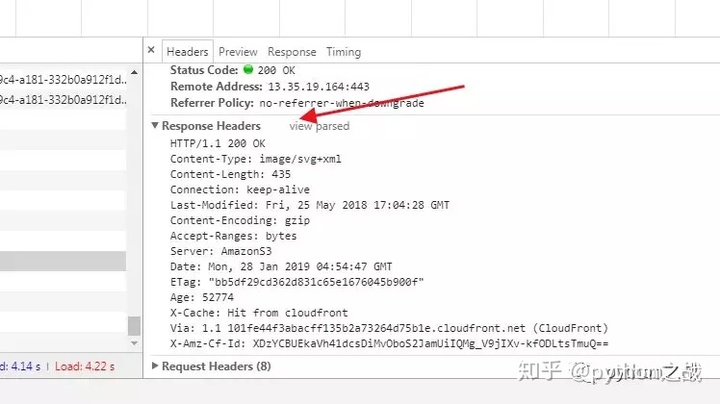
HTTP响应分为Header和Body两部分(Body是可选项),我们在Network中看到的Header最重要的几行如下:
HTTP/1.1 200 OK 分别是协议版本 状态码 说明200表示一个成功的响应,后面的OK是说明。
Content-Type: text/htmlContent-Type指示响应的内容,浏览器依靠Content-Type来判断响应的内容类型,即使URL是http://www.mzzd.xyz/1.jpg,它也不一定就是图片。
HTTP GET请求的格式:
GET /path HTTP/1.1
Header1: Value1
Header2: Value2
Header3: Value3
每个Header一行一个,换行符是rn。
HTTP POST请求的格式:
POST /path HTTP/1.1
Header1: Value1
Header2: Value2
Header3: Value3
body data goes here...
当遇到连续两个rn时,Header部分结束,后面的数据全部是Body。
HTTP响应的格式:
200 OK
Header1: Value1
Header2: Value2
Header3: Value3
body data goes here...
HTTP响应如果包含body,也是通过rnrn来分隔的。
那我们用python实现HTTP客户端:
#coding=utf-8
import socket
from multiprocessing import Process
def handleClient(clientSocket):
'用一个新的进程,为一个客户端进行服务'
recvData = clientSocket.recv(2014)
requestHeaderLines = recvData.splitlines()
for line in requestHeaderLines:
print(line)
responseHeaderLines = "HTTP/1.1 200 OKrn" # 响应首行内容
responseHeaderLines += "rn" # 响应头与body之间应有一空行
responseBody = "hello world"
response = responseHeaderLines + responseBody
clientSocket.send(response)
clientSocket.close()
def main():
'作为程序的主控制入口'
serverSocket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
serverSocket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
serverSocket.bind(("", 7788))
serverSocket.listen(5)
while True:
clientSocket,clientAddr = serverSocket.accept()
clientP = Process(target = handleClient, args = (clientSocket,))
clientP.start()
clientSocket.close()
if __name__ == '__main__':
main()
这个客户端的作用就是当你在浏览器访问本地的8000端口,会向浏览器返回hello Word的字符。

说了这么多应该明白HTTP协议其实只是一段文本,只是文本首行是协议头,一空行之后是协议体,按照这种格式那么浏览器就能解析。
而自定义的协议常见于APP中,因为在APP中定义彼此通信的过程、定义通信中相关字段的含义,即使被抓包后那也很难解析,这种情况很少,因为有现成的协议何必去自己弄一套协议,但是遇到之后应该明白如何下手。
甚至可以开发自己基于socket的爬虫库。
------------------------------
ID:Python之战
|作|者|公(zhong)号:python之战
专注Python,专注于网络爬虫、RPA的学习-践行-总结
喜欢研究技术瓶颈并分享,欢迎围观,共同学习。
独学而无友,则孤陋而寡闻!
---------------------------















 1568
1568











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









