






在实际业务中遇到这样一个场景:
现有 wf_cr_borrow_order、wf_admin_last_check_record_content 和 wf_cr_replan 三个表,数据量分别是 wf_cr_borrow_order(755424)、wf_admin_last_check_record_content(54253)、wf_cr_replan(321744)。三个表通过订单号关联,进入功能列表会搂这三个表 wf_cr_borrow_order.br_state=放款成功的且的 wf_cr_borrow_order.repayment_state in (逾期,逾期还款中)的数据然后根据 wf_admin_last_check_record_content.create_time,wf_admin_last_check_record_content.update_time,wf_cr_borrow_order.update_time 倒序展示。列表展示25条,查询数据时间长达3秒+左右;count数据总条数也长达0.9秒+左右。
请教的问题是:
1、explain 的结果是Using where; Using temporary; Using filesort,如何避免文件排序?
自己尝试过的解决方案
1、关联表的对应字段都添加了索引。
2、可以确定的是 : 如果去掉 wf_admin_last_check_record_content.create_time,wf_admin_last_check_record_content.update_time 两个字段的排序,查询速度和explain 返回的 rows 都显著提高。但是业务需要不能去掉!
目前使用的查询SQL:
EXPLAIN
SELECT
cbo.br_order_no,
cbo.loan_date,
cbo.replan_repay_time,
cbo.final_settle_date,
cbo.penalty_money,
cbo.applied_amount,
cbo.br_inst,
cbo.repay_total_default,
cbo.cut_total,
cbo.br_syje,
cbo.br_txje,
cbo.real_repayment_money,
cbo.br_state,
cbo.repayment_state,
cbo.customer_id,
cbo.customer_version,
cbo.param2,
cbo.collect_id,
cbo.product_id,
r.total_penalty_days
FROM
`wf_cr_borrow_order` AS cbo
LEFT OUTER JOIN wf_admin_last_check_record_content c ON cbo.br_order_no = c.br_order_no
LEFT OUTER JOIN wf_cr_replan r ON cbo.br_order_no = r.br_order_no
WHERE
(
cbo.`br_state` = 8
AND cbo.`repayment_state` IN ('3', '4')
)
ORDER BY
c.id,
c.create_time,
cbo.`last_update_time` DESC
LIMIT 0,
25;
Explain 出来的结果:
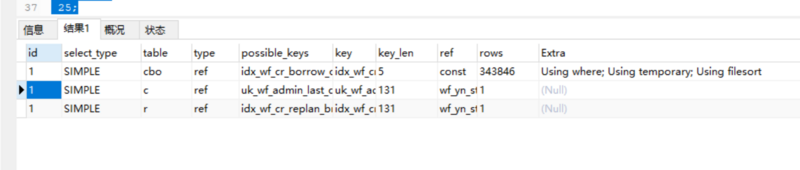
希望得到的结果:
1、如果可以在现有SQL基础上优化,希望将 文件排序 可以优化掉。
2、如果现有的SQL没有什么优化的余地了,还望大佬指出有什么其他的针对此场景的优化方案或者解决方案。
望各位大佬不吝赐教[抱拳]














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









