



 本文介绍了23种设计模式,并根据其目的和范围进行了分类。设计模式被分为创建型、结构型和行为型三大类,并进一步细分为类模式和对象模式。文中详细解释了各类模式的特点及应用场景。
本文介绍了23种设计模式,并根据其目的和范围进行了分类。设计模式被分为创建型、结构型和行为型三大类,并进一步细分为类模式和对象模式。文中详细解释了各类模式的特点及应用场景。
23种设计模式——组织编目
——摘自《设计模式:可复用面向对象软件的基础》
设计模式在粒度和抽象层次上各不相同。由于存在众多的设计模式,我们希望用一种方式将它们组织起来。这一节将对设计模式进行分类以便于我们对各种相关的模式进行引用。分类有助于更快地学习目录中的模式,且对发现的模式也有指导作用,如下表所示。
| 目的 | ||||
| 创建型 | 结构型 | 行为型 | ||
| 范围 | 类 | Factory Method | Adapter(类) | Interpreter Template Method |
| 对象 | Abstract Factory Builder Prototype Singleton | Adapter(对象) Bridge Composite Decorator Facade Flyweight Proxy | Chain of Responsibility Command Iterator Mediator Memento Observer State Strategy Visitor | |
我们根据两条准则对模式进行分类。
第一是目的准则,即模式是用来完成什么工作的。模式依据其目的可分为创建型(Creational)、结构型(Structural)、行为型(Behavioral)三种。创建型模式与对的创建有关;结构型模式处理类或对象的组合;行为型模式对类或对象怎样交互和怎样分配职责进行描述。
第二是范围准则,指定模式主要是用于类还是用于对象。类模式处理类和子类之间的关系,这些关系通过继承建立,是静态的。在编译时刻便确定下来。对象模式处理对象间的关系,这些关系在运行时刻是可以变化的,更具动态性。从某种意义上来说,几乎所有模式都使用继承机制,所以“类模式”只指那些集中于处理类间关系的模式,而大部分模式都属于对象模式的范畴。
创建型类模式将对象的部分创建工作延迟到子类,而创建型对象模式则将它延迟到另一个对象中。
结构型类模式使用继承机制来组合类,而结构型对象模式则描述了对象的组装方式。
行为型类模式使用继承描述算法和控制流,而行为型对象模式则描述一组对象怎样协作完成单个对象所无法完成的任务。
还有其他组织模式的方式。有些模式经常会被绑定在一直民使用。
有些模式是可替代的,有些模式尽管使用意图不同,但产生的设计结果是很相似的。
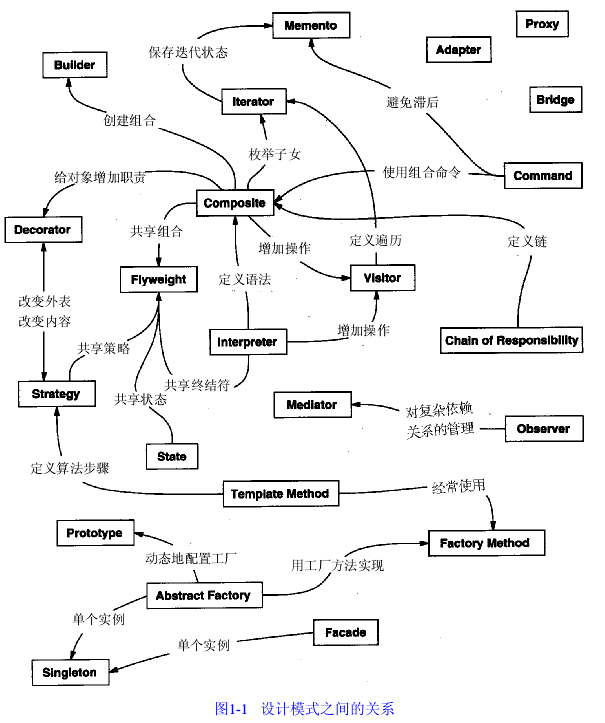
还有一种方式是根据模式的“相关模式”部分所描述的它们怎样互相引用来组织设计模式。如下图所示。
显然,存在着许多组织设计模式的方法。从多角度去思考有助于对它们的功能、差异和应用场合的更深入理解。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









