






模型需要好的数据才能训练出结果,本文总结了机器学习图像方面常用数据集。
MNIST

机器学习入门的标准数据集(Hello World!),10个类别,0-9 手写数字。包含了60,000 张 28x28 的二值训练图像,10,000 张 28x28 的二值测试图像。
最早的深度卷积网络 LeNet 便是针对 MNIST 数据集的,MNIST 数据集之所以是机器学习的 “Hello World”,是因为当前主流深度学习框架几乎无一例外将 MNIST 数据集的处理作为介绍及入门第一教程,其中 Tensorflow 关于 MNIST 的教程非常详细。
COCO

COCO 是一个大规模的对象识别、分割以及 Captioning 数据集。具有以下特点:
- Object segmentation
- Recognition in context
- Superpixel stuff segmentation
- 330K images (>200K labeled)
- 1.5 million object instances
- 80 object categories
- 91 stuff categories
- 5 captions per image
- 250,000 people with keypoints
以 2014 年的数据为例,其包含两种文件类型(训练、验证文件均有),Annotations(图片信息) 和 Images(图片文件本身)。
图片名即 Annotations 中的 file_name 字段。
Annotations 文件为一些超级大的 json 文件,分为三种类型:object instances, object keypoints, 和 image captions。三种类型均以以下 json 格式存储:
Copy{
"info" : info,
"images" : [image],
"annotations" : [annotation],
"licenses" : [license],
}
info{
"year" : int,
"version" : str,
"description" : str,
"contributor" : str,
"url" : str,
"date_created" : datetime,
}
image{
"id" : int,
"width" : int,
"height" : int,
"file_name" : str,
"license" : int,
"flickr_url" : str,
"coco_url" : str,
"date_captured" : datetime,
}
license{
"id" : int,
"name" : str,
"url" : str,
}
只有每种类型的 annotation 格式不同,如 Object Instance Annotations 格式为:
Copyannotation{
"id" : int,
"image_id" : int,
"category_id" : int,
"segmentation" : RLE or [polygon],
"area" : float,
"bbox" : [x,y,width,height],
"iscrowd" : 0 or 1,
}
categories[{
"id" : int,
"name" : str,
"supercategory" : str,
}]
具体的格式信息可以在这里看到。
ImageNet

MNIST 将初学者领进了深度学习领域,而 ImageNet 数据集对深度学习的浪潮起了巨大的推动作用。深度学习领域大牛 Hinton 在2012年发表的论文《ImageNet Classification with Deep Convolutional Neural Networks》在计算机视觉领域带来了一场“革命”,此论文的工作正是基于 ImageNet 数据集。
ImageNet 数据集有1400多万幅图片,涵盖2万多个类别;其中有超过百万的图片有明确的类别标注和图像中物体位置的标注,具体信息如下:
- Total number of non-empty synsets: 21841
- Total number of images: 14,197,122
- Number of images with bounding box annotations: 1,034,908
- Number of synsets with SIFT features: 1000
- Number of images with SIFT features: 1.2 million
你可以下载图片 urls 文件或者图片文件(需要注册,用于非商业用途)。图片 urls 文件内容为图片 ID 和 url:
Copyn00015388_12 http://farm4.static.flickr.com/3040/2946102733_9b9c9cf24e.jpg
n00015388_24 http://farm3.static.flickr.com/2093/2288303747_c62c007531.jpg
n00015388_81 http://www.theresevangelder.nl/images/dierenportretten/dier4.jpg
n00015388_155 http://www.zuidafrikaonline.nl/images/zuid-afrika-reis-giraffe.jpg
n00015388_157 http://farm1.static.flickr.com/145/430300483_21e993670c.jpg
...
_ 前面部分为 WordNet ID(wnid),一个 wnid 代表一个 synset(同义词集),如 n02084071 代表 "dog, domestic dog, Canis familiaris" 。具体信息可以看官方文档。
ImageNet 的 Object Bounding Boxes 文件采用了和 PASCAL VOC 数据集相同的格式,因此可以使用 PASCAL Development Toolkit 解析。另外,ImageNet 的 Object Bounding Boxes 文件是按照 synset(同义词集)划分子文件夹的,每个压缩包下面是同语义的图片文件 Annotation:
The PASCAL Visual Object Classes
PASCAL VOC挑战赛是视觉对象的分类识别和检测的一个基准测试,提供了检测算法和学习性能的标准图像注释数据集和标准的评估系统。PASCAL VOC2007之后的数据集包括20个类别:人类;动物(鸟、猫、牛、狗、马、羊);交通工具(飞机、自行车、船、公共汽车、小轿车、摩托车、火车);室内(瓶子、椅子、餐桌、盆栽植物、沙发、电视)。PASCAL VOC挑战赛在2012年后便不再举办,但其数据集图像质量好,标注完备,非常适合用来测试算法性能。
数据集包括图片的三种信息:原始图片(JPEGImages 文件夹),对象像素(SegmentationClass 文件夹)和分类像素(SegmentationObject 文件夹):

解压之后这些图片分别放在如下文件夹:
其中 Annotations 文件夹是图片描述的 xml 文件,例如 JPEGImages 文件夹中的 000007.jpg 图片,就会有相应的 000007.xml 文件描述该图片,包括图片的宽高、包含的 Object(可以有多个) 的类别、坐标等信息:
Copy<annotation>
<folder>VOC2007</folder>
<filename>000007.jpg</filename>
<source>
<database>The VOC2007 Database</database>
<annotation>PASCAL VOC2007</annotation>
<image>flickr</image>
<flickrid>194179466</flickrid>
</source>
<owner>
<flickrid>monsieurrompu</flickrid>
<name>Thom Zemanek</name>
</owner>
<size> //图像尺寸(长宽以及通道数)
<width>500</width>
<height>333</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>car</name> //物体类别
<pose>Unspecified</pose> //拍摄角度
<truncated>1</truncated> //是否被截断(0表示完整)
<difficult>0</difficult> //目标是否难以识别(0表示容易识别)
<bndbox> //bounding-box(包含左下角和右上角坐标)
<xmin>141</xmin>
<ymin>50</ymin>
<xmax>500</xmax>
<ymax>330</ymax>
</bndbox>
</object>
</annotation>
ImageSets 存放的是每一年的 Challenge 对应的图像数据,不同年份数据可能不同。
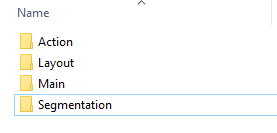
- 其中
Action下存放的是人的动作(例如running、jumping等等,这也是VOC challenge的一部分) Layout下存放的是具有人体部位的数据(人的head、hand、feet等等,这也是VOC challenge的一部分)Main文件夹下包含了各个分类的***_train.txt、***_val.txt和***_trainval.txt,如aeroplane_train.txt。文件每行是一个图片ID以及是否为正样本(1代表正样本,-1代表负样本)。Segmentation下存放的是验证集图片ID(val.txt文件)、训练集图片ID(train.txt文件)以及两者的合集(trainval.txt文件)。
The CIFAR-10 dataset and The CIFAR-100 dataset
CIFAR-10 和 CIFAR-100 数据集是 80 million tiny images 的子集。以 CIFAR-10 Python 版本为例,包含 10 个分类,60000 张 32x32 彩色图片,每个分类 6000 张图片。其中 50000 张是训练图片,另外 10000 张是测试图片。

其中 50000 张分成了 5 个训练 batches,剩下的 10000 张是 test batch。训练数据每个类总共包含 5000 张,但每个 batch 每个类的图片数量可能并不平均。
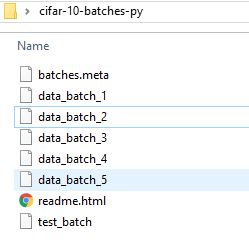
每个 batch 文件都是 Python pickle 生成的,所以可以使用 pickle 读取:
Copydef unpickle(file):
import pickle
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
函数返回一个 dict 对象,其中有两个 key 比较重要:
data:10000x3072 numpy array,每一行是一个 32x32 彩色图片。每 1024 个元素依次代表 R G B,像素值没有归一化(取值为 0-255)。labels:每一行代表图片分类,取值 0-9。
CIFAR-100 和 CIFAR-10 类似,只是类别为 100 个。实际上,CIFAR-10 和 MNIST 很类似。
Tiny Images Dataset
Tiny Images dataset 包含 79,302,017 张 32x32 彩色图片。包含 5 个文件:
- Image binary (227Gb):图片本身,二进制格式
- Metadata binary (57Gb):图片信息(filename, search engine used, ranking etc)
- Gist binary (114Gb):图片描述
- Index data (7Mb):Matlab 索引文件
- Matlab Tiny Images toolbox (150Kb) :Matlab 索引文件 代码,用来加载图片
FDDB: Face Detection Data Set and Benchmark
FDDB是全世界最具权威的人脸检测评测平台之一,包含来自 Faces in the Wild 的2845张图片,共有5171个人脸数据。测试集范围包括:不同姿势、不同分辨率、旋转和遮挡等图片,同时包括灰度图和彩色图,标准的人脸标注区域为椭圆形。
FDDB 数据集包含以下内容:
- 原始图片(来自 Faces in the Wild )
- 人脸数据(Face annotations)
- 检测输出(包括矩形区域 和 椭圆区域)
- 其他信息
原始图片
原始图片可以在这里下载:originalPics.tar.gz。解压后图片的路径为 originalPics/year/month/day/big/*.jpg。
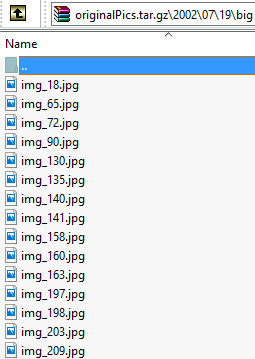
人脸数据(Face annotations)
比较重要的是 Face annotations。解压缩 FDDB-folds.tgz 文件将会得到 FDDB-folds 文件夹,包含 FDDB-fold-xx.txt 和 FDDB-fold-xx-ellipseList.txt 文件,xx 代表文件夹索引。
"FDDB-fold-xx.txt" 文件的每一行指定了一个上述原始图片的一个文件名,如 "2002/07/19/big/img_130" 对应 "originalPics/2002/07/19/big/img_130.jpg."
对应的 annotations 文件 "FDDB-fold-xx-ellipseList.txt" 格式如下:
Copy...
<image name i>
<number of faces in this image =im>
<face i1>
<face i2>
...
<face im>
...
每一个 face 即一个椭圆区域,用以下格式表示:
Copy<长轴半径 短轴半径 长轴方向 x轴中心坐标 y轴中心坐标 1>
示例:
Copy2002/08/11/big/img_591
1
123.583300 85.549500 1.265839 269.693400 161.781200 1
2002/08/26/big/img_265
3
67.363819 44.511485 -1.476417 105.249970 87.209036 1
41.936870 27.064477 1.471906 184.070915 129.345601 1
70.993052 43.355200 1.370217 340.894300 117.498951 1
2002/07/19/big/img_423
1
87.080955 59.379319 1.550861 255.383099 133.767857 1
2002/08/24/big/img_490
1
54.692105 35.056825 -1.384924 145.665694 78.101005 1
2002/08/31/big/img_17676
2
37.099961 29.000000 1.433107 28.453831 37.664572 1
79.589662 49.835046 -1.457361 112.514300 92.364284 1















 1058
1058











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









