






python爬取微信公众号文章
哈喽,大家好呀,我是滑稽君。本期我们想要爬取微信公众号的文章内容。首先你想要有自己的微信公众号来登录平台。在个人编辑发布文章的界面,我们能使用上方的超链接功能来搜索文章,可以按关键字,也可以按照公众号,我们选择后者。

视频讲解:
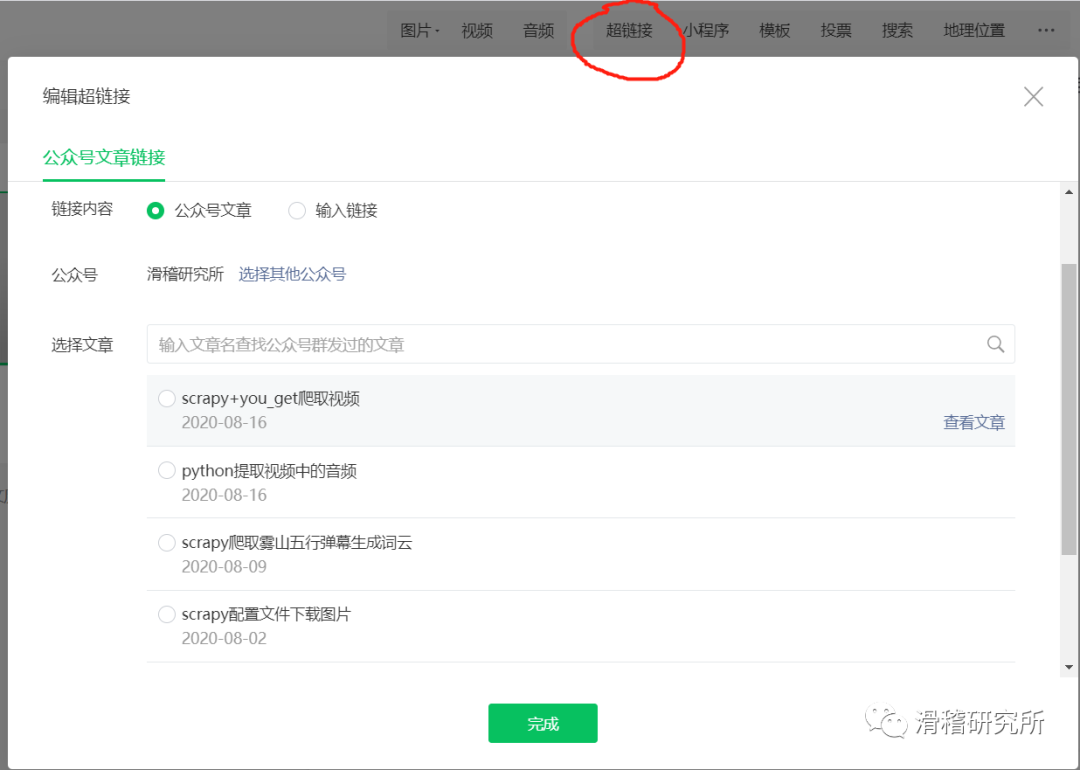
我们打开开发者模式。选择netword点击下一页就会刷新出数据,点击蓝色部分‘appmsg’。右边显示的url就是我们的json数据页面。
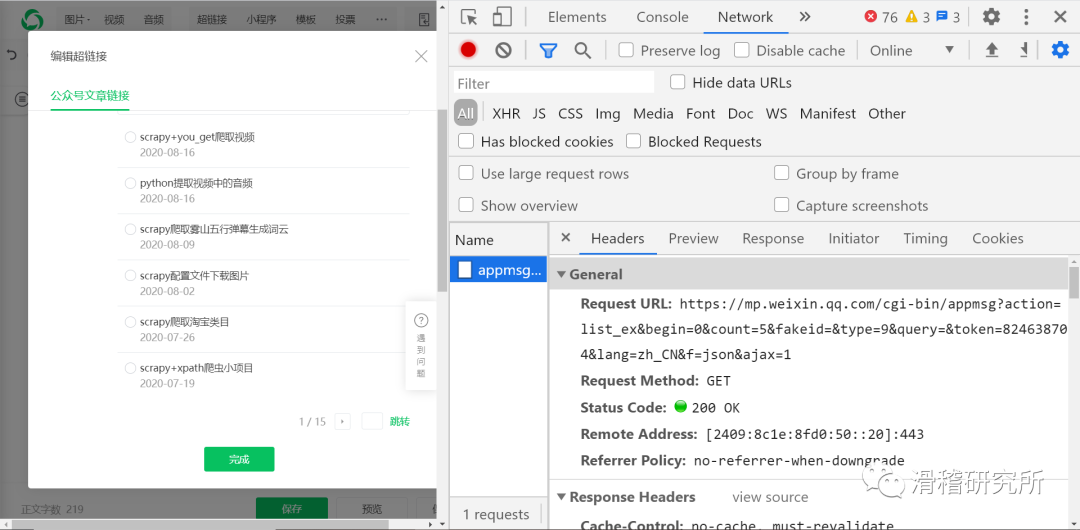
json界面:

我们进行解析:


可以看到我们想要的内容在‘app_msg_list’对应的值中,它本身是key。而我们想要的内容在title和link中。ok目标明确,上代码。
主代码:
import scrapyimport jsonimport timeclass GzhSpider(scrapy.Spider): name = 'gzh' start_urls = ['https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin=0&count=5&fakeid=&type=9&query=&token=824638704&lang=zh_CN&f=json&ajax=1'] def parse(self, response): gzh_json = json.loads( str(response.body, encoding='utf-8'), encoding='utf-8' ) txt1 = gzh_json['app_msg_list'] for data in txt1: title = data['title'] url = data['link'] print(title) print('url->' + url) time.sleep(3) yield { "title": title, "url": url } i = 0 for h in range(14): i = i + 5 x = str(i) next = "https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin=" + x + "&count=5&fakeid=&type=9&query=&token=824638704&lang=zh_CN&f=json&ajax=1" yield scrapy.Request(next)在考虑到可能发生请求频繁的情况,我们导入time库,每爬取一页,程序暂停3秒。翻页部分的处理也与以往不同。需要注意格式的转换以及空地址的情况。我们总共有15页内容,所以我们只需要操作14次。如果你还是担心出现空网站报错的情况,你可以加一个if判断网址是否为空,然后再传给request。
完成以上工作就万事大吉了吗?no ,尝试打印response.body,你会发现并不能返回我们要的json界面,为什么?不要忘了搜索文章的超链接功能是在我们登录平台后才可以使用的。也就是说你不登陆是无法使用超链接功能的。那我们就需要进行模拟登录。这时我们就需要用到cookie了。怎么样找到它呢?还是headers部分往下看。红色部分就是。
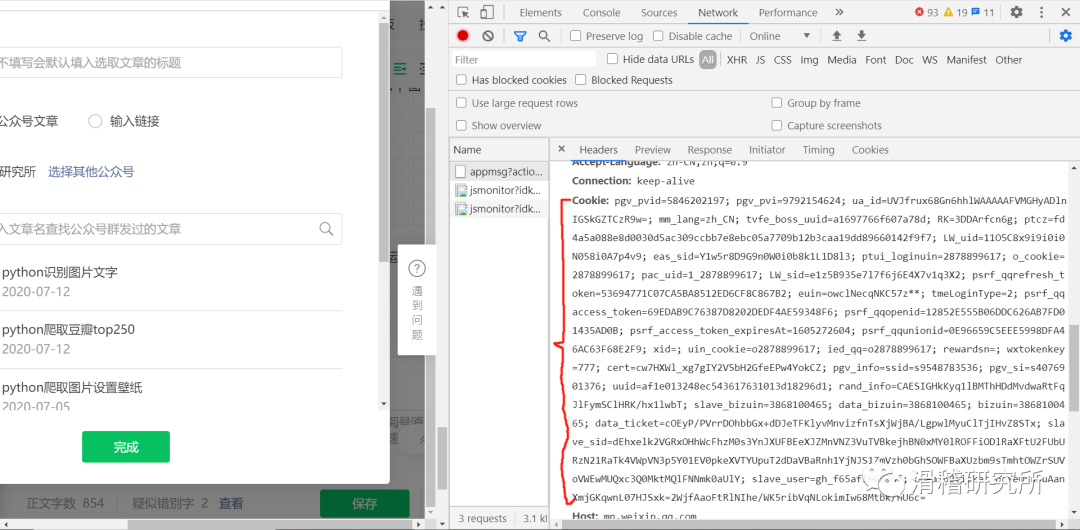
我们复制这一长串数据,打开settings文件进行配置。如图,先取消圈内代码的注释。在第二个headers部分加入我们的cookie数据。记得是键值对的形式。把刚才复制的数据粘贴到值的部分即可。
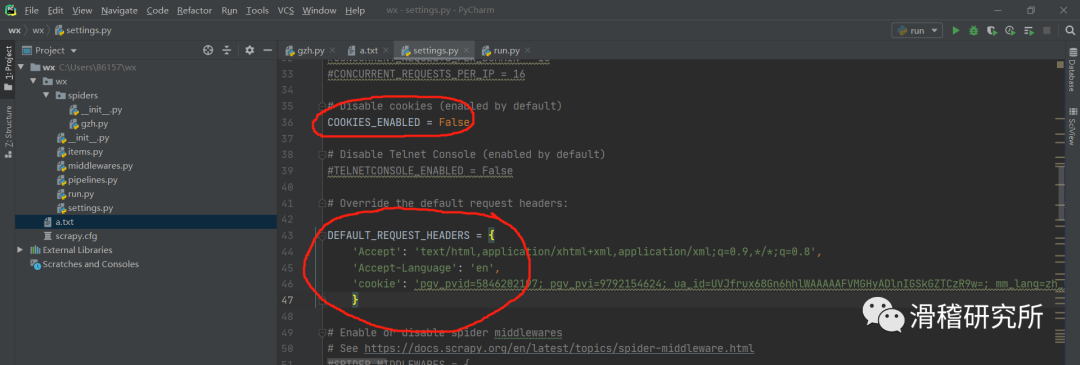
完成cookie的配置之后我们才能爬取到想要的内容,因为这时网页就认为我们是登录状态了。所以完成cookie的配置才是我们第一步要做的事情,很重要,所以我们把它放在最后讲。爬取到内容之后,我选择输出成txt。下面是运行结果。

需要用到登录之后的功能,都需要携带cookie去请求页面。否则页面会拒绝我们的请求。
 ❂ END
❂ END
视频讲解部分是我们全部流程的串联。如对文章内容还有疑问的可以选择观看视频。或私聊我呦
















 2442
2442











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









