






前言:
网络爬虫这个东西看上去还是很神奇的。不过,如果你细想,或是有所研究就知道,其实爬虫并不那么高深。高深的是在我们的数据量很大的时候,就是当我们网络“图”的回环越来越多的时候,应该怎么去解决它。
本篇文章在这里只是起一个抛砖引玉的作用。本文主要是讲解了如何使用Java/Python访问网页并获得网页代码、Python模仿浏览器进行访问网页和使用Python进行数据解析。希望我们以本文开始,一步一步解开网络蜘蛛神秘的一面。
参考:
1.《自己动手写网络爬虫》
2.用python 写爬虫,去爬csdn的内容,完美解决 403 Forbidden
运行效果图:
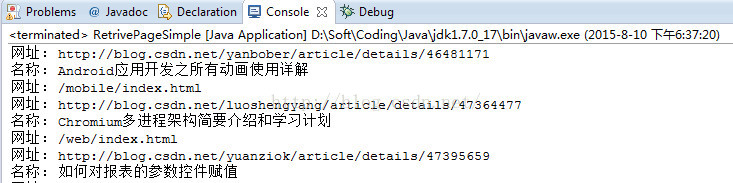
内容有点多,我只选取了一部分进行展示。
笔者环境:
系统: Windows 7
CentOS 6.5
运行环境: JDK 1.7
Python 2.6.6
IDE: Eclipse Release 4.2.0
PyCharm 4.5.1
数据库: MySQL Ver 14.14 Distrib 5.1.73
开发过程:
1.使用Java抓取页面
对于页面抓取我们采用Java来实现,当然你可以使用其他的语言来开发。不过
下面以“博客园”的首页为例,展示一下使用Java进行网页页面抓取的过程:
public class RetrivePageSimple {
private static HttpClient httpClient = new HttpClient();
// 设置代理服务器
static {
httpClient.getHostConfiguration().setProxy("58.220.2.132", 80);
}
public static boolean downloadPage(String path) throws HttpException,
IOException {
PostMethod postMethod = new PostMethod(path);
// 执行,返回状态码
int statusCode = httpClient.executeMethod(postMethod);
System.out.println(statusCode);
// 针对状态码进行处理 (简单起见,只处理返回值为200的状态码)
if (statusCode == HttpStatus.SC_OK) {
String a = postMethod.getResponseBodyAsString();
System.out.println(a);
return true;
}
return false;
}
public static void main(String[] args) {
try {
RetrivePageSimple.downloadPage("http://www.cnblogs.com/");
} catch (HttpException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}结果信息在这里就不再展示,太多了。。。- -!
2.使用Python抓取页面
可能你会问我,为什么上面写了使用Java版的页面抓取,这里又要写一个Python?这是有必要的。因为笔者在开发这个demo之前没有考虑一个问题。我们使用Java抓取了一个网页给Python的时候,这个网页字符串过长,无法作为参数传递。可能你会觉得保存文件是一个不错的选择,那html文件太多又要怎么办呢?是的,这里我们不得不舍弃这种让人心累的做法。
考虑到是因为参数长度的限制,这里我们在Java端只给出页面地址,抓取网页使用Python来进行。
按照最简单的方式,通常我们会像这样来使用Python网页:
import urllib2
result = urllib2.urlopen('http://blog.csdn.net/mobile/index.html')
html = result.read()
print html可是,笔者代码中使用的是CSDN的博客频道的url,CSDN对来自爬虫的访问进行一层过滤,如下我们会得到如下错误信息:

403,我被拒绝了。
3.使用模仿浏览器登录网站
前面说到我们去访问带有保护措施的网页时,会被拒绝。不过我们可以尝试使用自己的浏览器来访问它,是可以访问的。
也就是说如果我们可以在Python中去模仿自己是浏览器就可以对这个网页进行访问了。下面是Python模仿浏览器的代码:
import random
import socket
import urllib2
import cookielib
ERROR = {
'0':'Can not open the url,checck you net',
'1':'Creat download dir error',
'2':'The image links is empty',
'3':'Download faild',
'4':'Build soup error,the html is empty',
'5':'Can not save the image to your disk',
}
class BrowserBase(object):
def __init__(self):
socket.setdefaulttimeout(20)
self._content = None
def speak(self, name, content):
print '[%s]%s' % (name, content)
def open_url(self, url):
"""
打开网页
"""
cookie_support= urllib2.HTTPCookieProcessor(cookielib.CookieJar())
self.opener = urllib2.build_opener(cookie_support,urllib2.HTTPHandler)
urllib2.install_opener(self.opener)
user_agents = [
'Mozilla/5.0 (Windows; U; Windows NT 5.1; it; rv:1.8.1.11) Gecko/20071127 Firefox/2.0.0.11',
'Opera/9.25 (Windows NT 5.1; U; en)',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)',
'Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.5 (like Gecko) (Kubuntu)',
'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.0.12) Gecko/20070731 Ubuntu/dapper-security Firefox/1.5.0.12',
'Lynx/2.8.5rel.1 libwww-FM/2.14 SSL-MM/1.4.1 GNUTLS/1.2.9',
"Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.7 (KHTML, like Gecko) Ubuntu/11.04 Chromium/16.0.912.77 Chrome/16.0.912.77 Safari/535.7",
"Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:10.0) Gecko/20100101 Firefox/10.0 ",
]
agent = random.choice(user_agents)
self.opener.addheaders = [("User-agent", agent), ("Accept", "*/*"), ('Referer', 'http://www.google.com')]
try:
res = self.opener.open(url)
self._content = res.read()
# print self._content
except Exception, e:
self.speak(str(e)+url)
raise Exception
else:
return res
def get_html_content(self):
return self._content
def get_html_response(html):
spider = BrowserBase()
spider.open_url(html)
return spider.get_html_content()上面的代码是可以正常得到返回值的。如下就来看看对返回的结果的解析过程吧。
4.数据解析
使用Python来进行Html的解析工作,是异常的简单:
import HTMLParser
class ListWebParser(HTMLParser.HTMLParser):
def __init__(self):
HTMLParser.HTMLParser.__init__(self)
self.tagDIVFlag = False
self.tagDIVAFlag = False
self.tagH1Flag = False
self.tagSecondHrefFlag = False
self._name = None
self._address = None
def handle_starttag(self, tag, attrs):
if tag == 'div':
for name, value in attrs:
if name == 'class' and value == 'blog_list':
self.tagDIVFlag = True
if tag == 'h1':
if self.tagDIVFlag:
self.tagH1Flag = True
# print 'h1->', self.tagH1Flag
if tag == 'a':
#if self.tagDIVAFlag:
#print 'h1: ', self.tagH1Flag
if self.tagH1Flag:
for name, value in attrs:
if name == 'target' and value == '_blank':
self.tagDIVAFlag = True
if name == 'href':
if self.tagSecondHrefFlag:
print '网址:', value
self._address = value
self.tagSecondHrefFlag = True
# if name == 'href' and self.tagDIVAFlag:
# print '网址:', value
# self._address = value
def handle_endtag(self, tag):
if tag == 'div':
self.tagDIVFlag = False
if tag == 'h1':
self.tagH1Flag = False
# print 'false h1.'
if tag == 'a':
self.tagDIVAFlag = False
def handle_data(self, data):
if self.tagDIVAFlag:
print u"名称:", data.decode("utf-8")如果你说你在网上查找到的Html文件没有这个麻烦。这个我是承认的,因为正常情况下,我们解析一些简单数据的确很简单。上面代码中的复杂逻辑是在处理筛选。
说到筛选,这里我用到一个小技巧(当然,当用的人多了,这就不再只是技巧。不过这种方法可以在以后的编码过程中有所借鉴)。我们通过一些tag的特殊属性(如:id, class等)来锁定块。当我们开始块的时候,我们相应的标志位会被打成True,当我们退出块的时候,我们相应标志位会被打成False。可能你觉得这太麻烦。其实,你仔细想想就会知道,这是有道理的。
注意事项:
1.在使用Java进行页面抓取的时候,我们用到了代理服务器。这个代理服务器的host和port是可以直接在网上查到免费的。
2.你需要准备以下jar包,并导入到你的Eclipse工程中:
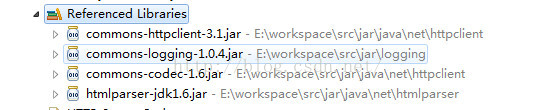
3.修改MySQL的默认编码为UTF-8
这里因为会有一些中文信息,所以我们需要对MySQL进行编码格式的转换。
如果你是在Linux下编码,那么你可以参考:http://blog.csdn.net/lemon_tree12138/article/details/46375637

















 1819
1819

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









