






一、Spark集群基础概念


将DAG划分为多个stage阶段,遵循以下原则:
1、将尽可能多的窄依赖关系的RDD划为同一个stage阶段。
2、当遇到shuffle操作,就意味着上一个stage阶段结束,下一个stage阶段开始
关于RDD中的分区,在默认情况下(也就是未指明分区数的情况)
1、如果从HDFS中读取数据创建RDD,在默认情况下
二、spark架构原理
1、Spark架构原理
Driver 进程
编写的Spark程序就在Driver上, 由Driver进程执行。
Driver可以是Spark集群的节点之一, 或者是提交Spark程序的机器
Master 进程
主要负责资源的调度和分配, 以及集群的监控等职责
Worker 进程
主要职责有两个:
用自己所在节点的内存存储RDD的partition
启动其他进程和线程, 对RDD的partition进行并行计算处理
Executor 进程
Executor接收到task之后, 会启动多个线程来执行task
task 线程
task会对RDD的partition数据执行指定的算子操作, 形成新RDD的 partition
小结:
Executor和task, 其实就是负责执行, 对RDD的partition进行并行的计算, 也就是执行我们对RDD定义的, 比如flatMap、 map、 reduce等算子操作。
2、spark架构

3、spark架构整体流程

4、Spark架构原理剖析
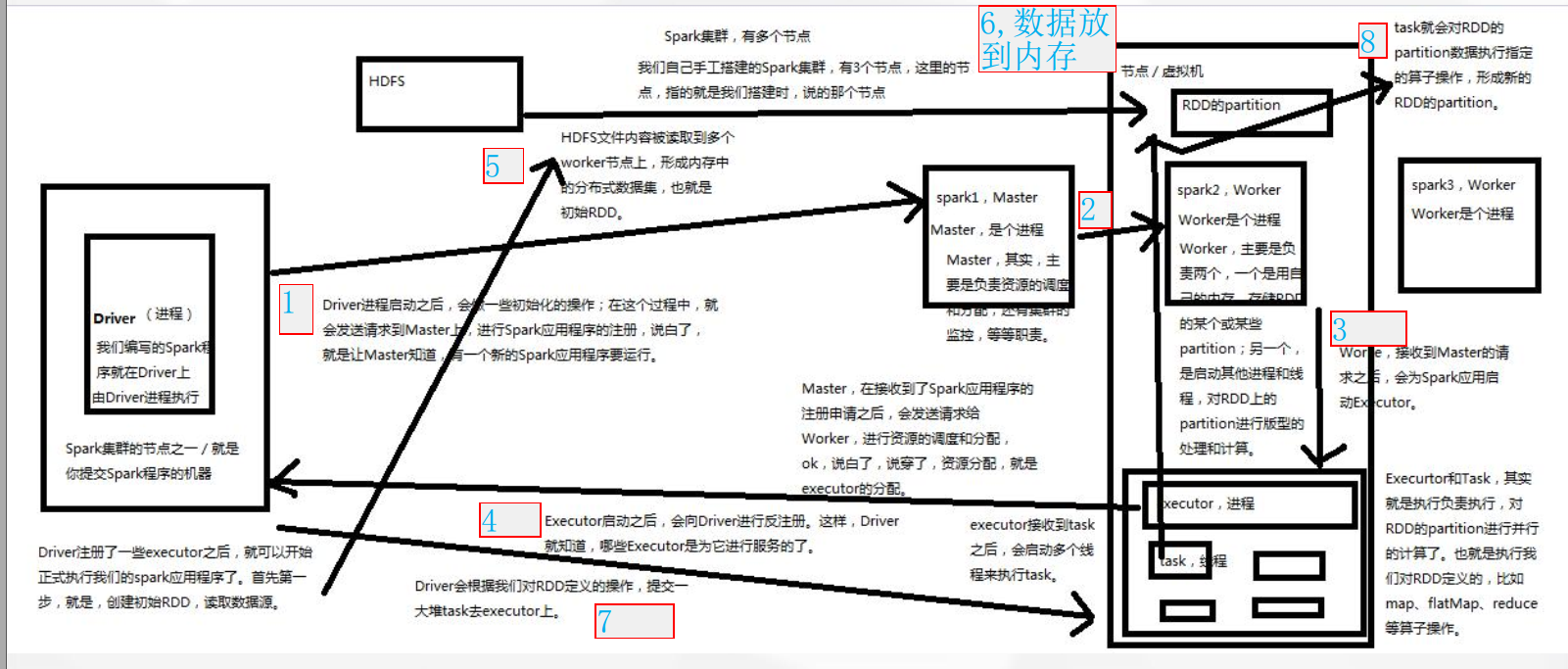
( driver—master——worker——executor—driver 前四步形成闭环 第五步执行程序,读取数据)
第一步:Driver进程启动之后,会做一些初始化的操作;在这个过程中,就会发送请求到master上,进行spark应用程序的注册,说白了,就是让master知道,有一个新的spark应用程序要运行
第二步:master,在接收到了spark应用程序的注册申请之后,或发送请求给worker,进行资源的调度和分配,OK,说白了资源分配就是executor的分配
第三步:worker接收到master的请求之后,会为spark应用启动executor
第四步:executor启动之后,会向Driver进行反注册,这样,Driver就知道哪些executor是为它进行服务的了
第五步:Driver注册了一些executor之后,就可以开始正式执行我们的spark应用程序了,首先第一个步就是创建初始RDD,读取数据源
第六步:RDD的分区数据放到内存中
第七步:Driver会根据我们对RDD定义的操作,提交一大堆task去executor上
第八步:task会对RDD的partition数据执行指定的算子操作,形成新的RDD的partition
5、spark架构原理深度剖析(Standalong模式)
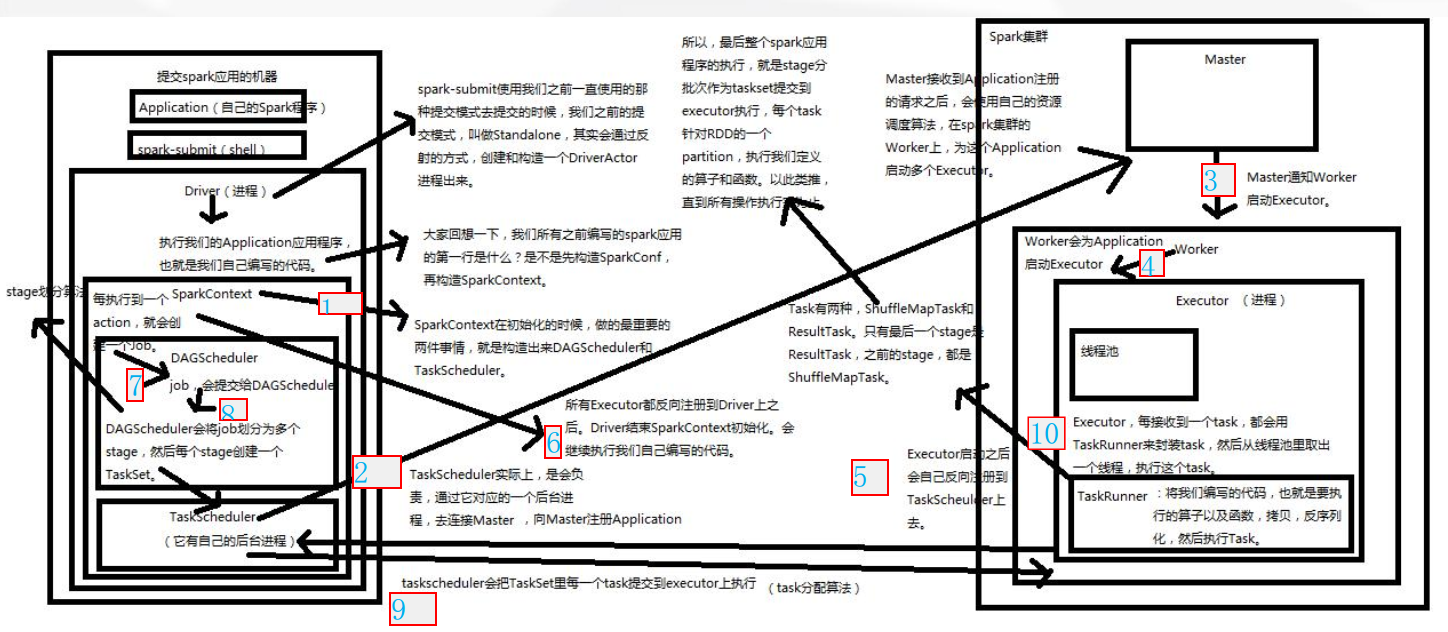
1、
通过spark-submit指令将打好的Spark jar包提交到Spark集群中运行。
先从Driver进程开始运行,Driver中包含了我们所编写的代码。
首先执行代码中的前两句,
val conf=new SparkConf().setAppName("AppOperate")
.setMaster("local")
val sc=new SparkContext(conf)
创建SparkConf和SparkContext对象,
在创建SparkContext对象的过程中,会去做两件很重要的事,就是
创建DAGScheduler和TaskScheduler这两个对象。
然后,TaskScheduler会通过一个后台进程负责与Master进行注册通信,
告诉Master有一个新的Application应用程序要运行,需要Master管理
分配调度集群的资源。
2、Master接收到TaskScheduler的注册请求之后,会通过资源调度算法对
集群资源进行调度,并且与Worker进行通信,请求Worker启动相应的Executor
3、Worker接收到Master的请求之后,会在本节点中启动Executor。
因为集群中有多个Worker节点,那么也意味着会启动多个Executor。
一个Application对应着Worker中的一个Executor。
4、Executor启动完成之后,会向Driver中的TaskScheduler进行反注册,
反注册的目的就是让Driver知道新提交的Application应用将由哪些Executor
负责执行。
5、Executor向Driver中的TaskScheduler反注册完成之后,就意味
着SparkContext的初始化过程已经完成,接下来去执行SparkContext
下面的代码。
6、
在SparkContext下面的代码中,创建了初始RDD,并对初始RDD进行了
Transformation类型的算子操作,但是系统只是记录下了这些操作行为,
这些操作行并没有真正的被执行,直到遇到Action类型的算子,触发
提交job之后,Action类型的算子之前所有的Transformation类型的
算子才会被执行。
job会被提交给DAGScheduler,DAGScheduler根据stage划分算法将
job划分为多个stage(阶段),并将其封装成TaskSet(任务集合),
然后将TaskSet提交给TaskScheduler。
7、TaskScheduler根据task分配算法,将TaskSet中的每一个小task分配
给Executor去执行。
8、Executor接受到task任务之后,通过taskrunner来封装一个task,
并从线程池中取出相应的一个线程来执行task。
task线程针对RDD partition分区中的数据进行指定的算子操作,
这些算子操作包括Transformation和Action类型的操作。
补充说明:
1)taskrunner(任务运行器),会对我们编写代码进行复制、反序列化
操作,进行执行task任务。
2)task分为两大类:ShuffleMapTask和ResultTask。最后一个stage
阶段中的task称为ResultTask,
在这之前所有的Task称为ShuffleMapTask。
整个过程用到3个算法(资源调度算法、stage划分算法、task分配算法)
stage划分算法:会从执行action的最后一个RDD开始往前推,首先会为最后一个RDD创建一个stage,然后继续往前推,如果遇到一个宽依赖,就会为这个宽依赖创建一个stage。以此类推














 2393
2393











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









