






大家都知道求任意两个集合的笛卡尔积一般是如下这种方式
#include <stdio.h>
#define m 3
#define n 2
int main() {
int i,j;
char a[m],b[n];
for (i=0;i<m;i++) scanf("%c",&a[i]);
getchar();//吃掉\n
for (j=0;j<n;j++) scanf("%c",&b[j]);
printf("集合a:\n");
for (i=0;i<m;i++) printf("%c\t",a[i]);
printf("\n集合b:\n");
for (j=0;j<n;j++) printf("%c\t",b[j]);
printf("\n{");
for (i=0;i<m;i++)
for (j=0;j<n;j++)
printf("<%c,%c> ",a[i],b[j]);
printf("}\n");
return 0;
}
例如输入两个集合“ABC”和“12”,结果如下
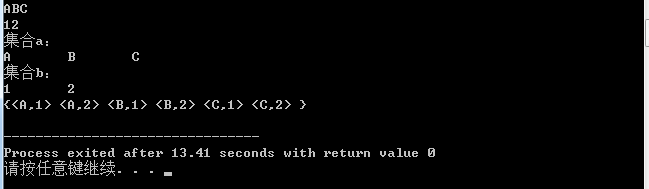
但是对于一个复杂字符串来说,例如"[A|B|C] D [E|F|G] [M|N]"(“[A|B|C]”代表一个集合,其他类是,集合中的元素用“|”隔开)这种形式的该怎么处理呢?
第一步,熟悉python的同学第一反应当然是利用split方法来处理喽,但是c++中没有split方法,但是提供了strtok函数来处理,方法如下
//分割字符串,spl代表分割规则
int StrSplit(char dst[][80], char* str, const char* spl)
{
int n = 0;
char *result = NULL;
result = strtok(str, spl);
while (result != NULL)
{
strcpy(dst[n++], result);
result = strtok(NULL, spl);
}
return n; //返回分割集合的个数
}具体调用如下
StrSplit(dst, StrToChArr(m), " ");//以空格分割接下来,最关键的方法就是求笛卡尔积了,我们使用STL中的vector来处理,方法如下
//求若干集合的笛卡尔积
string decare(const vector<vector<string>> &sets, string add)
{
vector<vector<string>> rs;
int n = sets.size();
vector<string> tmp;
string word, result;
for (int i = 0; i < n; ++i)
{
tmp.push_back(sets[i][0]);
}
rs.push_back(tmp);
for (int i = n - 1; i >= 0; --i)
{
int nRsSize = rs.size();
for ( int k = 1; k < sets[i].size(); ++k)
{
for ( int j = 0; j < nRsSize; ++j)
{
tmp = rs[j];
tmp[i] = sets[i][k];
rs.push_back(tmp);
}
}
}
for (vector<vector<string> >::iterator iter = rs.begin(); iter != rs.end(); iter++)
{
word += add;
for ( int i = 0; i < (*iter).size(); i++)
{
word += (*iter)[i] + " ";//词之间添加空格
}
if (iter != rs.end() - 1) {
word += "\n";//末尾不需要换行
}
else {
word += "";
}
}
return word;
}完整程序如下
#include"stdafx.h"
#include "fstream"
#include "vector"
#include "string"
#include "algorithm"
#include "regex"
#include "iterator"
#include "iostream"
#include "windows.h"
#include "wchar.h"
#include "io.h"
#include "stdlib.h"
#include "vector"
#include "set"
//#define TXT_NAME "word.xml"//保存合并后的xml结果
using namespace std;
//utf8转string
std::string UTF8_To_string(const std::string & str)
{
int nwLen = MultiByteToWideChar(CP_UTF8, 0, str.c_str(), -1, NULL, 0);
wchar_t * pwBuf = new wchar_t[nwLen + 1];
memset(pwBuf, 0, nwLen * 2 + 2);
MultiByteToWideChar(CP_UTF8, 0, str.c_str(), str.length(), pwBuf, nwLen);
int nLen = WideCharToMultiByte(CP_ACP, 0, pwBuf, -1, NULL, NULL, NULL, NULL);
char * pBuf = new char[nLen + 1];
memset(pBuf, 0, nLen + 1);
WideCharToMultiByte(CP_ACP, 0, pwBuf, nwLen, pBuf, nLen, NULL, NULL);
std::string retStr = pBuf;
delete[]pBuf;
delete[]pwBuf;
pBuf = NULL;
pwBuf = NULL;
return retStr;
}
//分隔字符串
int StrSplit(char dst[][80], char* str, const char* spl)
{
int n = 0;
char *result = NULL;
result = strtok(str, spl);
while (result != NULL)
{
strcpy(dst[n++], result);
result = strtok(NULL, spl);
}
return n;
}
//判断是否需要做分隔处理
bool IncludeCh(char str[], char ch) {
int i;
bool has = false;
for (i = 0; str[i]; ++i) {
if (str[i] == ch)
return true;
}
return false;
}
//string转化成char数组
char* StrToChArr(string src)
{
char *dst = new char[255];
int i;
for (i = 0; i < src.length(); i++)
dst[i] = src[i];
dst[i] = '\0';
return dst;
}
//求若干集合的笛卡尔积
string decare(const vector<vector<string>> &sets, string add)
{
vector<vector<string>> rs;
int n = sets.size();
vector<string> tmp;
string word, result;
for (int i = 0; i < n; ++i)
{
tmp.push_back(sets[i][0]);
}
rs.push_back(tmp);
for (int i = n - 1; i >= 0; --i)
{
int nRsSize = rs.size();
for (int k = 1; k < sets[i].size(); ++k)
{
for (int j = 0; j < nRsSize; ++j)
{
tmp = rs[j];
tmp[i] = sets[i][k];
rs.push_back(tmp);
}
}
}
for (vector<vector<string> >::iterator iter = rs.begin(); iter != rs.end(); iter++)
{
word += add;
for (int i = 0; i < (*iter).size(); i++)
{
word += (*iter)[i] + " ";//词之间添加空格
}
if (iter != rs.end() - 1) {
word += "\n";//末尾不需要换行
}
else {
word += "";
}
}
return word;
}
//输出笛卡尔积结果保存到文件, add为扩充词
string Descarte(string m, string add)
{
vector<vector<string>> charSet;
vector<string> tmp[100];
char dst[10][80];
int k = StrSplit(dst, StrToChArr(m), " ");//第一次分隔,得到 "[A|B|C]"、"D" 、"[E|F|G]""[M|N]"4组数据
char dsts[10][80];
for (int m = 0; m < k; m++)
{
int u = StrSplit(dsts, dst[m], "|[]");//第二次分隔,得到每组数据中的具体值,例如"[A|B|C]"中的"A"、"B"、"C"
for (int f = 0; f < u; f++) {
tmp[m].push_back(dsts[f]);
}
charSet.push_back(tmp[m]);
}
return decare(charSet, add);
}
int main() {
string m = "[A|B|C] D [E|F|G] [M|N]";
if (IncludeCh(StrToChArr(m), '[') && IncludeCh(StrToChArr(m), ']')) {
cout << Descarte(m, "") << endl;
}
system("pause");
return 0;
}
如果您使用VS,在编译时往往会出现以下错误
This function or variable may be unsafe. Consider using strcpy_s instead. To disable deprecation, use _CRT_SECURE_NO_WARNINGS. See online help for details.原因是Visual C++ 2012 以上版本使用了更加安全的 run-time library routines 。新的Security CRT functions(就是那些带有“_s”后缀的函数)
解决办法是即在预编译头文件 stdafx.h 里加入下面两句:
#define _CRT_SECURE_NO_DEPRECATE
#define _CRT_SECURE_CPP_OVERLOAD_STANDARD_NAMES 1注意这两句话的位置要在没有include任何头文件之前
修改后的完整stdafx.h如下
// stdafx.h : 标准系统包含文件的包含文件,
// 或是经常使用但不常更改的
// 特定于项目的包含文件
//
#pragma once
//消除his function or variable may be unsafe警告
#define _CRT_SECURE_NO_DEPRECATE
#define _CRT_SECURE_CPP_OVERLOAD_STANDARD_NAMES 1
#include "targetver.h"
#include <stdio.h>
#include <tchar.h>
// TODO: 在此处引用程序需要的其他头文件
接下来看下运行结果

换一个简单一点的字符串,比如“[A|B] [C|D]”(注意集合直接要有空格)
结果如下,ok
















 7330
7330

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









