






差分隐私的 Composition Theorem
在前面三节介绍的内容是0到1的一个过程,是为了明白差分隐私的基本概念。而这一节要讲到Composition Theorem是1到n的过程。
Composition Theorem直接翻译的话就是组成原理,目的就是将一系列满足差分隐私的查询组合在一起,并且保证整体仍然满足差分隐私。
例如,对一个简单的3层神经网络,如果将每个神经元计算梯度看成一个查询函数
- 第一个是基本组成原理,就是不考虑查询函数之间的关联性(查询相互独立)
- 第二个是高级组成原理,就是考虑查询函数之间的关联性
基本的内容目录如下:
- 基本组成原理 Basic Composition Theorem
- 并行组成 不相交数据集,不同查询
- 串行组成 同一数据集,不同查询
- 高级组成原理 Advanced Composition Theorem
- Naive Composition Theorem
- Strong Composition Theorem
- Moment Account (15年Deep Learning with Differential Privacy[1]中提出的)
1. Basic Composition Theorem
1.1 Sequential Composition 串行组合
串行组合简单讲就是同一数据集,不同查询函数,在[PINQ][2]中的定义是:

其中
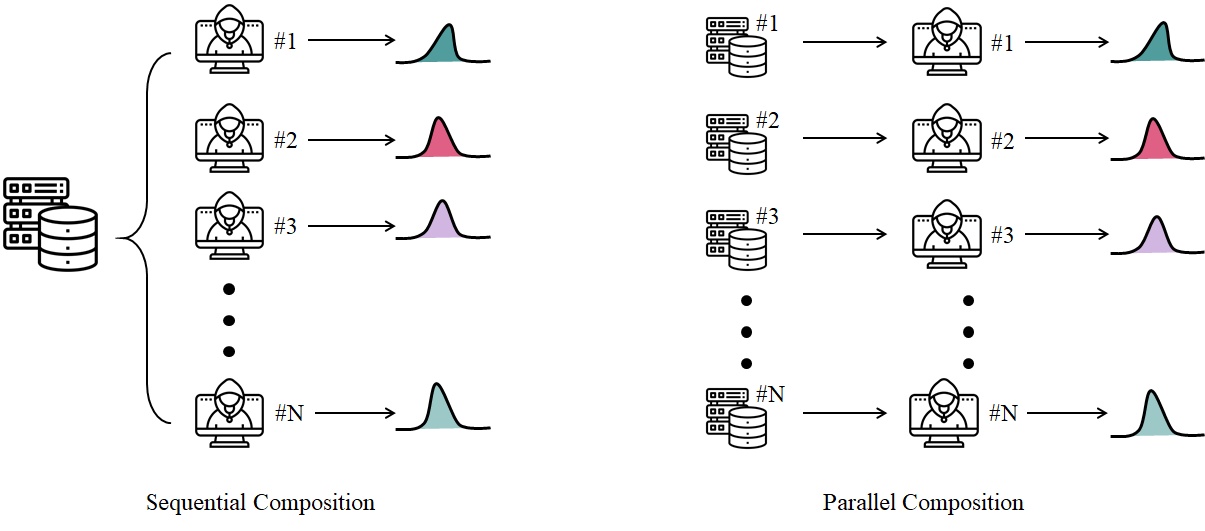
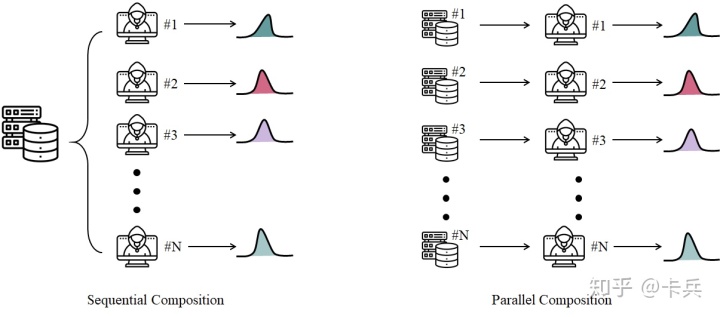
2.4节。简单的示意图如下面图1中左边的
Sequential Composition。
1.2 Parallel Composition 并行组合
并行组合简单讲就是不同数据集,不同查询函数,在[PINQ][2] 中的定义是:
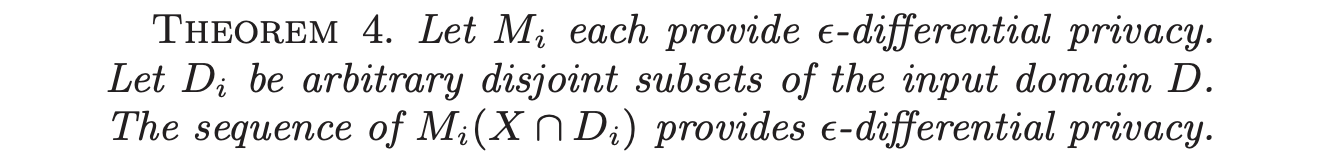
其中
互不相交的数据集,
Parallel Composition。
2. Advanced Composition 高级组成
在上一节我们讲了两个基本的组成原理,并行的和串行的。而这一节,我们向更高级一点的方向研究一下。我们考虑攻击者可以自适应地影响数据库以及对应的查询机制,换句话说查询与查询之间是存在关联的,如下图所示。

其中,
最终的输出结果可以用
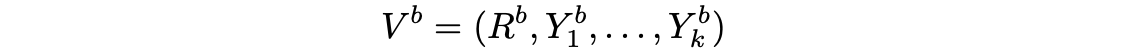
其中
这个输出是一个多维的随机变量,它有对应的分布;我们的目标就是让基于任意两个兄弟数据集(只相差一个样本)得到的两个输出变量之后,他们对应的分布的差异应该尽可能接近,以至于攻击者不知道用了哪个数据集。而两个分布的差异就称为Privacy Loss,如果是严格约束这个Privacy Loss,那么就是
2.1 Navie Composition Throrem

这是最简单的组合机制,可以看到组合之后的

2.2 Strong Composition Throrem
强组合原理的基本思想就是用很小的一点
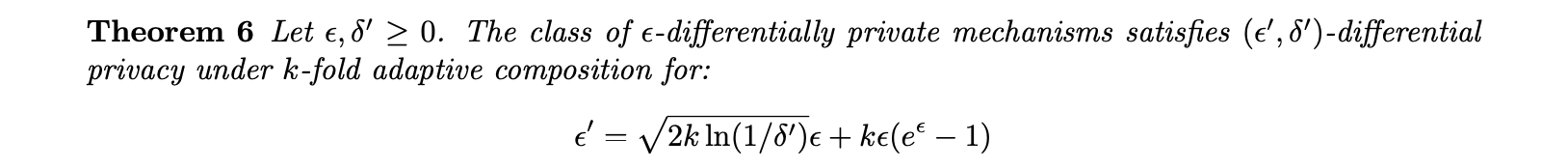
这里咋一看组合之后的
Naive Composition的还多,但实际上当

2.3 Moments Accountant
这是在Deep Learning with differential privacy中提出来的方法,细节的证明可以参考[1],这里我讲述一下基本思路。
它提出的方法就是在计算的梯度
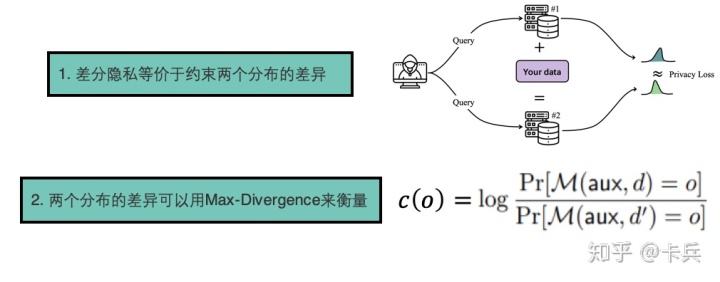
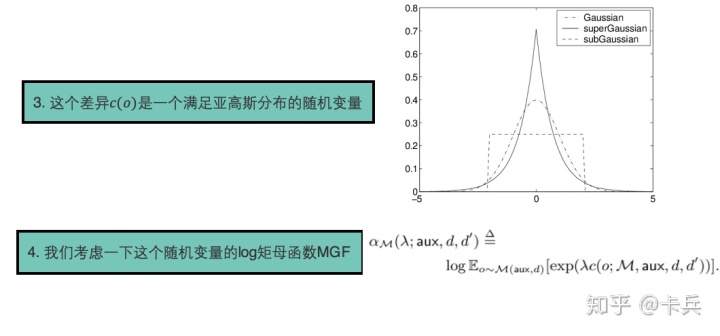
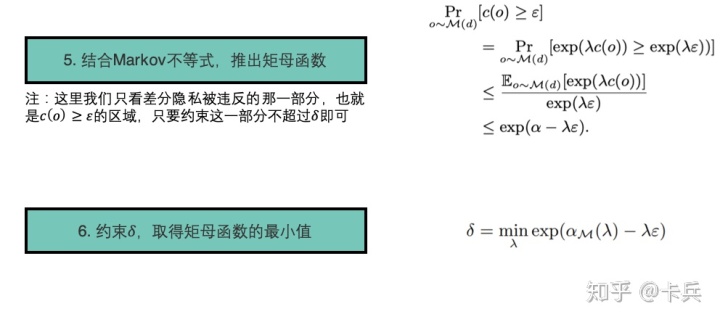
而这个

可以看到在三种方法种,Moment Account方法在同样的花费的隐私预算最小。
参考
- ^abDeep Learning with differential_privacy https://arxiv.org/abs/1607.00133
- ^abcPrivacy Integrated Queries https://www.microsoft.com/en-us/research/wp-content/uploads/2009/06/sigmod115-mcsherry.pdf
- ^Composition Theorems https://www.cis.upenn.edu/~aaroth/courses/slides/Lecture4.pdf
- ^abcPPT-Deep Learning with differential privacy https://course.ece.cmu.edu/~ece734/fall2016/lectures/Deep_Learning_with_differential_privacy.pdf
- ^The algorithm fundation of differential book https://www.cis.upenn.edu/~aaroth/Papers/privacybook.pdf














 244
244











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









