







我正在做一个开源的中文车牌识别系统,Git地址为:https://github.com/liuruoze/EasyPR。
我给它取的名字为EasyPR,也就是Easy to do Plate Recognition的意思。我开发这套系统的主要原因是因为我希望能够锻炼我在这方面的能力,包括C++技术、计算机图形学、机器学习等。我把这个项目开源的主要目的是:1.它基于开源的代码诞生,理应回归开源;2.我希望有人能够一起协助强化这套系统,包括代码、训练数据等,能够让这套系统的准确性更高,鲁棒性更强等等。
相比于其他的车牌识别系统,EasyPR有如下特点:
- 它基于openCV这个开源库,这意味着所有它的代码都可以轻易的获取。
- 它能够识别中文,例如车牌为苏EUK722的图片,它可以准确地输出std:string类型的"苏EUK722"的结果。
- 它的识别率较高。目前情况下,字符识别已经可以达到90%以上的精度。
系统还提供全套的训练数据提供(包括车牌检测的近500个车牌和字符识别的4000多个字符)。所有全部都可以在Github的项目地址上直接下载到。
那么,EasyPR是如何产生的呢?我简单介绍一下它的诞生过程:
首先,在5月份左右时我考虑要做一个车牌识别系统。这个车牌系统中所有的代码都应该是开源的,不能基于任何黑盒技术。这主要起源于我想锻炼自己的C++和计算机视觉的水平。
我在网上开始搜索了资料。由于计算机视觉中很多的算法我都是使用openCV,而且openCV发展非常良好,因此我查找的项目必须得是基于OpenCV技术的。于是我在CSDN的博客上找了一篇文章。
文章的作者taotao1233在这两篇博客中以半学习笔记半开发讲解的方式说明了一个车牌识别系统的全部开发过程。非常感谢他的这些博客,借助于这些资料,我着手开始了开发。当时的想法非常朴素,就是想看看按照这些资料,能否真的实现一个车牌识别的系统。关于车牌照片数据的问题,幸运的很,我正在开发的一个项目中有大量的照片,因此数据不是问题。
令人高兴的是,系统确实能够工作,但是让人沮丧的,似乎也就“仅仅”能够工作而已。在车牌检测这个环节中正确性已经惨不忍睹。
这个事情给了我一拨不小的冷水,本来我以为很快的开发进度看来是乐观过头了。于是我决定沉下心来,仔细研究他的系统实现的每一个过程,结合OpenCV的官网教程与API资料,我发现他的实现系统中有很多并不适合我目前在做的场景。
我手里的数据大部分是高速上的图像抓拍数据,其中每个车牌都偏小,而且模糊度较差。直接使用他们的方法,正确率低到了可怕的地步。于是我开始尝试利用openCv中的一些函数与功能,替代,增加,调优等等方法,不断的优化。这个过程很漫长,但是也有很多的积累。我逐渐发现,并且了解他系统中每一个步骤的目的,原理以及如果修改可以进行优化的方法。
在最终实现的代码中,我的代码已经跟他的原始代码有很多的不一样了,但是成功率大幅度上升,而且车牌的正确检测率不断被优化。在系列文章的后面,我会逐一分享这些优化的过程与心得。
最终我实现的系统与他的系统有以下几点不同:
- 他的系统代码基本上完全参照了《Mastering OpenCV with Practical Computer Vision Projects》这本书的代码,而这本书的代码是专门为西班牙车牌所开发的,因此不适合中文的环境。
- 他的系统的代码大部分是原始代码的搬迁,并没有做到优化与改进的地步。而我的系统中对原来的识别过程,做了很多优化步骤。
- 车牌识别中核心的机器学习算法的模型,他直接使用了原书提供的,而我这两个过程的模型是自己生成,而且模型也做了测试,作为开源系统的一部分也提供了出来。
尽管我和他的系统有这么多的不同,但是我们在根本的系统结构上是一致的。应该说,我们都是参照了“Mastering OpenCV”这本数的处理结构。在这点上,我并没有所“创新”,事实上,结果也证明了“Mastering OpenCV”上的车牌识别的处理逻辑,是一个实际有效的最佳处理流程。
“Mastering OpenCV”,包括我们的系统,都是把车牌识别划分为了两个过程:即车牌检测(Plate Detection)和字符识别(Chars Recognition)两个过程。可能有些书籍或论文上不是这样叫的,但是我觉得,这样的叫法更容易理解,也不容易搞混。
- 车牌检测(Plate Detection):对一个包含车牌的图像进行分析,最终截取出只包含车牌的一个图块。这个步骤的主要目的是降低了在车牌识别过程中的计算量。如果直接对原始的图像进行车牌识别,会非常的慢,因此需要检测的过程。在本系统中,我们使用SVM(支持向量机)这个机器学习算法去判别截取的图块是否是真的“车牌”。
- 字符识别(Chars Recognition):有的书上也叫Plate Recognition,我为了与整个系统的名称做区分,所以改为此名字。这个步骤的主要目的就是从上一个车牌检测步骤中获取到的车牌图像,进行光学字符识别(OCR)这个过程。其中用到的机器学习算法是著名的人工神经网络(ANN)中的多层感知机(MLP)模型。最近一段时间非常火的“深度学习”其实就是多隐层的人工神经网络,与其有非常紧密的联系。通过了解光学字符识别(OCR)这个过程,也可以知晓深度学习所基于的人工神经网路技术的一些内容。
下图是一个完整的EasyPR的处理流程:

本开源项目的目标客户群有三类:
- 需要开发一个车牌识别系统的(开发者)。
- 需要车牌系统去识别车牌的(用户)。
- 急于做毕业设计的(学生)。
第一类客户是本项目的主要使用者,因此项目特地被精心划分为了6个模块,以供开发者按需选择。
第二类客户可能会有部分,EasyPR有一个同级项目EasyPR_Dll,可以DLL方式嵌入到其他的程序中,另外还有个一个同级项目EasyPR_Win,基于WTL开发的界面程序,可以简化与帮助车牌识别的结果比对过程。
对于第三类客户,可以这么说,有完整的全套代码和详细的说明,我相信你们可以稍作修改就可以通过设计大考。
推荐你使用EasyPR有以下几点理由:
- 这里面的代码都是作者亲自优化过的,你可以在上面做修改,做优化,甚至一起协作开发,一些处理车牌的细节方法你应该是感兴趣的。
- 如果你对代码不感兴趣,那么经过作者精心训练的模型,包括SVM和ANN的模型,可以帮助你提升或验证你程序的正确率。
- 如果你对模型也不感兴趣,那么成百上千经过作者亲自挑选的训练数据生成的文件,你应该感兴趣。作者花了大量的时间处理这些训练数据与调整,现在直接提供给你,可以大幅度减轻很多人缺少数据的难题。
有兴趣的同志可以留言或发Email:[email protected] 或者直接在Git上发起pull requet,都可以,未来我会在cnblogs上发布更多的关于系统的介绍,包括编码过程,训练心得。
在上篇文档中作者已经简单的介绍了EasyPR,现在在本文档中详细的介绍EasyPR的开发过程。
正如淘宝诞生于一个购买来的LAMP系统,EasyPR也有它诞生的原型,起源于CSDN的taotao1233的一个博客,博主以读书笔记的形式记述了通过阅读“Mastering OpenCV”这本书完成的一个车牌系统的雏形。
这个雏形有几个特点:1.将车牌系统划分为了两个过程,即车牌检测和字符识别。2.整个系统是针对西班牙的车牌开发的,与中文车牌不同。3.系统的训练模型来自于原书。作者基于这个系统,诞生了开发一个适用于中文的,且适合与协作开发的开源车牌系统的想法,也就是EasyPR。
当然了,现在车牌系统满大街都是,随便上下百度首页都是大量的广告,一些甚至宣称自己实现了99%的识别率。那么,作者为什么还要开发这个系统呢?这主要是基于时势与机遇的原因。
众所皆知,现在是大数据的时代。那么,什么是大数据?可能有些人认为这个只是一个概念或着炒作。但是大数据确是实实在在有着基础理论与科学研究背景的一门技术,其中包含着分布式计算、内存计算、机器学习、计算机视觉、语音识别、自然语言处理等众多计算机界崭新的技术,而且是这些技术综合的产物。事实上,大数据的“大”包含着4个特征,即4V理念,包括Volume(体量)、Varity(多样性)、Velocity(速度)、Value(价值)。
见下图的说明:

图1 大数据技术的4V特征
综上,大数据技术不仅包含数据量的大,也包含处理数据的复杂,和处理数据的速度,以及数据中蕴含的价值。而车牌识别这个系统,虽然传统,古老,却是包含了所有这四个特侦的一个大数据技术的缩影。
在车牌识别中,你需要处理的数据是图像中海量的像素单元;你处理的数据不再是传统的结构化数据,而是图像这种复杂的数据;如果不能在很短的时间内识别出车牌,那么系统就缺少意义;虽然一副图像中有很多的信息,但可能仅仅只有那一小块的信息(车牌)以及车身的颜色是你关心,而且这些信息都蕴含着巨大的价值。也就是说,车牌识别系统事实上就是现在火热的大数据技术在某个领域的一个聚焦,通过了解车牌识别系统,可以很好的帮助你理解大数据技术的内涵,也能清楚的认识到大数据的价值。
很神奇吧,也许你觉得车牌识别系统很低端,这不是随便大街上都有的么,而你又认为大数据技术很高端,似乎高大上的感觉。其实两者本质上是一样的。另外对于觉得大数据技术是虚幻的炒作念头的同学,你们也可以了解一下车牌识别系统,就能知道大数据落在实地,事实上已经不知不觉进入我们的生活很长时间了,像一些其他的如抢票系统,语音助手等,都是大数据技术的真真切切的体现。所谓再虚幻的概念落到实处,就成了下里巴人,应该就是这个意思。所以对于炒概念要有所警觉,但是不能因此排除一切,要了解具体的技术内涵,才能更好的利用技术为我们服务。
除了帮忙我们更好的理解大数据技术,使我们跟的上时代,开发一个车牌系统还有其他原因。
那就是、现在的车牌系统,仍然还有许多待解决的挑战。这个可能很多同学有疑问,你别骗我,百度上我随便一搜都是99%,只要多少多少元,就可以99%。但是事实上,车牌识别系统业界一直都没有一个成熟的百分百适用的方案。一些90%以上的车牌识别系统都是跟高清摄像机做了集成,由摄像头传入的高分辨率图片进入识别系统,可以达到较高的识别率。但是如果图像分辨率一旦下来,或者图里的车牌脏了的话,那么很遗憾,识别率远远不如我们的肉眼。也就是说,距离真正的智能的车牌识别系统,目前已有的系统还有许多挑战。什么时候能够达到人眼的精度以及识别速率,估计那时候才算是完整成熟的。
那么,有同学问,就没有办法进一步优化了么。答案是有的,这个就需要谈到目前火热的深度学习与计算机视觉技术,使用多隐层的深度神经网络也许能够解决这个问题。但是目前EasyPR并没有采用这种技术,或许以后会采用。但是这个方向是有的。也就是说,通过研究车牌识别系统,也许会让你一领略当今人工智能与计算机视觉技术最尖端的研究方向,即深度学习技术。怎么样,听了是不是很心动?最后扯一下,前端时间非常火热Google大脑技术和百度深度学习研究院,都是跟深度学习相关的。
下图是一个深度学习(右)与传统技术(左)的对比,可以看出深度学习对于数据的分类能力的优势。

图2 深度学习(右)与PCA技术(左)的对比
总结一下:开发一个车牌识别系统可以让你了解最新的时势---大数据的内涵,同时,也有机遇让你了解最新的人工智能技术---深度学习。因此,不要轻易的小看这门技术中蕴含的价值。
好,谈价值就说这么多。现在,我简单的介绍一下EasyPR的具体过程。
在上一篇文档中,我们了解到EasyPR包括两个部分,但实际上为了更好进行模块化开发,EasyPR被划分成了六个模块,其中每个模块的准确率与速度都影响着整个系统。
具体说来,EasyPR中PlateDetect与CharsRecognize各包括三个模块。
PlateDetect包括的是车牌定位,SVM训练,车牌判断三个过程,见下图。
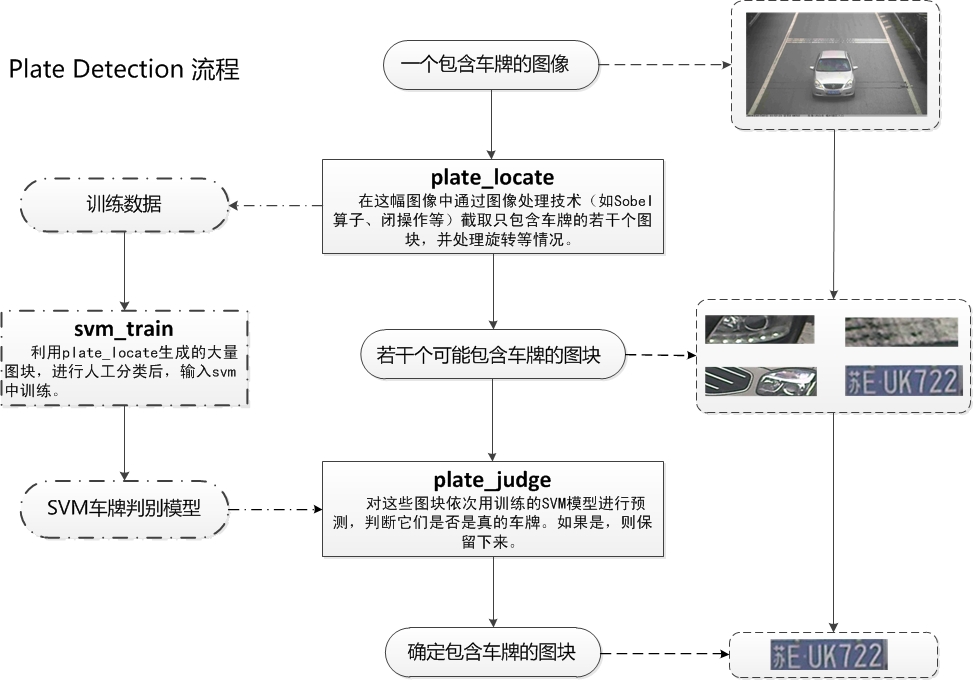
图3 PlateDetect过程详解
通过PlateDetect过程我们获得了许多可能是车牌的图块,将这些图块进行手工分类,聚集一定数量后,放入SVM模型中训练,得到SVM的一个判断模型,在实际的车牌过程中,我们再把所有可能是车牌的图块输入SVM判断模型,通过SVM模型自动的选择出实际上真正是车牌的图块。
PlateDetect过程结束后,我们获得一个图片中我们真正关心的部分--车牌。那么下一步该如何处理呢。下一步就是根据这个车牌图片,生成一个车牌号字符串的过程,也就是CharsRecognisze的过程。
CharsRecognise包括的是字符分割,ANN训练,字符识别三个过程,具体见下图。
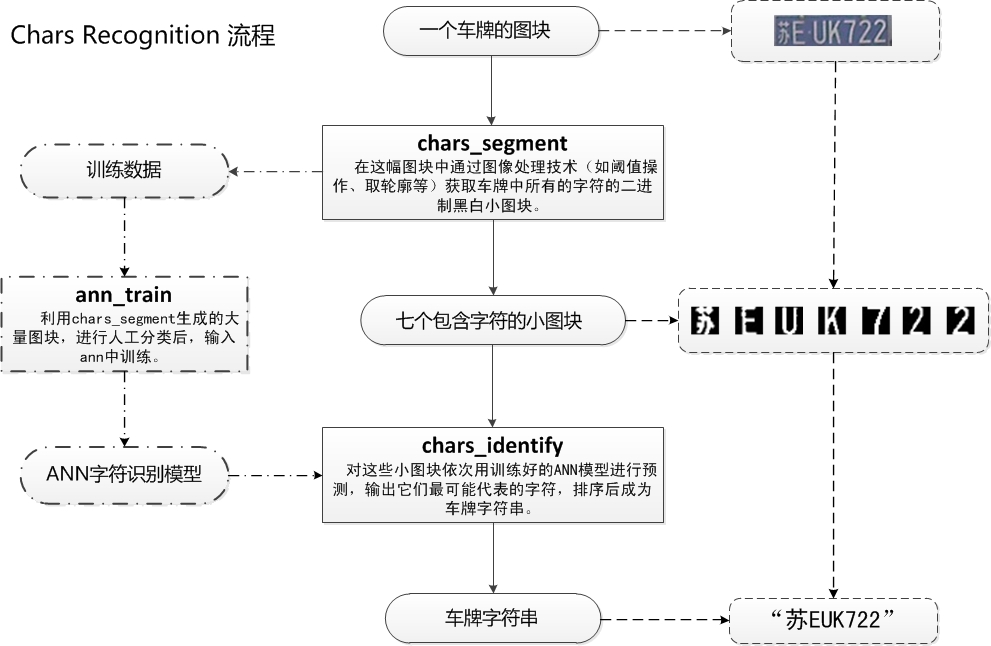
图4 CharsRecognise过程详解
在CharsRecognise过程中,一副车牌图块首先会进行灰度化,二值化,然后使用一系列算法获取到车牌的每个字符的分割图块。获得海量的这些字符图块后,进行手工分类(这个步骤非常耗时间,后面会介绍如何加速这个处理的方法),然后喂入神经网络(ANN)的MLP模型中,进行训练。在实际的车牌识别过程中,将得到7个字符图块放入训练好的神经网络模型,通过模型来预测每个图块所表示的具体字符,例如图片中就输出了“苏EUK722”,(这个车牌只是示例,切勿以为这个车牌有什么特定选取目标。车主既不是作者,也不是什么深仇大恨,仅仅为学术说明选择而已)。
至此一个完整的车牌识别过程就结束了,但是在每一步的处理过程中,有许多的优化方法和处理策略。尤其是车牌定位和字符分割这两块,非常重要,它们不仅生成实际数据,还生成训练数据,因此会直接影响到模型的准确性,以及模型判断的最终结果。这两部分会是作者重点介绍的模块,至于SVM模型与ANN模型,由于使用的是OpenCV提供的类,因此可以直接看openCV的源码或者机器学习介绍的书,来了解训练与判断过程。
好了,本期就介绍这么多。下面的篇章中作者会重点介绍其中每个模块的开发过程与内容,但是时间不定,可能几个星期发一篇吧。
最后,祝大家国庆快乐,阖家幸福!
这篇文章是一个系列中的第三篇。前两篇的地址贴下:介绍、详解1。我撰写这系列文章的目的是:1、普及车牌识别中相关的技术与知识点;2、帮助开发者了解EasyPR的实现细节;3、增进沟通。
EasyPR的项目地址在这:GitHub。要想运行EasyPR的程序,首先必须配置好openCV,具体可以参照这篇文章。
在前两篇文章中,我们已经初步了解了EasyPR的大概内容,在本篇内容中我们开始深入EasyRP的程序细节。了解EasyPR是如何一步一步实现一个车牌的识别过程的。根据EasyPR的结构,我们把它分为六个部分,前三个部分统称为“Plate Detect”过程。主要目的是在一副图片中发现仅包含车牌的图块,以此提高整体识别的准确率与速度。这个过程非常重要,如果这步失败了,后面的字符识别过程就别想了。而“Plate Detect”过程中的三个部分又分别称之为“Plate Locate” ,“SVM train”,“Plate judge”,其中最重要的部分是第一步“Plate Locate”过程。本篇文章中就是主要介绍“Plate Locate”过程,并且回答以下三个问题:
1.此过程的作用是什么,为什么重要?
2.此过程是如何实现车牌定位这个功能的?
3.此过程中的细节是什么,如何进行调优?
1.“Plate Locate”的作用与重要性
在说明“Plate Locate”的作用与重要性之前,请看下面这两幅图片。


图1 两幅包含车牌的不同形式图片
左边的图片是作者训练的图片(作者大部分的训练与测试都是基于此类交通抓拍图片),右边的图片则是在百度图片中“车牌”获得(这个图片也可以称之为生活照片)。右边图片的问题是一个网友评论时问的。他说EasyPR在处理百度图片时的识别率不高。确实如此,由于工业与生活应用目的不同,拍摄的车牌的大小,角度,色泽,清晰度不一样。而对图像处理技术而言,一些算法对于图像的形式以及结构都有一定的要求或者假设。因此在一个场景下适应的算法并不适用其他场景。目前EasyPR所有的功能都是基于交通抓拍场景的图片制作的,因此也就导致了其无法处理生活场景中这些车牌照片。
那么是否可以用一致的“Plate Locate”过程中去处理它?答案是也许可以,但是很难,而且最后即便处理成功,效率也许也不尽如人意。我的推荐是:对于不同的场景要做不同的适配。尽管“Plate Locate”过程无法处理生活照片的定位,但是在后面的字符识别过程中两者是通用的。可以对EasyPR的“Plate Locate”做改造,同时仍然使用整体架构,这样或许可以处理。
有一点事实值得了解到是,在生产环境中,你所面对的图片形式是固定的,例如左边的图片。你可以根据特定的图片形式来调优你的车牌程序,使你的程序对这类图片足够健壮,效率也够高。在上线以后,也有很好的效果。但当图片形式调整时,就必须要调整你的算法了。在“Plate Locate”过程中,有一些参数可以调整。如果通过调整这些参数就可以使程序良好工作,那最好不过。当这些参数也不能够满足需求时,就需要完全修改 EasyPR的实现代码,因此需要开发者了解EasyPR是如何实现plateLocate这一过程的。
在EasyPR中,“Plate Locate”过程被封装成了一个“CPlateLocate”类,通过“plate_locate.h”声明,在“plate_locate.cpp”中实现。
CPlateLocate包含三个方法以及数个变量。方法提供了车牌定位的主要功能,变量则提供了可定制的参数,有些参数对于车牌定位的效果有非常明显的影响,例如高斯模糊半径、Sobel算子的水平与垂直方向权值、闭操作的矩形宽度。CPlateLocate类的声明如下:

class CPlateLocate
{
public:
CPlateLocate();
//! 车牌定位
int plateLocate(Mat, vector<Mat>& );
//! 车牌的尺寸验证
bool verifySizes(RotatedRect mr);
//! 结果车牌显示
Mat showResultMat(Mat src, Size rect_size, Point2f center);
//! 设置与读取变量
//...
protected:
//! 高斯模糊所用变量
int m_GaussianBlurSize;
//! 连接操作所用变量
int m_MorphSizeWidth;
int m_MorphSizeHeight;
//! verifySize所用变量
float m_error;
float m_aspect;
int m_verifyMin;
int m_verifyMax;
//! 角度判断所用变量
int m_angle;
//! 是否开启调试模式,0关闭,非0开启
int m_debug;
};
注意,所有EasyPR中的类都声明在命名空间easypr内,这里没有列出。CPlateLocate中最核心的方法是plateLocate方法。它的声明如下:
//! 车牌定位
int plateLocate(Mat, vector<Mat>& );
方法有两个参数,第一个参数代表输入的源图像,第二个参数是输出数组,代表所有检索到的车牌图块。返回值为int型,0代表成功,其他代表失败。plateLocate内部是如何实现的,让我们再深入下看看。
2.“Plate Locate”的实现过程
plateLocate过程基本参考了taotao1233的博客的处理流程,但略有不同。
plateLocate的总体识别思路是:如果我们的车牌没有大的旋转或变形,那么其中必然包括很多垂直边缘(这些垂直边缘往往缘由车牌中的字符),如果能够找到一个包含很多垂直边缘的矩形块,那么有很大的可能性它就是车牌。
依照这个思路我们可以设计一个车牌定位的流程。设计好后,再根据实际效果进行调优。下面的流程是经过多次调整与尝试后得出的,包含了数月来作者针对测试图片集的一个最佳过程(这个流程并不一定适用所有情况)。plateLocate的实现代码在这里不贴了,Git上有所有源码。plateLocate主要处理流程图如下:

图2 plateLocate流程图
下面会一步一步参照上面的流程图,给出每个步骤的中间临时图片。这些图片可以在1.01版的CPlateLocate中设置如下代码开启调试模式。
CPlateLocate plate;
plate.setDebug(1);
临时图片会生成在tmp文件夹下。对多个车牌图片处理的结果仅会保留最后一个车牌图片的临时图片。
1、原始图片。

2、经过高斯模糊后的图片。经过这步处理,可以看出图像变的模糊了。这步的作用是为接下来的Sobel算子去除干扰的噪声。

3、将图像进行灰度化。这个步骤是一个分水岭,意味着后面的所有操作都不能基于色彩信息了。此步骤是利是弊,后面再做分析。

4、对图像进行Sobel运算,得到的是图像的一阶水平方向导数。这步过后,车牌被明显的区分出来。

5、对图像进行二值化。将灰度图像(每个像素点有256个取值可能)转化为二值图像(每个像素点仅有1和0两个取值可能)。

6、使用闭操作。对图像进行闭操作以后,可以看到车牌区域被连接成一个矩形装的区域。

7、求轮廓。求出图中所有的轮廓。这个算法会把全图的轮廓都计算出来,因此要进行筛选。

8、筛选。对轮廓求最小外接矩形,然后验证,不满足条件的淘汰。经过这步,仅仅只有六个黄色边框的矩形通过了筛选。

8、角度判断与旋转。把倾斜角度大于阈值(如正负30度)的矩形舍弃。左边第一、二、四个矩形被舍弃了。余下的矩形进行微小的旋转,使其水平。



10、统一尺寸。上步得到的图块尺寸是不一样的。为了进入机器学习模型,需要统一尺寸。统一尺寸的标准宽度是136,长度是36。这个标准是对千个测试车牌平均后得出的通用值。下图为最终的三个候选”车牌“图块。



这些“车牌”有两个作用:一、积累下来作为支持向量机(SVM)模型的训练集,以此训练出一个车牌判断模型;二、在实际的车牌检测过程中,将这些候选“车牌”交由训练好的车牌判断模型进行判断。如果车牌判断模型认为这是车牌的话就进入下一步即字符识别过程,如果不是,则舍弃。
3.“Plate Locate”的深入讨论与调优策略
好了,说了这么多,读者想必对整个“Plate Locate”过程已经有了一个完整的认识。那么让我们一步步审核一下处理流程中的每一个步骤。回答下面三个问题:这个步骤的作用是什么?省略这步或者替换这步可不可以?这个步骤中是否有参数可以调优的?通过这几个问题可以帮助我们更好的理解车牌定位功能,并且便于自己做修改、定制。
由于篇幅关系,下面的深入讨论放在下期
在上篇文章中我们了解了PlateLocate的过程中的所有步骤。在本篇文章中我们对前3个步骤,分别是高斯模糊、灰度化和Sobel算子进行分析。
一、高斯模糊
1.目标
对图像去噪,为边缘检测算法做准备。
2.效果
在我们的车牌定位中的第一步就是高斯模糊处理。

图1 高斯模糊效果
3.理论
详细说明可以看这篇:阮一峰讲高斯模糊。
高斯模糊是非常有名的一种图像处理技术。顾名思义,其一般应用是将图像变得模糊,但同时高斯模糊也应用在图像的预处理阶段。理解高斯模糊前,先看一下平均模糊算法。平均模糊的算法非常简单。见下图,每一个像素的值都取周围所有像素(共8个)的平均值。
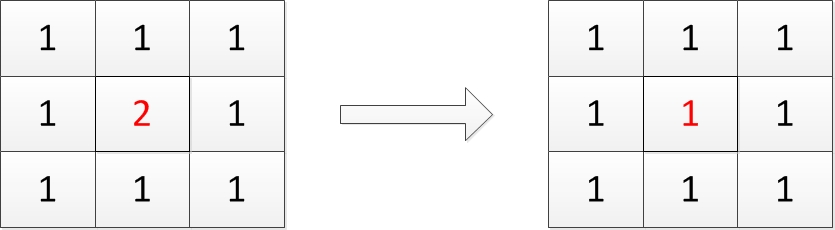
图2 平均模糊示意图
在上图中,左边红色点的像素值本来是2,经过模糊后,就成了1(取周围所有像素的均值)。在平均模糊中,周围像素的权值都是一样的,都是1。如果周围像素的权值不一样,并且与二维的高斯分布的值一样,那么就叫做高斯模糊。
在上面的模糊过程中,每个像素取的是周围一圈的平均值,也称为模糊半径为1。如果取周围三圈,则称之为半径为3。半径增大的话,会更加深模糊的效果。
4.实践
在PlateLocate中是这样调用高斯模糊的。
//高斯模糊。Size中的数字影响车牌定位的效果。
GaussianBlur( src, src_blur, Size(m_GaussianBlurSize, m_GaussianBlurSize),
0, 0, BORDER_DEFAULT );
其中Size字段的参数指定了高斯模糊的半径。值是CPlateLocate类的m_GaussianBlurSize变量。由于opencv的高斯模糊仅接收奇数的半径,因此变量为偶数值会抛出异常。
这里给出了opencv的高斯模糊的API(英文,2.48以上版本)。
高斯模糊这个过程一定是必要的么。笔者的回答是必要的,倘若我们将这句代码注释并稍作修改,重新运行一下。你会发现plateLocate过程在闭操作时就和原来发生了变化。最后结果如下。

图3 不采用高斯模糊后的结果
可以看出,车牌所在的矩形产生了偏斜。最后得到的候选“车牌”图块如下:








图4 不采用高斯模糊后的“车牌”图块
如果不使用高斯模糊而直接用边缘检测算法,我们得到的候选“车牌”达到了8个!这样不仅会增加车牌判断的处理时间,还增加了判断出错的概率。由于得到的车牌图块中车牌是斜着的,如果我们的字符识别算法需要一个水平的车牌图块,那么几乎肯定我们会无法得到正确的字符识别效果。
高斯模糊中的半径也会给结果带来明显的变化。有的图片,高斯模糊半径过高了,车牌就定位不出来。有的图片,高斯模糊半径偏低了,车牌也定位不出来。因此、高斯模糊的半径既不宜过高,也不能过低。CPlateLocate类中的值为5的静态常量DEFAULT_GAUSSIANBLUR_SIZE,标示着推荐的高斯模糊的半径。这个值是对于近千张图片经过测试后得出的综合定位率最高的一个值。在CPlateLocate类的构造函数中,m_GaussianBlurSize被赋予了DEFAULT_GAUSSIANBLUR_SIZE的值,因此,默认的高斯模糊的半径就是5。如果不是特殊情况,不需要修改它。
在数次的实验以后,必须承认,保留高斯模糊过程与半径值为5是最佳的实践。为应对特殊需求,在CPlateLocate类中也应该提供了方法修改高斯半径的值,调用代码(假设需要一个为3的高斯模糊半径)如下:
CPlateLocate plate;
plate.setGaussianBlurSize(3);
目前EasyPR的处理步骤是先进行高斯模糊,再进行灰度化。从目前的实验结果来看,基于色彩的高斯模糊过程比灰度后的高斯模糊过程更容易检测到边缘点。
二、灰度化处理
1.目标
为边缘检测算法准备灰度化环境。
2.效果
灰度化的效果如下。

图5 灰度化效果
3.理论
在灰度化处理步骤中,争议最大的就是信息的损失。无疑的,原先plateLocate过程面对的图片是彩色图片,而从这一步以后,就会面对的是灰度图片。在前面,已经说过这步骤是利是弊是需要讨论的。
无疑,对于计算机而言,色彩图像相对于灰度图像难处理多了,很多图像处理算法仅仅只适用于灰度图像,例如后面提到的Sobel算子。在这种情况下,你除 了把图片转成灰度图像再进行处理别无它法,除非重新设计算法。但另一方面,转化成灰度图像后恰恰失去了最丰富的细节。要知道,真实世界是彩色的,人类对于 事物的辨别是基于彩色的框架。甚至可以这样说,因为我们的肉眼能够区别彩色,所以我们对于事物的区
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 241
241











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









