







(一)学习率 learning_rate
学习率 learning_rate : 表示了每次参数更新的幅度大小 。
学习率过大,会导致待优化的参数在最小值附近波动 ,不收敛 ;
学习率过小, 会导致 待优化的参数收敛缓慢 。
在训练过程中, 参数的更新向着损失函数梯度下降的方向。
参数的更新公式:

例子讲解:

假设损失函数为 :
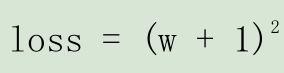
梯度是损失函数 loss 的导数为 ∇=2w+2。如参数初值为 5,学习率为 0.2,则参数和损失函数更新如下:

损失函数 loss的图像为:
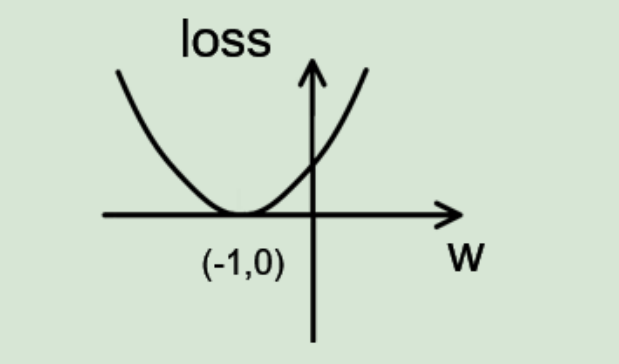
由图可知,损失函数 loss 的最小值会在(-1,0)处得到,此时损失函数的导数为 0,得到最终参数 w =-1。代码如下:
import tensorflow as tf
# 定义待优化参数w初值:5
w = tf.Variable(tf.constant(5, dtype=tf.float32))
# 定义损失函数loss
loss = tf.square(w+1)
# 定义损失函数loss
train_op = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
# 生成会话,训练40轮
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
for i in range(40):
sess.run(train_op)
w_val = sess.run(w)
loss_val = sess.run(loss)
print("after %s steps : w is %f, loss is % f : " % (i, w_val, loss_val))输出结果:
after 0 steps : w is 3.800000, loss is 23.040001.
after 1 steps : w is 2.840000, loss is 14.745600.
after 2 steps : w is 2.072000, loss is 9.437184.
after 3 steps : w is 1.457600, loss is 6.039798.
after 4 steps : w is 0.966080, loss is 3.865470.
after 5 steps : w is 0.572864, loss is 2.473901.
after 6 steps : w is 0.258291, loss is 1.583297.
after 7 steps : w is 0.006633, loss is 1.013310.
after 8 steps : w is -0.194694, loss is 0.648518.
after 9 steps : w is -0.355755, loss is 0.415052.
after 10 steps : w is -0.484604, loss is 0.265633.
after 11 steps : w is -0.587683, loss is 0.170005.
after 12 steps : w is -0.670147, loss is 0.108803.
after 13 steps : w is -0.736117, loss is 0.069634.
after 14 steps : w is -0.788894, loss is 0.044566.
after 15 steps : w is -0.831115, loss is 0.028522.
after 16 steps : w is -0.864892, loss is 0.018254.
after 17 steps : w is -0.891914, loss is 0.011683.
after 18 steps : w is -0.913531, loss is 0.007477.
after 19 steps : w is -0.930825, loss is 0.004785.
after 20 steps : w is -0.944660, loss is 0.003063.
after 21 steps : w is -0 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2942
2942











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









