





假定假设函数为一个二次函数,只是参数未定:
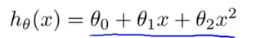
每给定一个样本大小,就能训练出对应的假设函数,从而利用这个假设函数可以计算出Jtrain(仍然在之前拿来训练的那些样本里面),然后将训练好的假设函数用在全部的验证集上可以计算出Jcv(注意在计算准确率的时候就不必λ了)。
则代价与训练样本的个数之间的关系为:
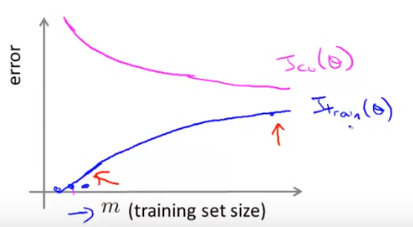
1、高偏差情形
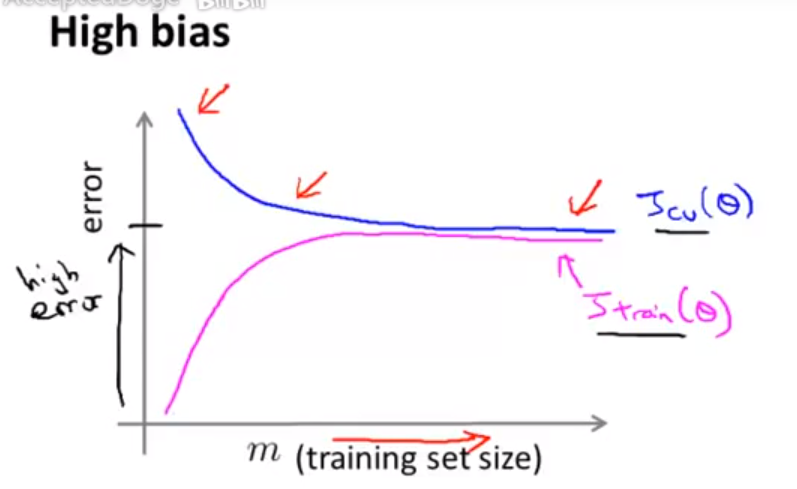
可以看出:即使训练样本很多也无济于事,必须更改模型以解决本质问题。
2、高方差情形
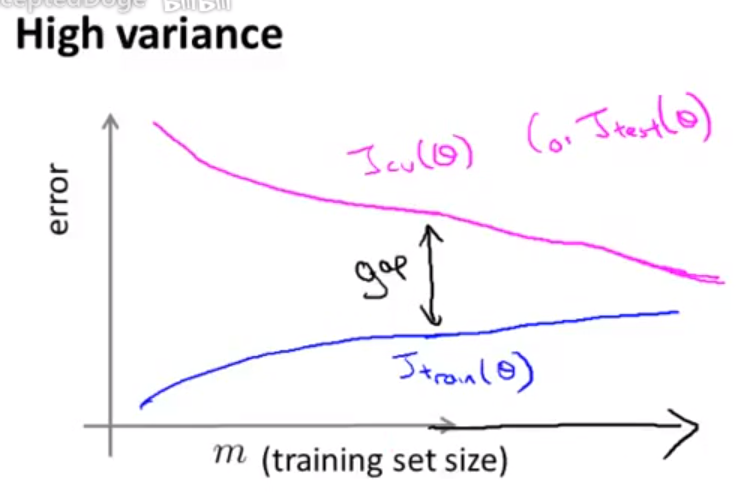
可以看出:增加训练样本个数对应过拟合情形来说是有效果的。

假定假设函数为一个二次函数,只是参数未定:
每给定一个样本大小,就能训练出对应的假设函数,从而利用这个假设函数可以计算出Jtrain(仍然在之前拿来训练的那些样本里面),然后将训练好的假设函数用在全部的验证集上可以计算出Jcv(注意在计算准确率的时候就不必λ了)。
则代价与训练样本的个数之间的关系为:
可以看出:即使训练样本很多也无济于事,必须更改模型以解决本质问题。
可以看出:增加训练样本个数对应过拟合情形来说是有效果的。
转载于:https://www.cnblogs.com/pjishu/p/10805088.html
 340
8177
340
8177











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言























