






1.调度器的概述
多任务操作系统分为非抢占式多任务和抢占式多任务。与大多数现代操作系统一样,Linux采用的是抢占式多任务模式。这表示对CPU的占用时间由操作系统决定的,具体为操作系统中的调度器。调度器决定了什么时候停止一个进程以便让其他进程有机会运行,同时挑选出一个其他的进程开始运行。
2.调度策略
在Linux上调度策略决定了调度器是如何选择一个新进程的时间。调度策略与进程的类型有关,内核现有的调度策略如下:
#define SCHED_NORMAL 0
#define SCHED_FIFO 1
#define SCHED_RR 2
#define SCHED_BATCH 3
/* SCHED_ISO: reserved but not implemented yet */
#define SCHED_IDLE 50: 默认的调度策略,针对的是普通进程。
1:针对实时进程的先进先出调度。适合对时间性要求比较高但每次运行时间比较短的进程。
2:针对的是实时进程的时间片轮转调度。适合每次运行时间比较长得进程。
3:针对批处理进程的调度,适合那些非交互性且对cpu使用密集的进程。
SCHED_ISO:是内核的一个预留字段,目前还没有使用
5:适用于优先级较低的后台进程。
注:每个进程的调度策略保存在进程描述符task_struct中的policy字段
3.调度器中的机制
内核引入调度类(struct sched_class)说明了调度器应该具有哪些功能。内核中每种调度策略都有该调度类的一个实例。(比如:基于公平调度类为:fair_sched_class,基于实时进程的调度类实例为:rt_sched_class),该实例也是针对每种调度策略的具体实现。调度类封装了不同调度策略的具体实现,屏蔽了各种调度策略的细节实现。
调度器核心函数schedule()只需要调用调度类中的接口,完成进程的调度,完全不需要考虑调度策略的具体实现。调度类连接了调度函数和具体的调度策略。
- 武特师兄关于sche_class和sche_entity的解释,一语中的。
- 调度类就是代表的各种调度策略,调度实体就是调度单位,这个实体通常是一个进程,但是自从引入了cgroup后,这个调度实体可能就不是一个进程了,而是一个组
4.schedule()函数
linux 支持两种类型的进程调度,实时进程和普通进程。实时进程采用SCHED_FIFO 和SCHED_RR调度策略,普通进程采用SCHED_NORMAL策略。
preempt_disable():禁止内核抢占
cpu_rq():获取当前cpu对应的就绪队列。
prev = rq->curr;获取当前进程的描述符prev
switch_count = &prev->nivcsw;获取当前进程的切换次数。
update_rq_clock() :更新就绪队列上的时钟
clear_tsk_need_resched()清楚当前进程prev的重新调度标志。
deactive_task():将当前进程从就绪队列中删除。
put_prev_task() :将当前进程重新放入就绪队列
pick_next_task():在就绪队列中挑选下一个将被执行的进程。
context_switch():进行prev和next两个进程的切换。具体的切换代码与体系架构有关,在switch_to()中通过一段汇编代码实现。
post_schedule():进行进程切换后的后期处理工作。
5.pick_next_task函数
选择下一个将要被执行的进程无疑是一个很重要的过程,我们来看一下内核中代码的实现
对以下这段代码说明:
1.当rq中的运行队列的个数(nr_running)和cfs中的nr_runing相等的时候,表示现在所有的都是普通进程,这时候就会调用cfs算法中的pick_next_task(其实是pick_next_task_fair函数),当不相等的时候,则调用sched_class_highest(这是一个宏,指向的是实时进程),这下面的这个for(;;)循环中,首先是会在实时进程中选取要调度的程序(p = class->pick_next_task(rq);)。如果没有选取到,会执行class=class->next;在class这个链表中有三种类型(fair,idle,rt).也就是说会调用到下一个调度类。
static inline struct task_struct *
pick_next_task(struct rq *rq)
{
const struct sched_class *class;
struct task_struct *p;
/*
* Optimization: we know that if all tasks are in
* the fair class we can call that function directly:
*/
//基于公平调度的普通进程
if (likely(rq->nr_running == rq->cfs.nr_running)) {
p = fair_sched_class.pick_next_task(rq);
if (likely(p))
return p;
}
//基于实时调度的实时进程
class = sched_class_highest;
for ( ; ; ) {
p = class->pick_next_task(rq); //实时进程的类
if (p)
return p;
/*
* Will never be NULL as the idle class always
* returns a non-NULL p:
*/
class = class->next; //rt->next = fair; fair->next = idle
}
}在这段代码中体现了Linux所支持的两种类型的进程,实时进程和普通进程。回顾下:实时进程可以采用SCHED_FIFO 和SCHED_RR调度策略,普通进程采用SCHED_NORMAL调度策略。
在这里首先说明一个结构体struct rq,这个结构体是调度器管理可运行状态进程的最主要的数据结构。每个cpu上都有一个可运行的就绪队列。刚才在pick_next_task函数中看到了在选择下一个将要被执行的进程时实际上用的是struct rq上的普通进程的调度或者实时进程的调度,那么具体是如何调度的呢?在实时调度中,为了实现O(1)的调度算法,内核为每个优先级维护一个运行队列和一个DECLARE_BITMAP,内核根据DECLARE_BITMAP的bit数值找出非空的最高级优先队列的编号,从而可以从非空的最高级优先队列中取出进程进行运行。
我们来看下内核的实现
struct rt_prio_array {
DECLARE_BITMAP(bitmap, MAX_RT_PRIO+1); /* include 1 bit for delimiter */
struct list_head queue[MAX_RT_PRIO];
};数组queue[i]里面存放的是优先级为i的进程队列的链表头。在结构体rt_prio_array 中有一个重要的数据构DECLARE_BITMAP,它在内核中的第一如下:
define DECLARE_BITMAP(name,bits) \
unsigned long name[BITS_TO_LONGS(bits)]5.1对于实时进程的O(1)算法
这个数据是用来作为进程队列queue[MAX_PRIO]的索引位图。bitmap中的每一位与queue[i]对应,当queue[i]的进程队列不为空时,Bitmap的相应位就为1,否则为0,这样就只需要通过汇编指令从进程优先级由高到低的方向找到第一个为1的位置,则这个位置就是就绪队列中最高的优先级(函数sched_find_first_bit()就是用来实现该目的的)。那么queue[index]->next就是要找的候选进程。
如果还是不懂,那就来看两个图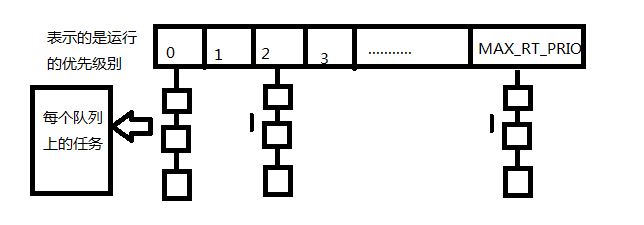
注:在每个队列上的任务一般基于先进先出的原则进行调度(并且为每个进程分配时间片)
在内核中的实现为:
static struct sched_rt_entity *pick_next_rt_entity(struct rq *rq,
struct rt_rq *rt_rq)
{
struct rt_prio_array *array = &rt_rq->active;
struct sched_rt_entity *next = NULL;
struct list_head *queue;
int idx;
idx = sched_find_first_bit(array->bitmap); //找到优先级最高的位
BUG_ON(idx >= MAX_RT_PRIO);
queue = array->queue + idx; //然后找到对应的queue的起始地址
next = list_entry(queue->next, struct sched_rt_entity, run_list); //按先进先出拿任务
return next;
}那么当同一优先级的任务比较多的时候,内核会根据
位图:
将对应的位置为1,每次取出最大的被置为1的位,表示优先级最高: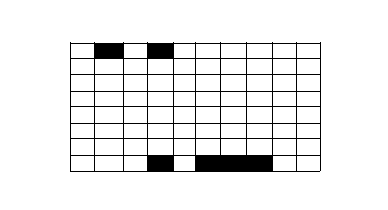
5.2 关于普通进程的CFS算法:
我们知道,普通进程在选取下一个需要被调度的进程时,是调用的pick_next_task_fair函数。在这个函数中是以调度实体为单位进行调度的。其最主要的函数是:pick_next_entity,在这个函数中会调用wakeup_preempt_entity函数,这个函数的主要作用是根据进程的虚拟时间以及权重的结算进程的粒度,以判断其是否需要抢占。看一下内核是怎么实现的:
wakeup_preempt_entity(struct sched_entity *curr, struct sched_entity *se)
{
s64 gran, vdiff = curr->vruntime - se->vruntime;//计算两个虚拟时间差
//如果se的虚拟时间比curr还大,说明本该curr执行,无需抢占
if (vdiff <= 0)
return -1;
gran = wakeup_gran(curr, se);
if (vdiff > gran)
return 1;
return 0;
}gran为需要抢占的时间差,只有两个时间差大于需要抢占的时间差,才需要抢占,这里避免太频繁的抢占
wakeup_gran(struct sched_entity *curr, struct sched_entity *se)
{
unsigned long gran = sysctl_sched_wakeup_granularity;
if (cfs_rq_of(curr)->curr && sched_feat(ADAPTIVE_GRAN))
gran = adaptive_gran(curr, se);
/*
* Since its curr running now, convert the gran from real-time
* to virtual-time in his units.
*/
if (sched_feat(ASYM_GRAN)) {
/*
* By using 'se' instead of 'curr' we penalize light tasks, so
* they get preempted easier. That is, if 'se' < 'curr' then
* the resulting gran will be larger, therefore penalizing the
* lighter, if otoh 'se' > 'curr' then the resulting gran will
* be smaller, again penalizing the lighter task.
*
* This is especially important for buddies when the leftmost
* task is higher priority than the buddy.
*/
if (unlikely(se->load.weight != NICE_0_LOAD))
gran = calc_delta_fair(gran, se);
} else {
if (unlikely(curr->load.weight != NICE_0_LOAD))
gran = calc_delta_fair(gran, curr);
}
return gran;
}6.调度中的nice值
首先需要明确的是:nice的值不是进程的优先级,他们不是一个概念,但是进程的Nice值会影响到进程的优先级的变化。
通过命令ps -el可以看到进程的nice值为NI列。PRI表示的是进程的优先级,其实进程的优先级只是一个整数,它是调度器选择进程运行的基础。
普通进程有:静态优先级和动态优先级。
静态优先级:之所有称为静态优先级是因为它不会随着时间而改变,内核不会修改它,只能通过系统调用nice去修改,静态优先级用进程描述符中的static_prio来表示。在内核中/kernel/sched.c中,nice和静态优先级的关系为:
#define NICE_TO_PRIO(nice) (MAX_RT_PRIO + (nice) + 20)
#define PRIO_TO_NICE(prio) ((prio) - MAX_RT_PRIO - 20)动态优先级:调度程序通过增加或者减小进程静态优先级的值来奖励IO小的进程或者惩罚cpu消耗型的进程。调整后的优先级称为动态优先级。在进程描述中用prio来表示,通常所说的优先级指的是动态优先级。
由上面分析可知,我们可以通过系统调用nice函数来改变进程的优先级。
#include <stdlib.h>
#include <stdio.h>
#include <math.h>
#include <unistd.h>
#include <sys/time.h>
#define JMAX (400*100000)
#define GET_ELAPSED_TIME(tv1,tv2) ( \
(double)( (tv2.tv_sec - tv1.tv_sec) \
+ .000001 * (tv2.tv_usec - tv1.tv_usec)))
//做一个延迟的计算
double do_something (void)
{
int j;
double x = 0.0;
struct timeval tv1, tv2;
gettimeofday (&tv1, NULL);//获取时区
for (j = 0; j < JMAX; j++)
x += 1.0 / (exp ((1 + x * x) / (2 + x * x)));
gettimeofday (&tv2, NULL);
return GET_ELAPSED_TIME (tv1, tv2);//求差值
}
int main (int argc, char *argv[])
{
int niceval = 0, nsched;
/* for kernels less than 2.6.21, this is HZ
for tickless kernels this must be the MHZ rate
e.g, for 2.6 GZ scale = 2600000000 */
long scale = 1000;
long ticks_cpu, ticks_sleep;
pid_t pid;
FILE *fp;
char fname[256];
double elapsed_time, timeslice, t_cpu, t_sleep;
if (argc > 1)
niceval = atoi (argv[1]);
pid = getpid ();
if (argc > 2)
scale = atoi (argv[2]);
/* give a chance for other tasks to queue up */
sleep (3);
sprintf (fname, "/proc/%d/schedstat", pid);//读取进程的调度状态
/*
在schedstat中的数字是什么意思呢?:
*/
/* printf ("Fname = %s\n", fname); */
if (!(fp = fopen (fname, "r"))) {
printf ("Failed to open stat file\n");
exit (-1);
}
//nice系统调用
if (nice (niceval) == -1 && niceval != -1) {
printf ("Failed to set nice to %d\n", niceval);
exit (-1);
}
elapsed_time = do_something ();//for 循环执行了多长时间
fscanf (fp, "%ld %ld %d", &ticks_cpu, &ticks_sleep, &nsched);//nsched表示调度的次数
t_cpu = (float)ticks_cpu / scale;//震动的次数除以1000,就是时间
t_sleep = (float)ticks_sleep / scale;
timeslice = t_cpu / (double)nsched;//除以调度的次数,就是每次调度的时间(时间片)
printf ("\nnice=%3d time=%8g secs pid=%5d"
" t_cpu=%8g t_sleep=%8g nsched=%5d"
" avg timeslice = %8g\n",
niceval, elapsed_time, pid, t_cpu, t_sleep, nsched, timeslice);
fclose (fp);
exit (0);
}
说明: 首先说明的是/proc/[pid]/schedstat:在这个文件下放着3个变量,他们分别代表什么意思呢?
- 第一个:该进程拥有的cpu的时间
- 第二个:在对列上的等待时间,即睡眠时间
- 第三个:被调度的次数

由结果可以看出当nice的值越小的时候,其睡眠时间越短,则表示其优先级升高了。
7.关于获取和设置优先级的系统调用:sched_getscheduler()和sched_setscheduler
#include <sched.h>
#include <stdlib.h>
#include <stdio.h>
#include <errno.h>
#define DEATH(mess) { perror(mess); exit(errno); }
void printpolicy (int policy)
{
/* SCHED_NORMAL = SCHED_OTHER in user-space */
if (policy == SCHED_OTHER)
printf ("policy = SCHED_OTHER = %d\n", policy);
if (policy == SCHED_FIFO)
printf ("policy = SCHED_FIFO = %d\n", policy);
if (policy == SCHED_RR)
printf ("policy = SCHED_RR = %d\n", policy);
}
int main (int argc, char **argv)
{
int policy;
struct sched_param p;
/* obtain current scheduling policy for this process */
//获取进程调度的策略
policy = sched_getscheduler (0);
printpolicy (policy);
/* reset scheduling policy */
printf ("\nTrying sched_setscheduler...\n");
policy = SCHED_FIFO;
printpolicy (policy);
p.sched_priority = 50;
//设置优先级为50
if (sched_setscheduler (0, policy, &p))
DEATH ("sched_setscheduler:");
printf ("p.sched_priority = %d\n", p.sched_priority);
exit (0);
}
输出结果:
[root@wang schedule]# ./get_schedule_policy
policy = SCHED_OTHER = 0
Trying sched_setscheduler...
policy = SCHED_FIFO = 1
p.sched_priority = 50
可以看出进程的优先级已经被改变。














 561
561











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









