






作者:jackshi,腾讯 PCG 后台开发工程师
从C++切换到Go语言一年多了,有必要深入了解一下Go语言内置数据结构的实现原理,本文结合示例与Go源码深入到Go语言的底层实现。
数组
定义
数组是切片和映射的基础数据结构。
数组是一个长度固定的数据类型,用于存储一段具有相同类型元素的连续块。

声明与初始化
var arr [5]int //声明一个包含五个元素的数组arr := [5]int{1, 2, 3, 4, 5} //字面量声明arr := [...]int{1, 2, 3, 4, 5} //编译期自动推导数组长度arr := [5]int{1:10,3:30} //初始化索引为1和3的元素,其他默认值为0数组的使用
arr := [5]int{10, 20, 30, 40, 50}arr[2] = 35 //修改索引为2的元素的值var arr1 [3]stringarr2 := [3]string{"red", "yellow", "green"}arr1 = arr2 //数组拷贝(深拷贝)var arr3 [4]stringarr3 = arr2 //error 数组个数不同var arr [4][2]int //多维数组arr[1][0] = 20arr[0] = [2]int{1, 2}函数间传递数组
var arr [1e6]intfunc foo1(arr [1e6]int) { //每次拷贝整个数组 ...}func foo2(arr *[1e6]int) { //传递指针,效率更高 ...}切片
切片是一种数据结构,便于使用和管理数据集合。切片是围绕动态数组的概念构建的,可以按需自动增长和缩小。
内部实现
type SliceHeader struct { Data uintptr Len int Cap int}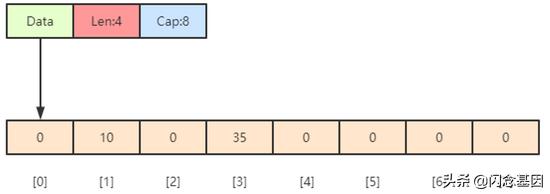
编译期间的切片是 Slice 类型的,但是在运行时切片由 SliceHeader结构体表示,其中Data 字段是指向数组的指针,Len表示当前切片的长度,而 Cap表示当前切片的容量,也就是Data数组的大小。
创建和初始化
slice := make([]string, 5) //创建一个字符串切片,长度和容量都是5个元素slice := make([]int, 3, 5) //创建一个整型切片,长度为3个元素,容量为5个元素slice := make([]string, 5, 3) //error 容量需要小于长度slice := []string{"Red", "Yellow", "Green"} //使用字面量声明var slice []int //创建nil整型切片slice := make([]int, 0) //使用make创建空的整型切片slice := []int{} //使用切片字面量创建空的整型切片不管是使用nil切片还是空切片,对其调用内置函数append、len、cap效果都一样,尽量使用len函数来判断切片是否为空赋值和切片
slice := []int{1, 2, 3, 4, 5} //创建一个整型切片,长度和容量都是5slice[2] = 30 //修改索引为2的元素的值,slice当前结果为{1, 2, 30, 4, 5}newSlice := slice[1:3] //创建一个新切片,长度为2个元素,容量为4个元素对底层数组容量是k的切片slice[i:j]来说:长度:j - i容量:k - inewSlice[0] = 20 //由于newSlice与slice底层共享一个数组,因此slice当前结果为{1, 20, 30, 4, 5}newSlice[3] = 40 //error 虽然容量足够,但超过长度限制,会触发panic切片增长
slice := []int{1, 2, 3, 4, 5}newSlice := slice[1:3] //cap(newSlice) : 4 newSlice = append(newSlice, 60) // slice当前结果为{1, 2, 3, 60, 5} //newSlice的append操作影响了slice的结果,可以尝试 newSlice := slice[1:3:3]再看看结果newSlice = append(newSlice, []int{70, 80}...) //slice当前结果仍为{1, 2, 3, 60, 5} len(newSlice) : 5 cap(newSlice) : 8func growslice(et *_type, old slice, cap int) slice { ... newcap := old.cap doublecap := newcap + newcap if cap > doublecap { newcap = cap } else { if old.cap < 1024 { newcap = doublecap } else { for 0 < newcap && newcap < cap { newcap += newcap / 4 } if newcap <= 0 { newcap = cap } } } ...}在分配内存空间之前需要先确定新的切片容量,Go 语言根据切片的当前容量选择不同的策略进行扩容:
如果期望容量大于当前容量的两倍就会使用期望容量; 如果当前切片的长度小于 1024 就会将容量翻倍; 如果当前切片的长度大于 1024 就会每次增加 25% 的容量,直到新容量大于期望容量; 这里只是确定切片的大致容量,接下来还需要根据切片中元素的大小对它们进行对齐,当数组中元素所占的字节大小为 1、8 或者 2 的倍数时,运行时会使用如下所示的代码对其内存
func growslice(et *_type, old slice, cap int) slice { ... var overflow bool var lenmem, newlenmem, capmem uintptr switch { case et.size == 1: lenmem = uintptr(old.len) newlenmem = uintptr(cap) capmem = roundupsize(uintptr(newcap)) overflow = uintptr(newcap) > maxAlloc newcap = int(capmem) case et.size == sys.PtrSize: lenmem = uintptr(old.len) * sys.PtrSize newlenmem = uintptr(cap) * sys.PtrSize capmem = roundupsize(uintptr(newcap) * sys.PtrSize) overflow = uintptr(newcap) > maxAlloc/sys.PtrSize newcap = int(capmem / sys.PtrSize) case isPowerOfTwo(et.size): var shift uintptr if sys.PtrSize == 8 { // Mask shift for better code generation. shift = uintptr(sys.Ctz64(uint64(et.size))) & 63 } else { shift = uintptr(sys.Ctz32(uint32(et.size))) & 31 } lenmem = uintptr(old.len) << shift newlenmem = uintptr(cap) << shift capmem = roundupsize(uintptr(newcap) << shift) overflow = uintptr(newcap) > (maxAlloc >> shift) newcap = int(capmem >> shift) default: lenmem = uintptr(old.len) * et.size newlenmem = uintptr(cap) * et.size capmem, overflow = math.MulUintptr(et.size, uintptr(newcap)) capmem = roundupsize(capmem) newcap = int(capmem / et.size) } ...}runtime.roundupsize函数会将待申请的内存向上取整,取整时会使用内存分配中介绍的runtime.class_to_size数组,使用该数组中的整数可以提高内存的分配效率并减少碎片。
func growslice(et *_type, old slice, cap int) slice { ... if overflow || capmem > maxAlloc { panic(errorString("growslice: cap out of range")) } var p unsafe.Pointer if et.ptrdata == 0 { p = mallocgc(capmem, nil, false) memclrNoHeapPointers(add(p, newlenmem), capmem-newlenmem) } else { p = mallocgc(capmem, et, true) if lenmem > 0 && writeBarrier.enabled { bulkBarrierPreWriteSrcOnly(uintptr(p), uintptr(old.array), lenmem-et.size+et.ptrdata) } } memmove(p, old.array, lenmem) return slice{p, old.len, newcap}}如果切片中元素不是指针类型,那么就会调用memclrNoHeapPointers将超出切片当前长度的位置清空并在最后使用memmove将原数组内存中的内容拷贝到新申请的内存中。
runtime.growslice函数最终会返回一个新的 slice 结构,其中包含了新的数组指针、大小和容量,这个返回的三元组最终会改变原有的切片,帮助 append 完成元素追加的功能。
示例:
var arr []int64arr = append(arr, 1, 2, 3, 4, 5)fmt.Println(cap(arr))当我们执行如上所示的代码时,会触发 runtime.growslice 函数扩容 arr 切片并传入期望的新容量 5,这时期望分配的内存大小为 40 字节;不过因为切片中的元素大小等于 sys.PtrSize,所以运行时会调用 runtime.roundupsize 对内存的大小向上取整 48 字节,所以经过计算新切片的容量为 48 / 8 = 6 。
拷贝切片
切片的拷贝虽然不是一个常见的操作类型,但是却是我们学习切片实现原理必须要谈及的一个问题,当我们使用 copy(a, b) 的形式对切片进行拷贝时,编译期间的 cmd/compile/internal/gc.copyany 函数也会分两种情况进行处理,如果当前 copy 不是在运行时调用的,copy(a, b) 会被直接转换成下面的代码:
n := len(a)if n > len(b) { n = len(b)}if a.ptr != b.ptr { memmove(a.ptr, b.ptr, n*sizeof(elem(a))) }其中 memmove 会负责对内存进行拷贝,在其他情况下,编译器会使用 runtime.slicecopy 函数替换运行期间调用的 copy,例如:go copy(a, b):
func slicecopy(to, fm slice, width uintptr) int { if fm.len == 0 || to.len == 0 { return 0 } n := fm.len if to.len < n { n = to.len } if width == 0 { return n } ... size := uintptr(n) * width if size == 1 { *(*byte)(to.array) = *(*byte)(fm.array) } else { memmove(to.array, fm.array, size) } return n}上述函数的实现非常直接,两种不同的拷贝方式一般都会通过 memmove将整块内存中的内容拷贝到目标的内存区域中。
迭代切片
slice := []int{1, 2, 3, 4, 5}for index, value := range slice { value += 10 fmt.Printf("index:%d value:%d", index, value)}fmt.Println(slice) // {1, 2, 3, 4, 5}==var value intfor index := 0; index < len(slice); index ++ { value = slice[index] }函数间传递切片
slice := make([]int, 1e6)slice = foo(slice)func foo(slice []int) []int { ... return slice}在64位架构的机器上,一个切片需要24字节内存,数组指针、长度、容量分别占用8字节,在函数间传递24字节数据会非常快速简单,这也是切片效率高的原因。
映射
映射是一种数据结构,用于存储一系列无序的键值对。
映射是一个集合,可以使用类似处理数组和切片的方式迭代,但映射是无序的集合,每次迭代映射的时候顺序也可能不一样。
创建和初始化
dict := make(map[string]int) dict := map[string]string{"Red":"#da1337", "Orange":"#e95a22"} //字面量方式使用映射
colors := make(map[string]string) //创建一个空映射colors["Red"] = "#da1337" //赋值var colors map[string]stringcolors["Red"] = "#da1337" //errorvalue, ok := colors["Blue"] //判断键是否存在if ok { fmt.Println(value)}value := colors["Blue"] //判断读取到的值是否空值if value != "" { fmt.Println(value)}函数间传递映射
func removeColor(colors map[string]string, key string) { delete(colors, key)}func main(){ colors := map[string]string{ "AliceBlue" : "#f0f8ff", "Coral" : "#ff7F50", } for key, value := range colors { fmt.Printf("Key: %s Value: %s", key, value) } removeColor(colors, "Coral") for key, value := range colors { fmt.Printf("Key: %s Value: %s", key, value) }}内存模型
Go语言采用的是哈希查找表,并且使用链表解决哈希冲突。
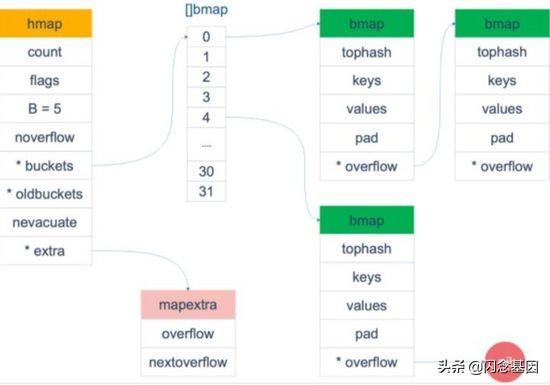
// hashmap的简称type hmap struct { count int //元素个数 flags uint8 //标记位 B uint8 //buckets的对数 log_2 noverflow uint16 //overflow的bucket的近似数 hash0 uint32 //hash种子 buckets unsafe.Pointer //指向buckets数组的指针,数组个数为2^B oldbuckets unsafe.Pointer //扩容时使用,buckets长度是oldbuckets的两倍 nevacuate uintptr //扩容进度,小于此地址的buckets已经迁移完成 extra *mapextra //扩展信息}//当map的key和value都不是指针,并且size都小于128字节的情况下,会把 bmap 标记为不含指针,这样可以避免gc时扫描整个hmap。但是,我们看bmap其实有一个overflow的字段,是指针类型的,破坏了bmap不含指针的设想,这时会把overflow移动到extra字段来。type mapextra struct { overflow *[]*bmap oldoverflow *[]*bmap nextOverflow *bmap}// buckettype bmap struct { tophash [bucketCnt]uint8 //bucketCnt = 8 // keys [8]keytype // values [8]valuetype // pad uintptr // overflow uintptr}bmap就是桶的数据结构,每个桶最多存储8个key-value对,所有的key都是经过hash后有相同的尾部,在桶内,根据hash值的高8位来决定桶中的位置。
注意到key和value是各自在一起的,不是key/value/key/value/...的方式,这样的好处是某些情况下可以省略padding字段,节省内存空间
如map[int64]int8,按照key/value/key/value/... 这样的模式存储,每一个key/value对之后都要额外 padding7个字节;而将所有的key,value 分别绑定到一起,key/key/.../value/value/...,只需在最后添加padding。
每个bucket设计成最多只能放8个key-value对,如果有第9个 key-value落入当前的bucket,那就需要再构建一个bucket,通过overflow指针连接起来。

map的扩容
装载因子:loadFactor := count / (2^B) count是map中元素的个数,2^B表示bucket数量
符合下面两个条件会触发扩容: 1)装载因子超过阈值:源码里定义的阈值为6.5 2)overflow的bucket数量过多:当B>15时,overflow的bucket数量超过2^15^,否则超过2^B^
增加桶搬迁示例:
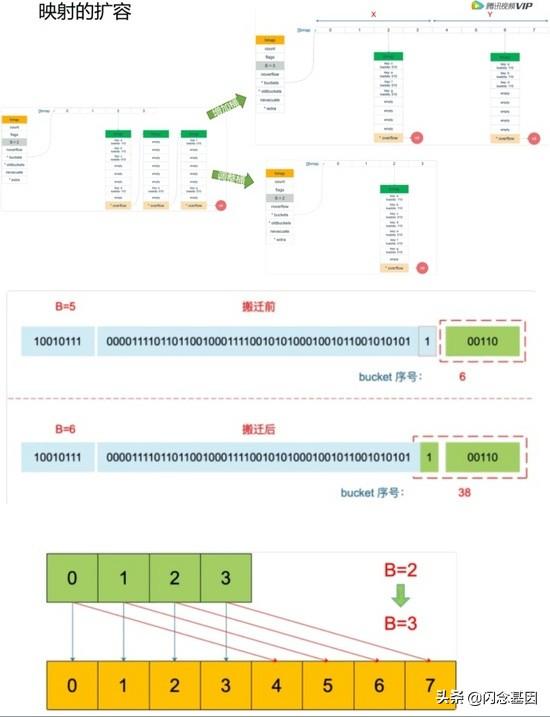
const ( bucketCntBits = 3 bucketCnt = 1 << bucketCntBits loadFactorNum = 13 loadFactorDen = 2)func bucketShift(b uint8) uintptr { return uintptr(1) << (b & (sys.PtrSize*8 - 1))}func overLoadFactor(count int, B uint8) bool { return count > bucketCnt && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)}func tooManyOverflowBuckets(noverflow uint16, B uint8) bool { if B > 15 { B = 15 } return noverflow >= uint16(1)< newbit { stop = newbit } for h.nevacuate != stop && bucketEvacuated(t, h, h.nevacuate) { h.nevacuate++ } if h.nevacuate == newbit { // newbit == # of oldbuckets // 搬迁完成,释放旧的桶数据 h.oldbuckets = nil if h.extra != nil { h.extra.oldoverflow = nil } h.flags &^= sameSizeGrow }}map的创建
//注:go:nosplit该指令指定文件中声明的下一个函数不得包含堆栈溢出检查。简单来讲,就是这个函数跳过堆栈溢出的检查//go:nosplit 快速得到随机数 参考论文:https://www.jstatsoft.org/article/view/v008i14/xorshift.pdffunc fastrand() uint32 { mp := getg().m s1, s0 := mp.fastrand[0], mp.fastrand[1] s1 ^= s1 << 17 s1 = s1 ^ s0 ^ s1>>7 ^ s0>>16 mp.fastrand[0], mp.fastrand[1] = s0, s1 return s0 + s1}func makemap(t *maptype, hint int, h *hmap) *hmap { mem, overflow := math.MulUintptr(uintptr(hint), t.bucket.size) if overflow || mem > maxAlloc { hint = 0 } // 初始化 if h == nil { h = new(hmap) } h.hash0 = fastrand() // 计算合适的桶个数B B := uint8(0) for overLoadFactor(hint, B) { B++ } h.B = B // 分配哈希表 if h.B != 0 { var nextOverflow *bmap h.buckets, nextOverflow = makeBucketArray(t, h.B, nil) if nextOverflow != nil { h.extra = new(mapextra) h.extra.nextOverflow = nextOverflow } } return h}// makeBucketArray initializes a backing array for map buckets.func makeBucketArray(t *maptype, b uint8, dirtyalloc unsafe.Pointer) ( buckets unsafe.Pointer, nextOverflow *bmap) { base := bucketShift(b) nbuckets := base // 对于比较小的b,不额外申请过载空间 if b >= 4 { nbuckets += bucketShift(b - 4) sz := t.bucket.size * nbuckets up := roundupsize(sz) if up != sz { nbuckets = up / t.bucket.size } } if dirtyalloc == nil { buckets = newarray(t.bucket, int(nbuckets)) } else { buckets = dirtyalloc size := t.bucket.size * nbuckets if t.bucket.ptrdata != 0 { memclrHasPointers(buckets, size) } else { memclrNoHeapPointers(buckets, size) } } if base != nbuckets { nextOverflow = (*bmap)(add(buckets, base*uintptr(t.bucketsize))) last := (*bmap)(add(buckets, (nbuckets-1)*uintptr(t.bucketsize))) last.setoverflow(t, (*bmap)(buckets)) } return buckets, nextOverflow}key的定位
key经过hash后得到一个64位整数,使用最后B位判断该key落入到哪个桶中,如果桶相同,说明有hash碰撞,在该桶中遍历寻找,采用hash值的高8位来快速比较,来看一个示例:
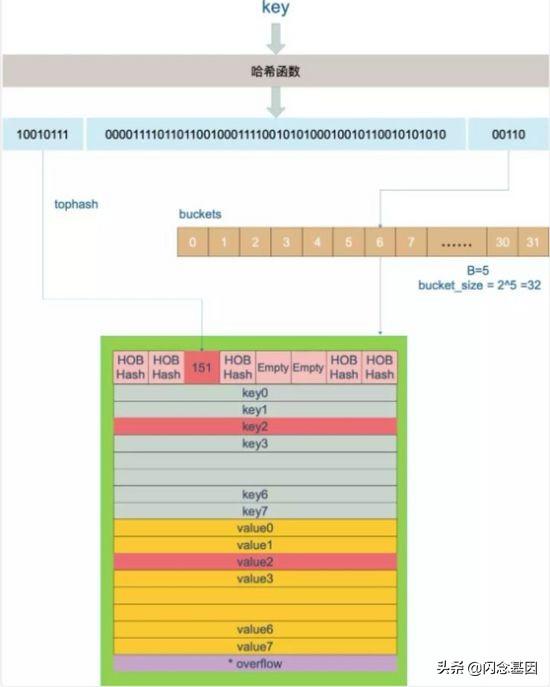
再来看一下源码:
const ( emptyRest = 0 // this cell is empty, and there are no more non-empty cells at higher indexes or overflows. emptyOne = 1 // this cell is empty evacuatedX = 2 // key/elem is valid. Entry has been evacuated to first half of larger table. evacuatedY = 3 // same as above, but evacuated to second half of larger table. evacuatedEmpty = 4 // cell is empty, bucket is evacuated. minTopHash = 5 // minimum tophash for a normal filled cell)//计算hash值的高8位func tophash(hash uintptr) uint8 { top := uint8(hash >> (sys.PtrSize*8 - 8)) if top < minTopHash { top += minTopHash } return top}//p指针偏移x位func add(p unsafe.Pointer, x uintptr) unsafe.Pointer { return unsafe.Pointer(uintptr(p) + x)}const PtrSize = 4 << (^uintptr(0) >> 63) // 64位环境下是 8//获取下一个桶节点func (b *bmap) overflow(t *maptype) *bmap { return *(**bmap)(add(unsafe.Pointer(b), uintptr(t.bucketsize)-sys.PtrSize))}//判断是否搬迁完成func evacuated(b *bmap) bool { h := b.tophash[0] return h > emptyOne && h < minTopHash}func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer{}func mapaccess2(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, bool){}func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer { // ...... //h为空或数量为0返回空值 if h == nil || h.count == 0 { if t.hashMightPanic() { t.hasher(key, 0) // see issue https://github.com/golang/go/issues/23734 } return unsafe.Pointer(&zeroVal[0]) } //读写冲突 if h.flags&hashWriting != 0 { throw("concurrent map read and map write") } //对请求key计算hash值 hash := t.hasher(key, uintptr(h.hash0)) //获取桶的掩码,如B=5,m=31即二进制(11111) m := bucketMask(h.B) //定位到对应的桶 b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize))) //判断是否处于扩容中 if c := h.oldbuckets; c != nil { if !h.sameSizeGrow() { // There used to be half as many buckets; mask down one more power of two. m >>= 1 } oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize))) if !evacuated(oldb) { b = oldb } } //计算hash值的前8位 top := tophash(hash)bucketloop: for ; b != nil; b = b.overflow(t) { for i := uintptr(0); i < bucketCnt; i++ { if b.tophash[i] != top { if b.tophash[i] == emptyRest { break bucketloop } continue } //定位到key的位置 k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize)) if t.indirectkey() { //对于指针需要解引用 k = *((*unsafe.Pointer)(k)) } if t.key.equal(key, k) { //定位到value的位置 e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize)) if t.indirectelem() { //对于指针需要解引用 e = *((*unsafe.Pointer)(e)) } return e } } } return unsafe.Pointer(&zeroVal[0])}map的赋值
const hashWriting = 4 // a goroutine is writing to the map// 判断是否是空节点func isEmpty(x uint8) bool { return x <= emptyOne // x <= 1}func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer { if h == nil { panic(plainError("assignment to entry in nil map")) } //省略条件判断 if h.flags&hashWriting != 0 { throw("concurrent map writes") } hash := t.hasher(key, uintptr(h.hash0)) // Set hashWriting after calling t.hasher, since t.hasher may panic, // in which case we have not actually done a write. h.flags ^= hashWriting if h.buckets == nil { h.buckets = newobject(t.bucket) // newarray(t.bucket, 1) }again: bucket := hash & bucketMask(h.B) if h.growing() { growWork(t, h, bucket) } b := (*bmap)(add(h.buckets, bucket*uintptr(t.bucketsize))) top := tophash(hash) var inserti *uint8 var insertk unsafe.Pointer var elem unsafe.Pointerbucketloop: for { for i := uintptr(0); i < bucketCnt; i++ { if b.tophash[i] != top { if isEmpty(b.tophash[i]) && inserti == nil { inserti = &b.tophash[i] insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize)) elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize)) } if b.tophash[i] == emptyRest { break bucketloop } continue } k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize)) if t.indirectkey() { k = *((*unsafe.Pointer)(k)) } if !t.key.equal(key, k) { continue } // already have a mapping for key. Update it. if t.needkeyupdate() { typedmemmove(t.key, k, key) } elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize)) goto done } ovf := b.overflow(t) if ovf == nil { break } b = ovf } //没有找到key,需要分配空间,先判断是否需要扩容,需扩容则重新计算 if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) { hashGrow(t, h) goto again // Growing the table invalidates everything, so try again } if inserti == nil { newb := h.newoverflow(t, b) inserti = &newb.tophash[0] insertk = add(unsafe.Pointer(newb), dataOffset) elem = add(insertk, bucketCnt*uintptr(t.keysize)) } // store new key/elem at insert position if t.indirectkey() { kmem := newobject(t.key) *(*unsafe.Pointer)(insertk) = kmem insertk = kmem } if t.indirectelem() { vmem := newobject(t.elem) *(*unsafe.Pointer)(elem) = vmem } typedmemmove(t.key, insertk, key) *inserti = top h.count++done: if h.flags&hashWriting == 0 { throw("concurrent map writes") } h.flags &^= hashWriting if t.indirectelem() { elem = *((*unsafe.Pointer)(elem)) } return elem}map的删除
func mapdelete(t *maptype, h *hmap, key unsafe.Pointer) { //... 忽略检查 if h == nil || h.count == 0 { if t.hashMightPanic() { t.hasher(key, 0) // see issue 23734 } return } if h.flags&hashWriting != 0 { throw("concurrent map writes") } hash := t.hasher(key, uintptr(h.hash0)) // Set hashWriting after calling t.hasher, since t.hasher may panic, // in which case we have not actually done a write (delete). h.flags ^= hashWriting bucket := hash & bucketMask(h.B) if h.growing() { growWork(t, h, bucket) } b := (*bmap)(add(h.buckets, bucket*uintptr(t.bucketsize))) bOrig := b top := tophash(hash)search: for ; b != nil; b = b.overflow(t) { for i := uintptr(0); i < bucketCnt; i++ { if b.tophash[i] != top { if b.tophash[i] == emptyRest { //遍历到最后仍未找到 break search } continue } k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize)) k2 := k if t.indirectkey() { k2 = *((*unsafe.Pointer)(k2)) } if !t.key.equal(key, k2) { //比较key是否一致 continue } // Only clear key if there are pointers in it. if t.indirectkey() { *(*unsafe.Pointer)(k) = nil } else if t.key.ptrdata != 0 { memclrHasPointers(k, t.key.size) } e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize)) if t.indirectelem() { *(*unsafe.Pointer)(e) = nil } else if t.elem.ptrdata != 0 { memclrHasPointers(e, t.elem.size) } else { memclrNoHeapPointers(e, t.elem.size) } //将tophash标记置为空值 b.tophash[i] = emptyOne if i == bucketCnt-1 { if b.overflow(t) != nil && b.overflow(t).tophash[0] != emptyRest { goto notLast } } else { if b.tophash[i+1] != emptyRest { goto notLast } } for { b.tophash[i] = emptyRest if i == 0 { if b == bOrig { break // beginning of initial bucket, we're done. } // Find previous bucket, continue at its last entry. c := b for b = bOrig; b.overflow(t) != c; b = b.overflow(t) { } i = bucketCnt - 1 } else { i-- } if b.tophash[i] != emptyOne { break } } notLast: h.count-- // Reset the hash seed to make it more difficult for attackers to // repeatedly trigger hash collisions. See issue 25237. if h.count == 0 { h.hash0 = fastrand() } break search } } if h.flags&hashWriting == 0 { throw("concurrent map writes") } h.flags &^= hashWriting}map的遍历
先来看个示例: 从红色位置开始,先遍历3号桶的e,然后是3号桶链接的f和g,接着遍历到0号桶,由于0号桶未搬迁,只遍历其中属于0号桶的b和c,接着到1号桶的h,最后是2号桶的a和d。

遍历结果:e->f->g->b->c->h->a->d
源码执行流程图:

// 哈希遍历结构体type hiter struct { key unsafe.Pointer // Must be in first position. Write nil to indicate iteration end (see cmd/compile/internal/gc/range.go). elem unsafe.Pointer // Must be in second position (see cmd/compile/internal/gc/range.go). t *maptype h *hmap buckets unsafe.Pointer // bucket ptr at hash_iter initialization time bptr *bmap // current bucket overflow *[]*bmap // keeps overflow buckets of hmap.buckets alive oldoverflow *[]*bmap // keeps overflow buckets of hmap.oldbuckets alive startBucket uintptr // bucket iteration started at offset uint8 // intra-bucket offset to start from during iteration (should be big enough to hold bucketCnt-1) wrapped bool // already wrapped around from end of bucket array to beginning B uint8 i uint8 bucket uintptr checkBucket uintptr}func mapiterinit(t *maptype, h *hmap, it *hiter) { if raceenabled && h != nil { callerpc := getcallerpc() racereadpc(unsafe.Pointer(h), callerpc, funcPC(mapiterinit)) } if h == nil || h.count == 0 { return } if unsafe.Sizeof(hiter{})/sys.PtrSize != 12 { throw("hash_iter size incorrect") // see cmd/compile/internal/gc/reflect.go } it.t = t it.h = h it.B = h.B it.buckets = h.buckets if t.bucket.ptrdata == 0 { h.createOverflow() it.overflow = h.extra.overflow it.oldoverflow = h.extra.oldoverflow } // 定位到随机位置 r := uintptr(fastrand()) if h.B > 31-bucketCntBits { r += uintptr(fastrand()) << 31 } it.startBucket = r & bucketMask(h.B) it.offset = uint8(r >> h.B & (bucketCnt - 1)) it.bucket = it.startBucket if old := h.flags; old&(iterator|oldIterator) != iterator|oldIterator { atomic.Or8(&h.flags, iterator|oldIterator) } mapiternext(it)}func mapiternext(it *hiter) { h := it.h if raceenabled { callerpc := getcallerpc() racereadpc(unsafe.Pointer(h), callerpc, funcPC(mapiternext)) } if h.flags&hashWriting != 0 { throw("concurrent map iteration and map write") } t := it.t bucket := it.bucket b := it.bptr i := it.i checkBucket := it.checkBucketnext: if b == nil { if bucket == it.startBucket && it.wrapped { // end of iteration it.key = nil it.elem = nil return } if h.growing() && it.B == h.B { oldbucket := bucket & it.h.oldbucketmask() b = (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize))) if !evacuated(b) { checkBucket = bucket } else { b = (*bmap)(add(it.buckets, bucket*uintptr(t.bucketsize))) checkBucket = noCheck } } else { b = (*bmap)(add(it.buckets, bucket*uintptr(t.bucketsize))) checkBucket = noCheck } bucket++ if bucket == bucketShift(it.B) { bucket = 0 it.wrapped = true } i = 0 } for ; i < bucketCnt; i++ { offi := (i + it.offset) & (bucketCnt - 1) if isEmpty(b.tophash[offi]) || b.tophash[offi] == evacuatedEmpty { continue } k := add(unsafe.Pointer(b), dataOffset+uintptr(offi)*uintptr(t.keysize)) if t.indirectkey() { k = *((*unsafe.Pointer)(k)) } e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+uintptr(offi)*uintptr(t.elemsize)) if checkBucket != noCheck && !h.sameSizeGrow() { if t.reflexivekey() || t.key.equal(k, k) { hash := t.hasher(k, uintptr(h.hash0)) if hash&bucketMask(it.B) != checkBucket { continue } } else { if checkBucket>>(it.B-1) != uintptr(b.tophash[offi]&1) { continue } } } if (b.tophash[offi] != evacuatedX && b.tophash[offi] != evacuatedY) || !(t.reflexivekey() || t.key.equal(k, k)) { it.key = k if t.indirectelem() { e = *((*unsafe.Pointer)(e)) } it.elem = e } else { rk, re := mapaccessK(t, h, k) if rk == nil { continue // key has been deleted } it.key = rk it.elem = re } it.bucket = bucket if it.bptr != b { // avoid unnecessary write barrier; see issue 14921 it.bptr = b } it.i = i + 1 it.checkBucket = checkBucket return } b = b.overflow(t) i = 0 goto next}管道
基本概念
不要通过共享内存来通信,而要通过通信来实现内存共享。 Do not communicate by sharing memory; instead, share memory by communicating.
chan T // 声明一个双向通道chan示例
func goRoutineA(a 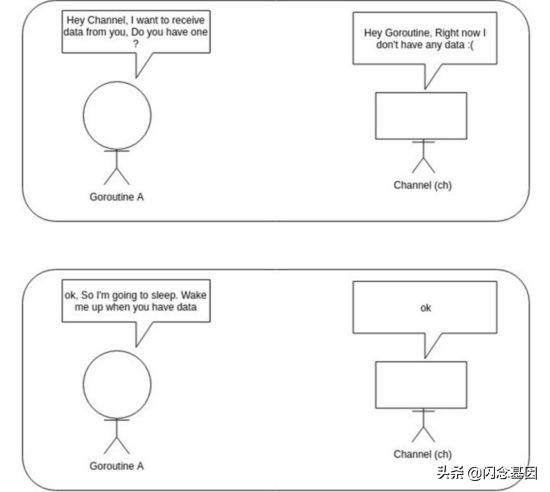
数据结构
// 管道type hchan struct { qcount uint // 元素的数量 dataqsiz uint // 缓冲区的大小 buf unsafe.Pointer // 指向缓冲区的指针 elemsize uint16 // 每个元素的大小 closed uint32 // 管道状态 elemtype *_type // 元素类型 sendx uint // 发送的索引 recvx uint // 接收的索引 recvq waitq // 等待接收的队列 sendq waitq // 等待发送的队列 lock mutex //互斥锁}// 等待队列type waitq struct { first *sudog last *sudog}type sudog struct { g *g next *sudog prev *sudog elem unsafe.Pointer // data element (may point to stack) ... isSelect bool ... c *hchan // channel}func goroutineA(a 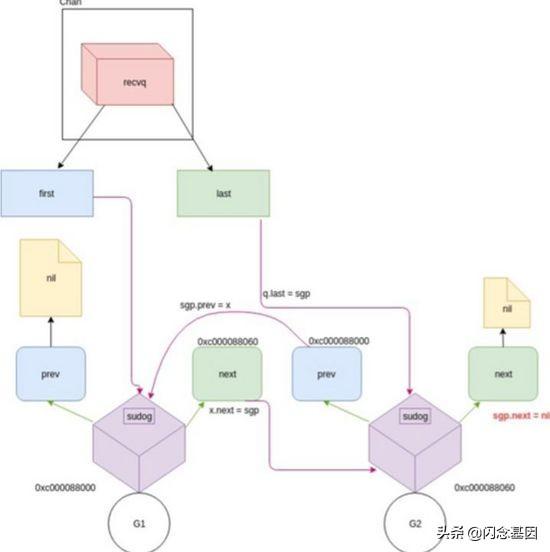
chan的创建
const ( maxAlign = 8 hchanSize = unsafe.Sizeof(hchan{}) + uintptr(-int(unsafe.Sizeof(hchan{}))&(maxAlign-1)))func makechan(t *chantype, size int) *hchan { elem := t.elem // ... 忽略检查和对齐 mem, overflow := math.MulUintptr(elem.size, uintptr(size)) if overflow || mem > maxAlloc-hchanSize || size < 0 { panic(plainError("makechan: size out of range")) } var c *hchan switch { case mem == 0: // 无缓冲区,只分配chan c = (*hchan)(mallocgc(hchanSize, nil, true)) // 用于竞态检测 c.buf = c.raceaddr() case elem.ptrdata == 0: // 元素不包含指针,一次调用分配chan和缓冲区 c = (*hchan)(mallocgc(hchanSize+mem, nil, true)) c.buf = add(unsafe.Pointer(c), hchanSize) default: // 元素包含指针,两次调用分配 c = new(hchan) c.buf = mallocgc(mem, elem, true) } c.elemsize = uint16(elem.size) c.elemtype = elem c.dataqsiz = uint(size) lockInit(&c.lock, lockRankHchan) return c}chan的接收
ch := make(chan int, 3)ch 0 { t0 = cputicks() } lock(&c.lock) if c.closed != 0 && c.qcount == 0 { // ... 忽略竞态检查 unlock(&c.lock) if ep != nil { typedmemclr(c.elemtype, ep) } return true, false } //等待发送队列里有goroutine存在,调用recv函数处理 if sg := c.sendq.dequeue(); sg != nil { recv(c, sg, ep, func() { unlock(&c.lock) }, 3) return true, true } // 缓冲型,buf里有元素,可以正常接收 if c.qcount > 0 { // 直接从循环数组里找到要接收的元素 qp := chanbuf(c, c.recvx) // ... 忽略竞态检查 if ep != nil { typedmemmove(c.elemtype, ep, qp) } // 清理掉循环数组里相应位置的值 typedmemclr(c.elemtype, qp) // 接收游标向前移动 c.recvx++ // 接收游标归零 if c.recvx == c.dataqsiz { c.recvx = 0 } // buf 数组里的元素个数减 1 c.qcount-- unlock(&c.lock) return true, true } if !block { // 非阻塞接收,解锁。selected返回false,因为没有接收到值 unlock(&c.lock) return false, false } // 接下来就是处理要被阻塞的情况,构造一个sudog gp := getg() mysg := acquireSudog() mysg.releasetime = 0 if t0 != 0 { mysg.releasetime = -1 } // 待接收数据的地址保存下来 mysg.elem = ep mysg.waitlink = nil gp.waiting = mysg mysg.g = gp mysg.isSelect = false mysg.c = c gp.param = nil // 进入channel 的等待接收队列 c.recvq.enqueue(mysg) // 将当前 goroutine 挂起 atomic.Store8(&gp.parkingOnChan, 1) gopark(chanparkcommit, unsafe.Pointer(&c.lock), waitReasonChanReceive, traceEvGoBlockRecv, 2) // 被唤醒了,接着从这里继续执行一些扫尾工作 if mysg != gp.waiting { throw("G waiting list is corrupted") } gp.waiting = nil gp.activeStackChans = false if mysg.releasetime > 0 { blockevent(mysg.releasetime-t0, 2) } success := mysg.success gp.param = nil mysg.c = nil releaseSudog(mysg) return true, success}chanrecv接收管道c,将接收到的数据写入到ep 如果ep为空,则忽略接收到的数据 如果block == false,且没有元素就绪,返回(false, false) 否则,如果c关闭了,将ep置0,返回(true, false) 否则,将接收到的数据填充到ep中,返回(true, true)
func recv(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) { if c.dataqsiz == 0 { // ... 忽略竞态检查 if ep != nil { // 直接拷贝数据,从 sender goroutine -> receiver goroutine recvDirect(c.elemtype, sg, ep) } } else { // 缓冲型的 channel,但 buf 已满。 // 将循环数组 buf 队首的元素拷贝到接收数据的地址 // 将发送者的数据入队。实际上这时 revx 和 sendx 值相等 // 找到接收游标 qp := chanbuf(c, c.recvx) // ... 忽略竞态检查 // 将接收游标处的数据拷贝给接收者 if ep != nil { typedmemmove(c.elemtype, ep, qp) } // 将发送者数据拷贝到 buf typedmemmove(c.elemtype, qp, sg.elem) // 更新游标值 c.recvx++ if c.recvx == c.dataqsiz { c.recvx = 0 } c.sendx = c.recvx // c.sendx = (c.sendx+1) % c.dataqsiz } sg.elem = nil gp := sg.g unlockf() gp.param = unsafe.Pointer(sg) sg.success = true if sg.releasetime != 0 { sg.releasetime = cputicks() } // 唤醒发送的 goroutine。需要等到调度器的光临 goready(gp, skip+1)}func recvDirect(t *_type, sg *sudog, dst unsafe.Pointer) { src := sg.elem typeBitsBulkBarrier(t, uintptr(dst), uintptr(src), t.size) memmove(dst, src, t.size)}管道的发送
//判断缓冲区是否满了,有两种可能// 1. channel 是非缓冲型的,且等待接收队列里没有 goroutine// 2. channel 是缓冲型的,但循环数组已经装满了元素func full(c *hchan) bool { if c.dataqsiz == 0 { return c.recvq.first == nil } return c.qcount == c.dataqsiz}func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool { if c == nil { if !block { return false } gopark(nil, nil, waitReasonChanSendNilChan, traceEvGoStop, 2) throw("unreachable") } // ... 忽略竞态检查 // 对于不阻塞的 send,快速检测失败场景 // 如果channel未关闭且channel没有多余的缓冲空间,返回false if !block && c.closed == 0 && full(c) { return false } var t0 int64 if blockprofilerate > 0 { t0 = cputicks() } //加锁 lock(&c.lock) //尝试向已经关闭的channel发送数据会触发panic if c.closed != 0 { unlock(&c.lock) panic(plainError("send on closed channel")) } // 如果接收队列里有goroutine,直接将要发送的数据拷贝到接收goroutine if sg := c.recvq.dequeue(); sg != nil { send(c, sg, ep, func() { unlock(&c.lock) }, 3) return true } // 对于缓冲型的channel,如果还有缓冲空间 if c.qcount < c.dataqsiz { // qp指向buf的sendx位置 qp := chanbuf(c, c.sendx) // ... 忽略竞态检查 // 将数据从ep处拷贝到qp typedmemmove(c.elemtype, qp, ep) // 发送游标值加 1 c.sendx++ // 如果发送游标值等于容量值,游标值归0 if c.sendx == c.dataqsiz { c.sendx = 0 } // 缓冲区的元素数量加一 c.qcount++ // 解锁 unlock(&c.lock) return true } if !block { unlock(&c.lock) return false } // channel满了,发送方会被阻塞。接下来会构造一个sudog gp := getg() mysg := acquireSudog() mysg.releasetime = 0 if t0 != 0 { mysg.releasetime = -1 } mysg.elem = ep mysg.waitlink = nil mysg.g = gp mysg.isSelect = false mysg.c = c gp.waiting = mysg gp.param = nil // 当前 goroutine 进入发送等待队列 c.sendq.enqueue(mysg) // 当前 goroutine 被挂起 atomic.Store8(&gp.parkingOnChan, 1) gopark(chanparkcommit, unsafe.Pointer(&c.lock), waitReasonChanSend, traceEvGoBlockSend, 2) // 保持活跃 KeepAlive(ep) // 从这里开始被唤醒了(channel有机会可以发送了) if mysg != gp.waiting { throw("G waiting list is corrupted") } gp.waiting = nil gp.activeStackChans = false closed := !mysg.success gp.param = nil if mysg.releasetime > 0 { blockevent(mysg.releasetime-t0, 2) } mysg.c = nil releaseSudog(mysg) if closed { if c.closed == 0 { throw("chansend: spurious wakeup") } // 被唤醒后,channel关闭了,触发panic panic(plainError("send on closed channel")) } return true}func send(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) { // ... 忽略竞态检查 if sg.elem != nil { sendDirect(c.elemtype, sg, ep) sg.elem = nil } gp := sg.g unlockf() gp.param = unsafe.Pointer(sg) sg.success = true if sg.releasetime != 0 { sg.releasetime = cputicks() } goready(gp, skip+1)}func sendDirect(t *_type, sg *sudog, src unsafe.Pointer) { // src 在当前 goroutine 的栈上,dst 是另一个 goroutine 的栈 // 直接进行内存"搬迁" // 如果目标地址的栈发生了栈收缩,当我们读出了 sg.elem 后 // 就不能修改真正的 dst 位置的值了 // 因此需要在读和写之前加上一个屏障 dst := sg.elem typeBitsBulkBarrier(t, uintptr(dst), uintptr(src), t.size) memmove(dst, src, t.size)}管道的关闭
func closechan(c *hchan) { // 关闭空channel会触发panic if c == nil { panic(plainError("close of nil channel")) } lock(&c.lock) if c.closed != 0 { unlock(&c.lock) // 关闭已经关闭的channel会触发panic panic(plainError("close of closed channel")) } // ... 忽略竞态检查 //设置管道已关闭 c.closed = 1 var glist gList // 将channel所有等待接收队列的里sudog释放 for { sg := c.recvq.dequeue() if sg == nil { break } // 如果elem不为空,说明此receiver未忽略接收数据 // 给它赋一个相应类型的零值 if sg.elem != nil { typedmemclr(c.elemtype, sg.elem) sg.elem = nil } if sg.releasetime != 0 { sg.releasetime = cputicks() } gp := sg.g gp.param = unsafe.Pointer(sg) sg.success = false // ... 忽略竞态检查 glist.push(gp) } // 将channel所有等待发送队列的里sudog释放 for { sg := c.sendq.dequeue() if sg == nil { break } sg.elem = nil if sg.releasetime != 0 { sg.releasetime = cputicks() } gp := sg.g gp.param = unsafe.Pointer(sg) sg.success = false // ... 忽略竞态检查 glist.push(gp) } unlock(&c.lock) // 遍历链表执行释放 for !glist.empty() { gp := glist.pop() gp.schedlink = 0 goready(gp, 3) }}管道的使用
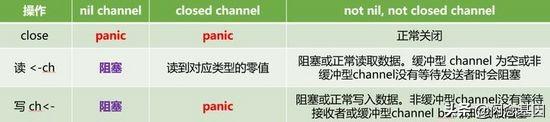
参考文献
- 《Go语言实战》
- 《Go语言学习笔记》
- 《Go并发编程实战》
- 《Go语言核心编程》
- 《Go程序设计语言》
- go语言源码
- 深度解密Go语言之slice
- 深度解密Go语言之map
- 深度解密Go语言之channel
- Go 语言设计与实现
- Diving Deep Into The Golang Channels
- 并发与并行 · Concurrency in Go 中文笔记 · 看云
出处:https://zhuanlan.zhihu.com/p/341945051














 7229
7229











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









