






线性回归:
参考博客:http://blog.csdn.net/sxf1061926959/article/details/66976356
线性回归问题就是给点一些点,通过拟合一条直线使这些点到这条直线的距离最近,可以分为一元线性回归和多元线性回归,一元是指 y = mx + b,多元是指:y = m1x1 + m2x2 + b
拟合的直线与真实值的误差可以表示为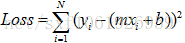
即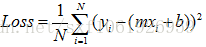
怎么去最小化误差?
我们要怎么去找到最能拟合数据的直线?即最小化误差呢?
一般有两个方法:
最小二乘法
上面我们讲了我们定义的损失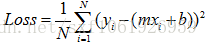
怎么求极值呢?
令每个变量的偏导数为零,求方程组的解呗,这个是很基础的高数问题了。
我们可以得到下面的方程组
然后就是巴拉巴拉巴拉把m和b求出来,这样就得到我们要的线性方程了。
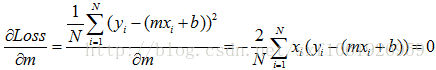
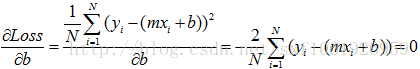
梯度下降法
没有梯度下降就没有现在的深度学习,这是一个神奇的算法。
最小二乘法可以一步到位,直接算出m和b,但他是有前提的,具体我有点记不清了,好像是需要满秩什么的。梯度下降法和最小二乘不一样,它通过一步一步的迭代,慢慢的去靠近到那条最优直线。
最小二乘法里面我们提到了两个偏导数,分别为
我们要去找Loss这个方程的最小值,最小值怎么求?按数学的求法就是最小二乘法呗,但是大家可以直观的想一下,很多地方都会用一个碗来形容,那我也找个碗来解释吧。
大家把这个Loss函数想象成这个碗,而我们要求的最小值就是碗底。假设我们现在不能用最小二乘法求极小值,但是我们的计算机的计算能量很强,我们可以用计算量换结果,不管我们位于这个碗的什么位置,只要我们想去碗底,就要往下走。
往下走????????
这个下不就是往梯度方向走吗,那我们沿着梯度一点一点滑下去呗,反正计算机不嫌累。梯度不就是上面那两个公式呗。现在梯度有了,那每次滑多远呢,一滑划过头了不久白算半天了吗,所以还得定义步长,用来表示每次滑多长。这样我们就能每次向下走一点点,再定义一个迭代值用来表示滑多少次,这样我们就能慢慢的一点点的靠近最小值了,不出意外还是能距离最优值很近的。
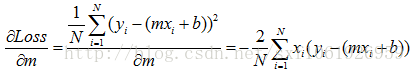
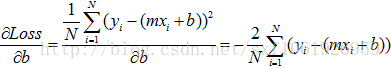

顺便把上面这个梯度下降法实现下
每次向下滑要慢慢滑,就是要个步长,我们定义为learning_rate,往往很小的一个值。
向下滑动的次数,就是迭代的次数,我定义为num_iter,相对learning_rate往往很大。
定义好这两个,我们就可以一边求梯度,一边向下滑了。就是去更新m和b。
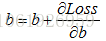
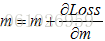
# -*- coding: utf-8 -*-
import pylab
import numpy as np
def compute_error(b, m, data):
totalError = 0
x = data[:, 0]
y = data[:, 1]
totalError = (y - m * x - b)**2
# print(totalError)
totalEror = np.sum(totalError, axis=0)
return totalEror / float(len(data))
def compute_gradient(b_cuurent, m_current, data, learning_rate):
b_gradient = 0
m_gradient = 0
N = float(len(data))
x = data[:, 0]
y = data[:, 1]
b_gradient = 2 / N * (m_current * x + b_cuurent - y)
b_gradient = np.sum(b_gradient, axis=0)
m_gradient = 2 / N * x * (m_current * x + b_cuurent - y)
m_gradient = np.sum(m_gradient, axis=0)
new_b = b_cuurent - (learning_rate * b_gradient)
new_w = m_current - (learning_rate * m_gradient)
return [new_b, new_w]
def optimizer(data, starting_b, starting_m, learning_rate, num_iter):
b = starting_b
m = starting_m
# gradient descent
for i in range(num_iter):
b, m = compute_gradient(b, m, data, learning_rate)
if i % 100 == 0:
print("iter {0}: error = {1}".format(i, compute_error(b, m, data)))
return [b, m]
def plot_data(data, b, m):
x = data[:, 0]
y = data[:, 1]
y_predict = m * x + b
pylab.plot(x, y, 'o')
pylab.plot(x, y_predict, 'k-')
pylab.show()
def Linear_regression():
# get train data
data = np.loadtxt("data", delimiter=",")
# print(data)
learning_rate = 0.001
initial_b = 0.0
initial_m = 0.0
num_iter = 1000
# train model
# print b,m,error
print("initial variables:\ninitial_b = {0}\nintial_m = {1}\nerror of begin = {2}\\n".format(initial_b, initial_m, compute_error(initial_b, initial_m, data)))
# optimizing b and m
[b, m] = optimizer(data, initial_b, initial_m, learning_rate, num_iter)
print("final formula parmaters:\n b = {1}\n m = {2} error of end = {3}\n".format(num_iter, b, m, compute_error(b, m, data)))
plot_data(data, b, m)
if __name__ == "__main__":
Linear_regression()















 265
265

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









