






收集access.log数据到kafka集群
如果必要
清除原来的日志信息
xcall.sh "echo > /usr/local/openresty/nginx/logs/access.log"
开zk
开redis

开kafka

1 .kafka 主题
创建主题
kafka-topics.sh --zookeeper s102:2181 --partitions 4 --replication-factor 3 --create --topic big12-umeng-raw-logs

查看主题
kafka-topics.sh --zookeeper s102:2181 --list

创建kafka消费者 ----此步可以省略
kafka-console-consumer.sh --zookeeper s102:2181 --topic big12-umeng-raw-logs

2 配置flume,收集access.log文件到kafka集群

/soft/flume/conf sudo nano umeng_nginx_to_kafka.conf
flume配置文件
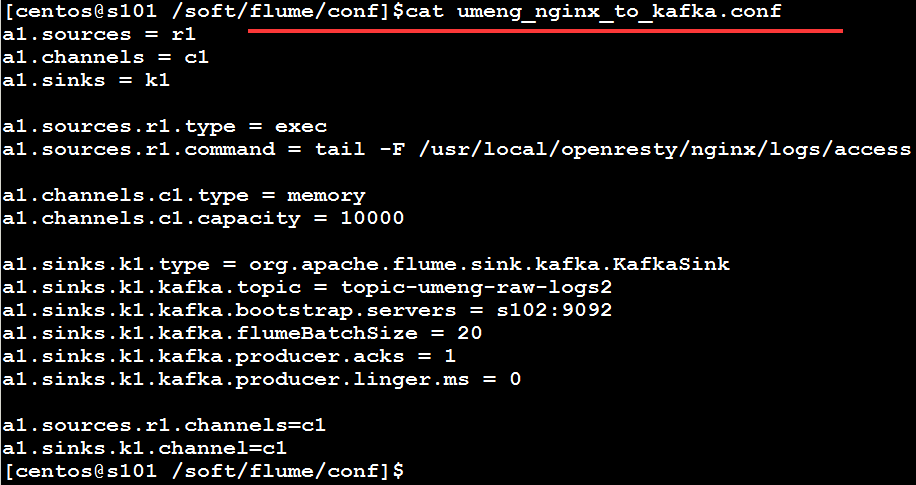
a1.sources = r1
a1.channels = c1
a1.sinks = k1
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /usr/local/openresty/nginx/logs/access.log
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = big12-umeng-raw-logs
a1.sinks.k1.kafka.bootstrap.servers = s102:9092
a1.sinks.k1.kafka.flumeBatchSize = 20
#acks 0:不需要回执 1:leader写入磁盘后回执 -1:所有节点写入磁盘后回执
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 0
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
发送配置文件到s102


3 .启动flume
s101-s102启动flume
flume-ng agent -f /soft/flume/conf/umeng_nginx_to_kafka.conf -n a1 &
















 1678
1678











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









