







系统数据量达到一定程度后必将采用分库分表的方式来提高系统性能,但传统的分库分表方式也必将带来更高的开发复杂程度。新一代的NewSql及NoSql数据库由于天生的分布式存储基因,既保证了能够横向扩展,又可以避免较高的开发复杂程度。AppBoxFuture框架的存储引擎借鉴了新一代分布式数据库分而治之的思想,在设计实体模型时可以指定分区键,存储引擎会根据分区键创建相应的RaftGroup(多个副本)。需要注意的是AppBoxFuture框架的分区策略与NewSql不同,NewSql一般采用自动分裂与合并的方式来管理分区,而框架采用的是一开始就指定分区键的方式,更类似于Cassandra的分区方式,但又不同于Cassandra的分区不能排序。
在设计实体模型时先要估算数据量来确定是否需要分区存储,一般的基础信息如客户信息之类的不需要分区,但订单之类的动态数据,可以根据年或月份作为分区键,如果是SaaS类的应用,可以用租户Id + 期间作为分区键。
作者录了个演示视频演示视频链接, 简单说明一下演示内容:
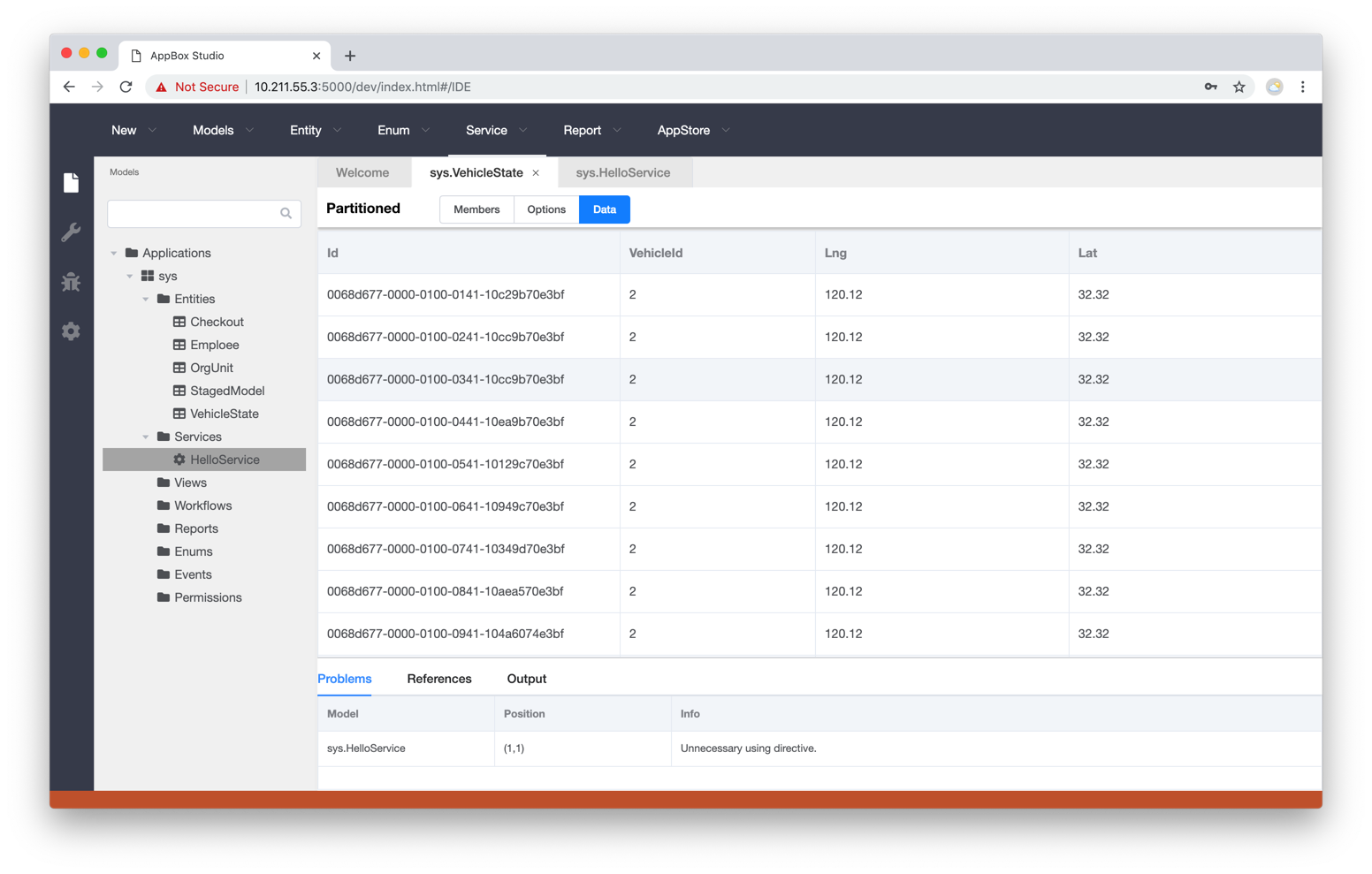
- 新建车辆状态(VehicleState)实体模型,加入VehicleId, Lng, Lat成员, 设置分区键为VehicleId;
- 新建测试服务并发插入8万条记录,计算每秒tps(演示视频20行 i < loopCount 应为 j < loopCount)。
在作者的虚拟机内(4C8G)的进行单分区并发插入的测试结果如下图, 虚拟机Cpu已经跑满。实际单独测试存储引擎(C++)可达40000/秒,Clr层代码还有优化的空间。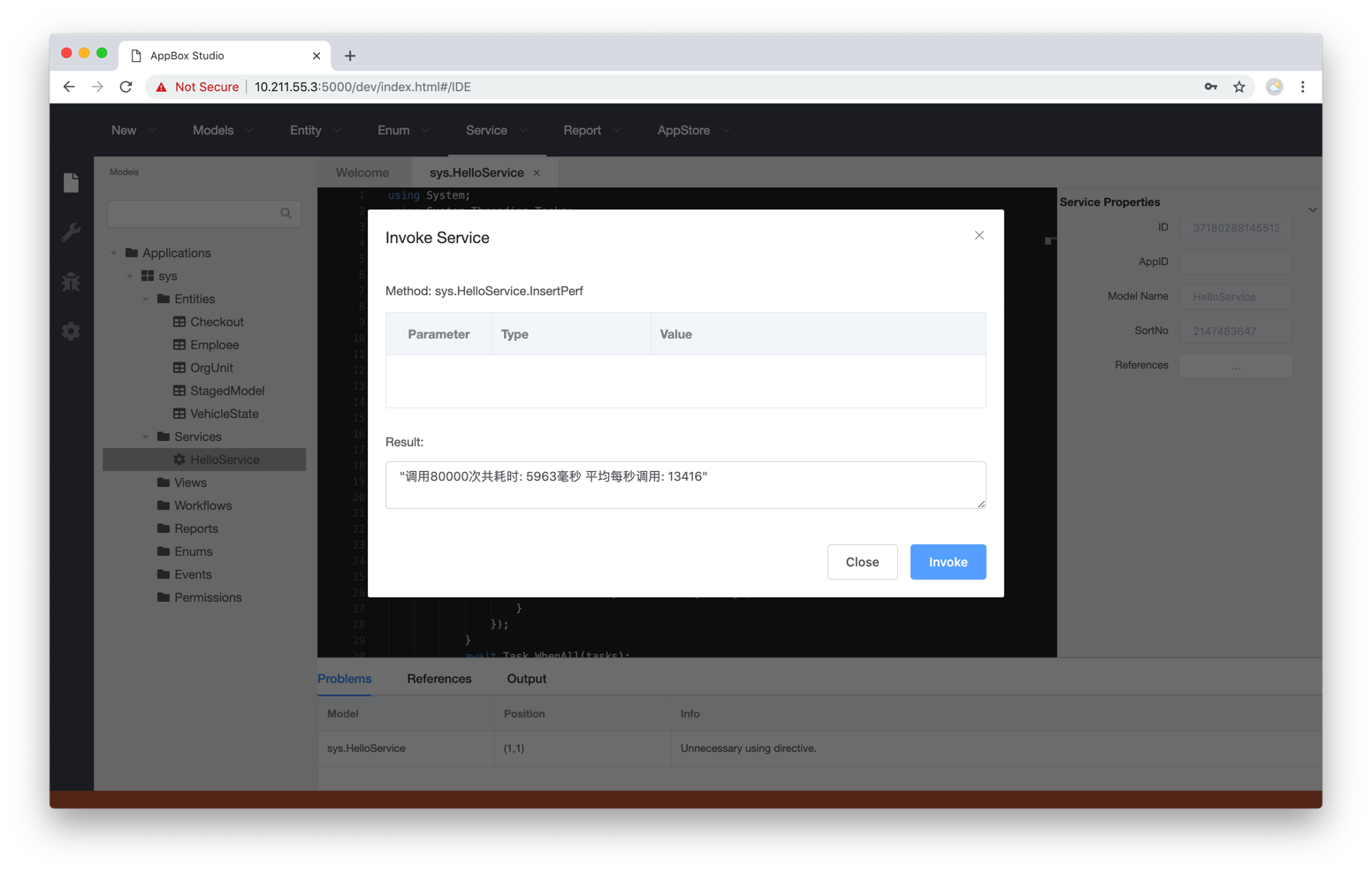
作者下一步的开发重点是:
- 设计与实现索引扫描api;
- 设计与实现聚合扫描api,可以并行聚合各分区;
- 实体间关系EntityRef, EntitySet实现。
如果您觉得该项目将来能帮到您,请您扫以下二维码打赏一下作者以购买测试VM;如果您有问题或Bug报告,请在Github提交。















 176
176











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









