






 本文介绍了一种在数据挖掘中提高效率的方法。Tuple博士针对P、Q两个数组的处理提出了创新思路,避免使用乘法和除法以提高速度。通过对P数组中每个record的偏移量进行特殊处理,实现了快速定位Q数组中对应的数据。
本文介绍了一种在数据挖掘中提高效率的方法。Tuple博士针对P、Q两个数组的处理提出了创新思路,避免使用乘法和除法以提高速度。通过对P数组中每个record的偏移量进行特殊处理,实现了快速定位Q数组中对应的数据。
书上具体所有题目:http://pan.baidu.com/s/1hssH0KO
代码:(Accepted,0 ms)
#include<iostream>
unsigned N, A, B, Sp, Sq, ansA, ansB;
unsigned long long Pofs, K, nowK;
int main()
{
//freopen("in.txt", "r", stdin);
while (scanf("%u%u%u", &N, &Sp, &Sq) != -1) {
K = 0xffffffffffffffff;
for (A = 0;A < 32;++A) for (B = 0;B < 32;++B) {
Pofs = (N - 1)*Sp;
nowK = (Pofs + (Pofs << A) >> B) + Sq;
if (nowK >= N*Sq && nowK < K) K = nowK, ansA = A, ansB = B;
}
printf("%llu %u %u\n", K, ansA, ansB);
}
return 0;
}题意:看着好复杂的题目。看了半天不懂,看网上人家的解释也是一头雾水。于是花了好久把他翻译并理解。翻译只是大概翻翻,但和原意基本一致,括号内的内容是我最终理解的内容。
翻译如下:
Tuple博士正在给ACM公司研究数据挖掘。其中一个子工程是关于P、Q两个数组的,两个数组各含N组数据(这个“组”的单位是record,不知道怎么翻译好。论好好学习英语的重要性。)。这N个record的数据从0到N-1命名。数组P包含含密钥的类似哈希的结构。P用来给程序定位要用哪个record,且这个数据的对应的Q里的record待会会从Q数组里恢复出来(如紫书中文的理解就是知道P的第i个record的偏移量求Q第i个数据的偏移量)。
数组P中的每个record长度为Sp字节,Q的每个record长Sq字节。Tuple酱需要最最高效地执行这个程序,因为这是整个数据挖掘一直要用到的地方。但是坑爹的是Sp和Sq只在运行时知道其大小,没法在编译时进行优化(哦就跟定义数组必须要用常量来定义的原因类似)。
找到P数组的第i个record的偏移量(不懂偏移量是什么,差不多就是指:比如一个数组a[10],那么a[3]的地址在首地址的右边地三个,偏移量就是(&a[3]-a) · sizeof(int),也就是3 · sizeof(int)。如果我没猜错应该就是了)的最直接的方法是用以下函数:
Pods(i) = Sp * I (1)
Q的也一样:
Qods(i) = Sq * I (2)
但是!乘法比加减法慢多了(哦你好烦啊,直接说你最后用了什么就行了啊)。Tuple酱拒绝使用乘法。那么他怎么做的?他保存了已经计算好的第i个record的偏移量Pofs(i),而不是保存这个下标(索引)i(哦就相当于一个数组a[10],你已经计算得你要的数据是a[2],现在别人要调用a[2],你给他 p=&a[2]比直接给他i=2让他自己找到a{2}更快。是这个意思吧*)。于是现在当他需要计算第i个record旁边的record的偏移量时,就用下面的方程:
Pofs(i + 1) = Pofs(i) + Sp
Pofs(i - 1) = Pofs(i) – Sp
(好吧,原来就相当于我们遍历数组时用指针*p先指向首地址,然后不停p++指向下一个数据一样啊,比直接调用a[i++]快啊)
当一个P的record不管是用上面两个方法的哪个(用乘法扫描数组,及用其他数据的偏移量用加减法获得),Tuple酱需要从对应Q数组把数据恢复进去。要获取Q的record的偏移量Qofs(i)也要计算。当Pofs(i)已知时可以直接用(1)、(2)两个函数求得Qofs(i)。
Qofs(i) = Pofs(i)/SP SQ (3)(就把(1)、(2)整合了一下*)
然后又来了。“Unfortunately”,这个函数不仅有乘法,甚至还有除法!“我不管我不管,乘除就是比加减慢!我就是不允许乘除的出现!” Tuple酱傲娇地鼓起了腮帮。
最后Tuple酱研究得出,可以这么求Qofs(i):
Qofs’(i) = (Pofs(i) + Pofs(i) < < A) > > B (4)
(Qofs’(i)那个’不是求导的意思哦,我说一开始怎么没看懂。)(等一下让我查一下位移运算和加法运算的优先级。。。好的+比<<优先级高??不对啊,那他要这个括号干嘛?看了下别人的代码,这里题目错了。应该是(Pofs(i) +((Pofs(i) < < A)) > > B。但是还是没看懂怎么从(3)推出这个式子的??!!)(好的现在看懂了,这是一个新方法,和(3)无关,不是从(3)推导出来的。这个方法牺牲了些没用上的内存但是速度快了。详见分析)
A和B是无符号整形。这个函数跑的比(3)不知道快到哪里去了。但是不管A、B选何值,它一般不能总是产生和(3)一样的结果(喵喵喵???为什么不一样?没看懂。根据紫书:“为了让(4)成立,在P数组连续存储的情况下Q可以不连续存储”我去?哪里说可以不连续存储了。好吧现在看懂了,最下面一起讲。)。但是如果你愿意牺牲点内存,你还是可以用。
传统的布局里,Q在内存里需要N*Sq字节去储存整个数组。Tuple发现总是可以找到一个K(K<=N*Sq)(题目反了吧??!!K>=N · Sq还差不多,看样例输入输出也明显是1119>=1024 · 1),如果分配K字节的内存给Q且小心地找A和B的值,(4)会给不重复的把存储地址给数组Q的N个record。
你的目标是写一个程序找出当(4)被用时最小的内存K去分配给Q,对应的A、B也要找出来。若多个A、B得到一样的最小的K,那么找出A最小的那组,还不行,那就找B最小的。
(这个CSDN-markdown编辑器好垃圾啊,为什么不能输出多个空格?导致不能每段首行缩进两个字??!!狂按空格也没效果。。我按空格你也要管。。)
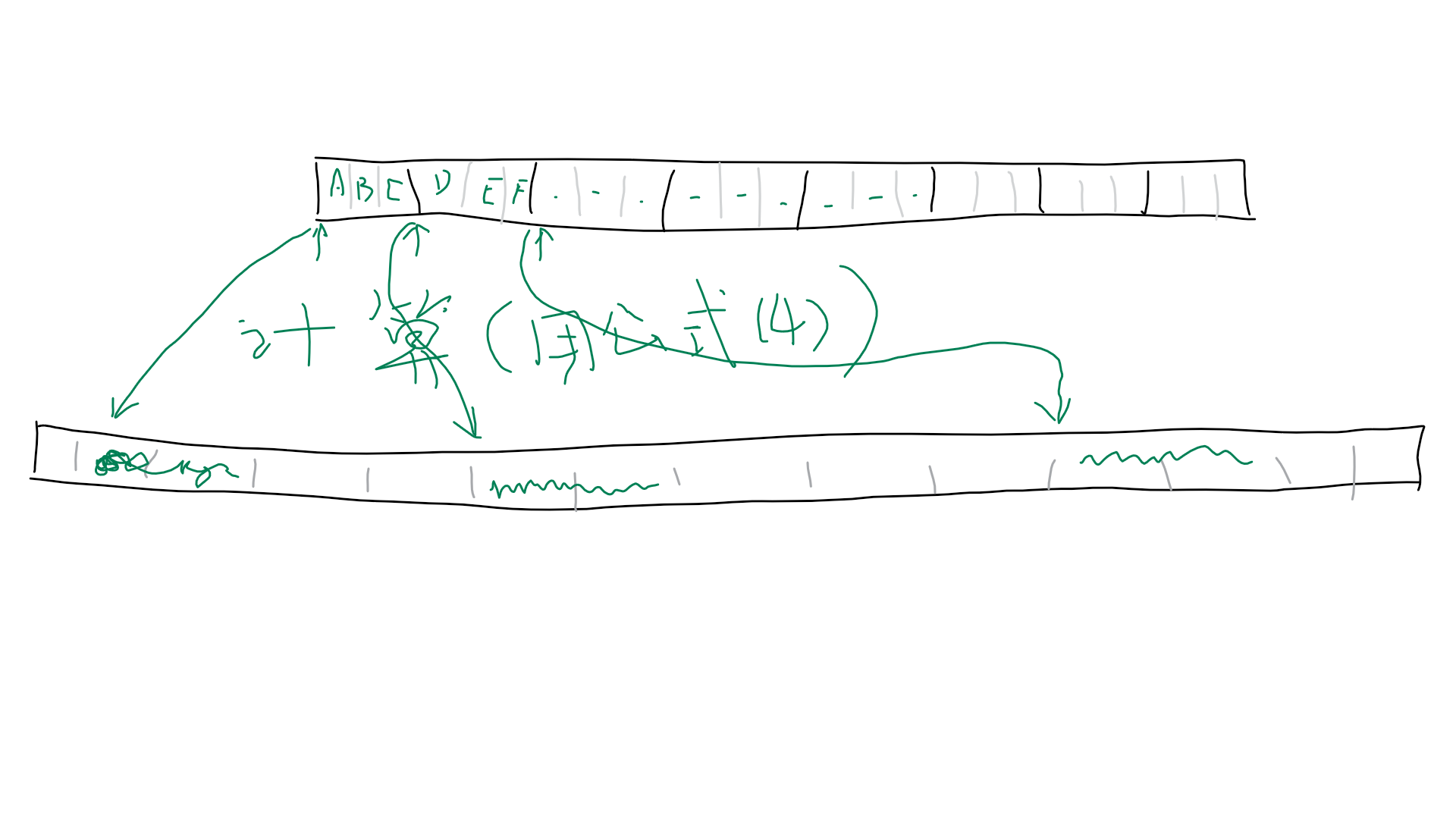
分析:好的那么就是说 (比如如图,P是上面那个,每个数据占3bit,Q占2bit)以P的某个数据的偏移量按照(4)快速求出Q对应数据的地址(算的快的结果是部分内存没用上)。所以原来(3)、(4)不是等价的,是Tuple酱另外想的方法。我说怎么死活看不懂、推不出来(4)这个公式。
所以简言之,已知A和B,P的每一个元素的偏移量Pofs(其实就是第i个元素首地址位置)通过含A和B的公式4计算得出Qofs(即求出Q的第i个元素的位置)后,即知道了Q的各个元素的位置。现在要求找出Q最少占用多少空间,即求Q的后一个元素的最后一个字节的地址与分配的第一个内存地址的距离即可。(本来我还想Q的各个元素的存储位置不能重叠,要不要判断,但是题目已经说了,用公式4保证不会出现存储重叠)
那么暴力枚举A,B即可。而还有个问题,A,B没说范围。那么因为
1 ≤ N ≤ 2^20,1 ≤ SP ≤ 2^10,1 ≤ SQ ≤ 2^10
因为Pofs最大为(N-1)*Sp,所以这里最大(2^20-1) · 2^10差不多2的30次方。而long long64位,也就30多位可以给你移的。而且参考了 http://blog.csdn.net/code4101/article/details/38540759 这篇博文,那么30多次的枚举就行了。那么说到这里,这题其实是个超简单的题目。
/*
本来我一开始看题目时觉得这都什么鬼,看不懂。
但是看到紫书上说“本题有一定实际意义,不过描述比较抽象。如果对本题兴趣不大,可以先跳过。”于是瞬间来了兴趣… (—。—) 哈哈我简直是个受虐狂。
*/

















 621
621

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









