






- 递归:在函数里自己调用自己就是递归,递归的最大深度是998


1 def age(n): 2 if n == 3: 3 return 40 4 else: 5 return age(n+1)+2 #自己调用自己,每次返回age() 6 print(age(1))
#算法,二分查找算法
所采用的的在空间上(内存里)或者时间上(执行的时间)更有优势的算法
排序就是算法的一种,包括:快速排序 堆排序 冒泡排序
查找也是算法的一种。
递归求解二分查找算法 :只能解决有序的数字集合的查找问题
l = [2,3,5,10,15,16,18,22,26,30,32,35,41,42,43,55,56,66,67,69,72,76,82,83,88] #不改变列表 def cal(l,num,start,end): if start <= end: mid = (end - start)//2 + start # 0 26 - 1 // 2 12 if l[mid] > num: # start = 0 # end = mid - 1 return cal(l,num,start,mid - 1) elif l[mid] <num: # start = mid + 1 # end = len(l) - 1 return cal(l,num,mid + 1,end) else: return mid else:return 'meizhaodao' print(cal(l,43,0,len(l)-1))
上边例子有几个问题:传参太多,没有该数会报错
传参太多的问题,报错问题整合:
1 l = [2,3,5,10,15,16,18,22,26,30,32,35,41,42,43,55,56,66,67,69,72,76,82,83,88] 2 def cal(l,num,start=0,end=None): 3 if end: 4 end = end 5 else:end = len(l)-1 6 if start <= end: 7 mid = (end - start)//2 + start# 0 26 - 1 // 2 12 8 if l[mid] > num: 9 # start = 0 10 # end = mid - 1 11 return cal(l,num,start,mid - 1) 12 elif l[mid] <num: 13 # start = mid + 1 14 # end = len(l) - 1 15 return cal(l,num,mid + 1,end) 16 else: 17 return mid 18 else:return None 19 print(cal(l,43))
总结:二分查找算法,只能解决有序的数字集合的查找问题,使用递归的时候一定要记得需要返回return的时候一定要返回,不然none会报错。
###################################################################模块###################################################################
模块:模块就是py文件,是写好了但是不直接使用的功能,为了节省内存
模块分类:内置模块,扩展模块,自定义模块 推荐网站:pypi.org
- 内置模块:安装python自带的模块
- namedtuple: 生成可以使用名字来访问元素内容的tuple
- deque: 双端队列,可以快速的从另外一侧追加和推出对象
- Counter: 计数器,主要用来计数
- OrderedDict: 有序字典
- defaultdict: 带有默认值的字典
#collections模块 OrderedDict import collections d = collections.OrderedDict() d['1'] = 1 d['2'] =2 for i in d: print(d,d[i])
#namedtuple可命名元组 from collections import namedtuple point = namedtuple('pnt',['x','y']) p = point(1,2) print(p.x) card = namedtuple('card',['rank','suit']) c = card('2','hongxin') #纸牌的玩法 红心 和 2 分开 print(c.rank,c.suit)
duque 双端队列,从两边开始添加删除数据 节省内存
- time时间模块
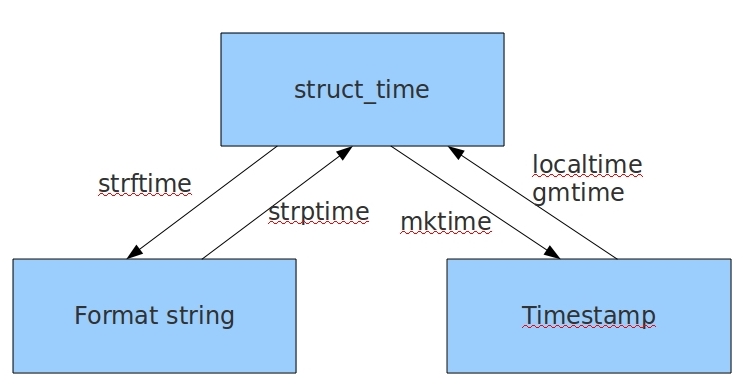
三种表示时间的方式:时间戳时间 英国伦敦时间 1970.1.1.0.0.0
北京时间 1970.1.1.8.0.0
格式化时间 用字符串表示的时间
机构化时间 time.localtime
import time print(time.time()) #时间戳 print(time.strftime('%Y-%m-%d %H:%M:%S')) #格式化时间 print(time.strftime('%x')) print(time.strftime('%c')) print(time.localtime()) #结构化时间
时间之间的想换转换可以参考上图:
1 #结构化时间 --> %a %b %d %H:%M:%S %Y串 2 time.asctime(结构化时间) 如果不传参数,直接返回当前时间的格式化串 3 time.asctime(time.localtime(1500000000)) 4 'Fri Jul 14 10:40:00 2017' 5 time.asctime() 6 'Mon Jul 24 15:18:33 2017'
1 #时间戳 --> %a %d %d %H:%M:%S %Y串 2 time.ctime(时间戳) 如果不传参数,直接返回当前时间的格式化串 3 time.ctime() 4 'Mon Jul 24 15:19:07 2017' 5 time.ctime(1500000000) 6 'Fri Jul 14 10:40:00 2017'
#结构化时间-->字符串时间 time.strftime("格式定义","结构化时间") #结构化时间参数若不传,则现实当前时间 time.strftime("%Y-%m-%d %X") #'2017-07-24 14:55:36' time.strftime("%Y-%m-%d",time.localtime(1500000000)) #'2017-07-14'
1 #字符串时间-->结构化时间 2 time.strptime(时间字符串,字符串对应格式) 3 time.strptime("2017-03-16","%Y-%m-%d") 4 time.struct_time(tm_year=2017, tm_mon=3, tm_mday=16, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=3, tm_yday=75, tm_isdst=-1) 5 time.strptime("07/24/2017","%m/%d/%Y") 6 time.struct_time(tm_year=2017, tm_mon=7, tm_mday=24, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=0, tm_yday=205, tm_isdst=-1)
1 #时间戳-->结构化时间 2 time.gmtime(时间戳) #UTC时间,与英国伦敦当地时间一致 3 time.localtime(时间戳) #当地时间。例如我们现在在北京执行这个方法:与UTC时间相差8小时,UTC时间+8小时 = 北京时间 4 time.gmtime(1500000000) 5 time.struct_time(tm_year=2017, tm_mon=7, tm_mday=14, tm_hour=2, tm_min=40, tm_sec=0, tm_wday=4, tm_yday=195, tm_isdst=0) 6 time.localtime(1500000000) 7 time.struct_time(tm_year=2017, tm_mon=7, tm_mday=14, tm_hour=10, tm_min=40, tm_sec=0, tm_wday=4, tm_yday=195, tm_isdst=0)
1 #结构化时间-->时间戳 2 time.mktime(结构化时间) 3 time_tuple = time.localtime(1500000000) 4 time.mktime(time_tuple) 5 1500000000.0
习题:计算两个时间的时间差
1 import time 2 t1 = '2017-1-5 11:20:30' 3 t2 = '2037-4-5 10:20:30' 4 s = time.strptime(t1,'%Y-%m-%d %H:%M:%S') 5 s1 = time.strptime(t2,'%Y-%m-%d %H:%M:%S') 6 a = time.mktime(s) 7 b = time.mktime(s1) 8 dat = time.gmtime(b - a) 9 print(dat) 10 print('过去了%s年%s月%s日%s小时%s分钟%s秒' % (dat.tm_year-1970,dat.tm_mon-1,dat.tm_mday-1,dat.tm_hour,dat.tm_min,dat.tm_sec)) 11 print('t1和t2相差%s年%s月%s日%s小时%s分钟%s秒' % ())
- random随机数模块
import random #随机数模块 random模块 #随机小数 print(random.random()) #0-1 print(random.uniform(1,3)) #指定范围 1-3间的小数 #随机整数 print(random.randint(1,5)) #1-5之间的整数 print(random.randrange(1,10,2)) #1-10之间的步长为2的数 #随机选择一个数 print(random.choice([1,2,3,4])) #随机选择一个数 #随机选择多个数返回 print(random.sample([1,2,3,[4,5]],2))#随机选择几个组合 l = '' for i in range(4): l += str(random.randint(0,10)) print(l) #数字字母随机生成六位验证码 chr函数可以使数字转换成字母(65,90) (A-Z) (97,122) (a-z) l = '' for i in range(6): num1 = chr(random.randint(65,90)) num2 = chr(random.randint(97,122)) num3 = random.randint(0,9) l += str(random.choice([num1,num2,num3])) print(l)
###random模块可以做验证码,发红包,扑克牌抽取等各种
- 跟解释器打交道的sys模块
1 import sys 2 sys.modules #存放所有在解释器运行的过程中导入的模块名 3 sys.exit() #结束解释器运行 解释器退出 4 sys.path #一个模块是否能被导入,全看模块在不在sys.path列表所包含的路径下边 5 print(sys.path) #创建模块的时候不要乱起名字,怕占用其他模块名字 6 7 sys.argv #脚本执行的时候需要用到的 8 print(sys.argv) #在执行python脚本的时候可以传递参数进来 9 import sys 10 print(sys.argv) 11 if sys.argv[1] == 'alex' and sys.argv[2] == 'alex1314': 12 print('welcome') 13 else:sys.exit()
- os模块系统模块-----运维相关可以使用
1 import os 2 # os.makedirs() #可生成多层递归目录 3 # os.removedirs() #若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 4 # os.mkdir() #生成单级目录;相当于shell中mkdir dirname 5 # os.rmdir() #删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname 6 # os.listdir() #列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 7 #os.remove() #删除一个文件 8 #os.rename("oldname","newname") #重命名文件/目录 9 # print(os.stat('D:\demo\day5\\1.讲在课前') ) #获取文件/目录信息 10 # os.stat 11 # st_mode: inode 保护模式 12 # st_ino: inode 节点号。 13 # st_dev: inode 驻留的设备。 14 # st_nlink: inode 的链接数。 15 # st_uid: 所有者的用户ID。 16 # st_gid: 所有者的组ID。 17 # st_size: 普通文件以字节为单位的大小;包含等待某些特殊文件的数据。 18 # st_atime: 上次访问的时间。 19 # st_mtime: 最后一次修改的时间。 20 # st_ctime: 由操作系统报告的"ctime"。在某些系统上(如Unix)是最新的元数据更改的时间,在其它系统上(如Windows)是创建时间(详细信息参见平台的文档)
1 #跟操作系统相关的 2 print(os.sep) # 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/" 3 print(os.linesep) #输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n" 4 print(os.pathsep) #输出用于分割文件路径的字符串 win下为;,Linux下为: 5 print(os.name)#输出字符串指示当前使用平台。win->'nt'; Linux->'posix' 6 ###############使用分割符的时候################################# 7 'PATH1%sPATH2' % os.path.sep 8 9 print(os.environ) #获取系统环境变量 10 11 os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 12 os.chdir("dirname") @改变当前脚本工作目录;相当于shell下cd 13 os.curdir @返回当前目录: ('.') 14 os.pardir @获取当前目录的父目录字符串名:('..') 15 16 os.system("dir") #运行shell命令,直接调用dir命令显示在这里 exec 17 print(os.popen("dir").read()) #运行shell命令,获取执行结果
######################os.path###############################
1 print(os.path.abspath('D:\demo\day5\\1.讲在课前')) #返回path规范化的绝对路径 2 print(os.path.split('D:\demo\day5\\1.讲在课前')) #将path分割成目录和文件名二元组返回 spilt = dirname + basename 3 os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素 4 os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素 5 print(os.path.exists('D:\demo\day5\\1.讲在课前'))# #如果path存在,返回True;如果path不存在,返回False 6 print(os.path.isabs('D:\demo\day5\\1.讲在课前')) #如果path是绝对路径,返回True 7 os.path.isfile() #如果path是一个存在的文件,返回True。否则返回False 8 os.path.isdir() #如果path是一个存在的目录,则返回True。否则返回False 9 print(os.path.join('D:\\','demo','day5'))# 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 10 os.path.join #路径的拼接就用os模块这个 11 os.path.getatime() #返回path所指向的文件或者目录的最后访问时间 12 os.path.getmtime() #返回path所指向的文件或者目录的最后修改时间 13 os.path.getsize() #返回path的大小 三级菜单 递归 堆栈思想 14 15 #判断文件夹下边文件的大小 16 ret = os.listdir('D:\demo\day5') 17 sum = 0 18 for i in ret: 19 if os.path.isfile(i) is True: 20 sum += os.path.getsize(i) 21 print(sum)
- 正则表达式
正则表达式 字符串匹配相关的操作的时候用到的一种规则
正则表达式的规则
使用python中的re模块去操作正则表达式
字符组 :【】 在同一个位置可能出现的各种字符组成了一个字符组 一个字符组只表示一个字符
元字符 对一个字符的匹配创建的一些规则
这些规则是在正则表达式中有着特殊意义的符号
如果要匹配的字符刚好是和元字符一模一样,需要转义
1 #验证数字:^[0-9]*$ 2 # 验证n位的数字:^\d{n}$ 3 # 验证至少n位数字:^\d{n,}$ 4 # 验证m-n位的数字:^\d{m,n}$ 5 # 验证零和非零开头的数字:^(0|[1-9][0-9]*)$ 6 # 验证有两位小数的正实数:^[0-9]+(.[0-9]{2})?$ 7 # 验证有1-3位小数的正实数:^[0-9]+(.[0-9]{1,3})?$ 8 # 验证非零的正整数:^\+?[1-9][0-9]*$ 9 # 验证非零的负整数:^\-[1-9][0-9]*$ 10 # 验证非负整数(正整数 + 0) ^\d+$ 11 # 验证非正整数(负整数 + 0) ^((-\d+)|(0+))$ 12 # 验证长度为3的字符:^.{3}$ 13 # 验证由26个英文字母组成的字符串:^[A-Za-z]+$ 14 # 验证由26个大写英文字母组成的字符串:^[A-Z]+$ 15 # 验证由26个小写英文字母组成的字符串:^[a-z]+$ 16 # 验证由数字和26个英文字母组成的字符串:^[A-Za-z0-9]+$ 17 # 验证由数字、26个英文字母或者下划线组成的字符串:^\w+$ 18 # 验证用户密码:^[a-zA-Z]\w{5,17}$ 正确格式为:以字母开头,长度在6-18之间,只能包含字符、数字和下划线。 19 # 验证是否含有 ^%&',;=?$\" 等字符:[^%&',;=?$\x22]+ 20 # 验证汉字:^[\u4e00-\u9fa5],{0,}$ 21 # 验证Email地址:^\w+[-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$ 22 # 验证InternetURL:^http://([\w-]+\.)+[\w-]+(/[\w-./?%&=]*)?$ ;^[a-zA-z]+://(w+(-w+)*)(.(w+(-w+)*))*(?S*)?$ 23 # 验证电话号码:^(\(\d{3,4}\)|\d{3,4}-)?\d{7,8}$:--正确格式为:XXXX-XXXXXXX,XXXX-XXXXXXXX,XXX-XXXXXXX,XXX-XXXXXXXX,XXXXXXX,XXXXXXXX。 24 # 验证身份证号(15位或18位数字):^\d{15}|\d{}18$ 25 # 验证一年的12个月:^(0?[1-9]|1[0-2])$ 正确格式为:“01”-“09”和“1”“12” 26 # 验证一个月的31天:^((0?[1-9])|((1|2)[0-9])|30|31)$ 正确格式为:01、09和1、31。 27 # 整数:^-?\d+$ 28 # 非负浮点数(正浮点数 + 0):^\d+(\.\d+)?$ 29 # 正浮点数 ^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$ 30 # 非正浮点数(负浮点数 + 0) ^((-\d+(\.\d+)?)|(0+(\.0+)?))$ 31 # 负浮点数 ^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$ 32 # 浮点数 ^(-?\d+)(\.\d+)?
元字符 匹配内容
1 # . 匹配除换行符以外的任意字符 2 # \w 匹配字母或数字或下划线 3 # \s 匹配任意的空白符 4 # \d 匹配数字 5 # \n 匹配一个换行符 6 # \t 匹配一个制表符 7 # \b 匹配一个单词的结尾 8 # ^ 匹配字符串的开始 9 # $ 匹配字符串的结尾 10 # \W 匹配非字母或数字或下划线 11 # \D 匹配非数字 12 # \S 匹配非空白符 13 # a| b 匹配字符a或字符b 14 # () 匹配括号内的表达式,也表示一个组 15 # [...] 匹配字符组中的字符 16 # [ ^ ...]匹配除了字符组中字符的所有字符
量词 量词一定是跟在一个元字符的后边约束某个字符的规则能更重复多少次
量词 用法说明
1 # * 重复零次或更多次 2 # + 重复一次或更多次 3 # ? 重复零次或一次 4 # {n} 重复n次 5 # {n,} 重复n次或更多次 6 # {n,m} 重复n到m次
正则表达式默认贪婪匹配 会在当前量词约束的范围内匹配尽量多的次数
1 import re 2 ret = re.findall('a','asdasasdasdasdsa') 3 print(ret) 4 #优先级: 5 ret = re.findall('www.(baidu|oldboy).com', 'www.oldboy.com') 6 print(ret) # ['oldboy'] #这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可 7 8 ret = re.findall('www.(?:baidu|oldboy).com', 'www.oldboy.com') 9 print(ret) # ['www.oldboy.com'] 10 #找所有 11 ret = re.search('\d+','e123va sad2414a a123rr').group() 12 if ret: 13 print(ret) 14 #找第一个符合条件的找到就跳出 返回的值是一个内存地址需要使用.group取值 15 #如果匹配不上 返回None 会报错 16 ret = re.match('^\d+','123e123va sad2414a a123rr') 17 print(ret) 18 if ret:print(ret.group()) 19 march 在search 的基础上 给每一条正则都加上一个^ 20 re.split() 21 re.sub() 22 re.subn() 23 re.compile() 24 re.finditer()














 9425
9425











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









