






1.普通SVM分类MNIST数据集
1 #导入必备的包 2 import numpy as np 3 import struct 4 import matplotlib.pyplot as plt 5 import os 6 ##加载svm模型 7 from sklearn import svm 8 ###用于做数据预处理 9 from sklearn import preprocessing 10 import time 11 12 #加载数据的路径 13 path='./dataset/mnist/raw' 14 def load_mnist_train(path, kind='train'): 15 labels_path = os.path.join(path,'%s-labels-idx1-ubyte'% kind) 16 images_path = os.path.join(path,'%s-images-idx3-ubyte'% kind) 17 with open(labels_path, 'rb') as lbpath: 18 magic, n = struct.unpack('>II',lbpath.read(8)) 19 labels = np.fromfile(lbpath,dtype=np.uint8) 20 with open(images_path, 'rb') as imgpath: 21 magic, num, rows, cols = struct.unpack('>IIII',imgpath.read(16)) 22 images = np.fromfile(imgpath,dtype=np.uint8).reshape(len(labels), 784) 23 return images, labels 24 def load_mnist_test(path, kind='t10k'): 25 labels_path = os.path.join(path,'%s-labels-idx1-ubyte'% kind) 26 images_path = os.path.join(path,'%s-images-idx3-ubyte'% kind) 27 with open(labels_path, 'rb') as lbpath: 28 magic, n = struct.unpack('>II',lbpath.read(8)) 29 labels = np.fromfile(lbpath,dtype=np.uint8) 30 with open(images_path, 'rb') as imgpath: 31 magic, num, rows, cols = struct.unpack('>IIII',imgpath.read(16)) 32 images = np.fromfile(imgpath,dtype=np.uint8).reshape(len(labels), 784) 33 return images, labels 34 train_images,train_labels=load_mnist_train(path) 35 test_images,test_labels=load_mnist_test(path) 36 37 X=preprocessing.StandardScaler().fit_transform(train_images) 38 X_train=X[0:60000] 39 y_train=train_labels[0:60000] 40 41 print(time.strftime('%Y-%m-%d %H:%M:%S')) 42 model_svc = svm.LinearSVC() 43 #model_svc = svm.SVC() 44 model_svc.fit(X_train,y_train) 45 print(time.strftime('%Y-%m-%d %H:%M:%S')) 46 47 ##显示前30个样本的真实标签和预测值,用图显示 48 x=preprocessing.StandardScaler().fit_transform(test_images) 49 x_test=x[0:10000] 50 y_pred=test_labels[0:10000] 51 print(model_svc.score(x_test,y_pred)) 52 y=model_svc.predict(x) 53 54 fig1=plt.figure(figsize=(8,8)) 55 fig1.subplots_adjust(left=0,right=1,bottom=0,top=1,hspace=0.05,wspace=0.05) 56 for i in range(100): 57 ax=fig1.add_subplot(10,10,i+1,xticks=[],yticks=[]) 58 ax.imshow(np.reshape(test_images[i], [28,28]),cmap=plt.cm.binary,interpolation='nearest') 59 ax.text(0,2,"pred:"+str(y[i]),color='red') 60 #ax.text(0,32,"real:"+str(test_labels[i]),color='blue') 61 plt.show()
2.运行结果:
开始时间:2018-11-17 08:31:09
结束时间:2018-11-17 08:53:04
用时:21分55秒
精度:0.9122
预测图片:

3.带核的SVM
1 def load_mnist_train(path, kind='train'): 2 3 labels_path = os.path.join(path,'%s-labels-idx1-ubyte'% kind) 4 images_path = os.path.join(path,'%s-images-idx3-ubyte'% kind) 5 with open(labels_path, 'rb') as lbpath: 6 magic, n = struct.unpack('>II',lbpath.read(8)) 7 labels = np.fromfile(lbpath,dtype=np.uint8) 8 with open(images_path, 'rb') as imgpath: 9 magic, num, rows, cols = struct.unpack('>IIII',imgpath.read(16)) 10 images = np.fromfile(imgpath,dtype=np.uint8).reshape(len(labels), 784) 11 return images, labels 12 def load_mnist_test(path, kind='t10k'): 13 14 labels_path = os.path.join(path,'%s-labels-idx1-ubyte'% kind) 15 images_path = os.path.join(path,'%s-images-idx3-ubyte'% kind) 16 with open(labels_path, 'rb') as lbpath: 17 magic, n = struct.unpack('>II',lbpath.read(8)) 18 labels = np.fromfile(lbpath,dtype=np.uint8) 19 with open(images_path, 'rb') as imgpath: 20 magic, num, rows, cols = struct.unpack('>IIII',imgpath.read(16)) 21 images = np.fromfile(imgpath,dtype=np.uint8).reshape(len(labels), 784) 22 return images, labels 23 24 25 def test(): 26 path = 'mnist' 27 train_images, train_labels=load_mnist_train(path) 28 test_images, test_labels=load_mnist_test(path) 29 print(train_labels[0]) 30 print(test_labels[0]) 31 ss = preprocessing.StandardScaler() 32 33 X = ss.fit_transform(train_images) 34 35 # X=preprocessing.StandardScaler().fit_transform(train_images) 36 X_train = X[0:10000] 37 y_train = train_labels[0:10000] 38 print(time.strftime('%Y-%m-%d %H:%M:%S')) 39 print(y_train) 40 41 # model_svc = LinearSVC() 42 # model_svc = SVC(C=100, gamma='auto') 43 44 # model_svc = GridSearchCV(SVC(class_weight='balanced'), param_grid={"C":[0.9, 100,10],"gamma":[0.01,10,0.1]},cv=4) 45 # model_svc.fit(X_train, y_train) 46 # print("The best parameters are %s with a score of %0.2f" % (model_svc.best_params_, model_svc.best_score_)) 47 48 # model_svc.fit(X_train, y_train) 49 # print("sd") 50 # y_predict = lsvc.predict(X_test) 51 # print(time.strftime('%Y-%m-%d %H:%M:%S')) 52 # 53 ##显示前30个样本的真实标签和预测值,用图显示 54 x=preprocessing.StandardScaler().fit_transform(test_images) 55 x_test=x[0:10000] 56 y_test=test_labels[0:10000] 57 # print(model_svc.score(x_test, y_test)) 58 # y = model_svc.predict(x) 59 scores = ['precision', 'recall'] 60 tuned_parameters = [{'kernel': ['rbf'], 'gamma': [0.01, 0.1, 10], 61 'C': [1, 10, 100, 1000]}] 62 # print("# Tuning hyper-parameters for %s" % score) 63 print() 64 # 调用 GridSearchCV,将 SVC(), tuned_parameters, cv=5, 还有 scoring 传递进去, 65 clf = GridSearchCV(SVC(class_weight='balanced'), param_grid={"C":[0.1, 1, 100, 10], "gamma":[0.01,10,0.1]}, cv=4) 66 # 用训练集训练这个学习器 clf 67 clf.fit(X_train, y_train) 68 69 print("Best parameters set found on development set:") 70 print() 71 72 # 再调用 clf.best_params_ 就能直接得到最好的参数搭配结果 73 print(clf.best_params_) 74 75 print() 76 print("Grid scores on development set:") 77 print() 78 means = clf.cv_results_['mean_test_score'] 79 stds = clf.cv_results_['std_test_score'] 80 81 # 看一下具体的参数间不同数值的组合后得到的分数是多少 82 for mean, std, params in zip(means, stds, clf.cv_results_['params']): 83 print("%0.3f (+/-%0.03f) for %r" 84 % (mean, std * 2, params)) 85 86 print() 87 88 print("Detailed classification report:") 89 print() 90 print("The model is trained on the full development set.") 91 print("The scores are computed on the full evaluation set.") 92 print() 93 y_true, y = y_test, clf.predict(x) 94 95 # 打印在测试集上的预测结果与真实值的分数 96 print(classification_report(y_true, y)) 97 98 print() 99 100 # fig1=plt.figure(figsize=(8,8)) 101 # fig1.subplots_adjust(left=0,right=1,bottom=0,top=1,hspace=0.05,wspace=0.05) 102 # for i in range(100): 103 # ax=fig1.add_subplot(10,10,i+1,xticks=[],yticks=[]) 104 # ax.imshow(np.reshape(test_images[i], [28,28]),cmap=plt.cm.binary,interpolation='nearest') 105 # ax.text(0,2,"pred:"+str(y[i]),color='red') 106 # ax.text(0,32,"real:"+str(test_labels[i]),color='blue') 107 # plt.show() 108 109 if __name__ == '__main__': 110 111 test()
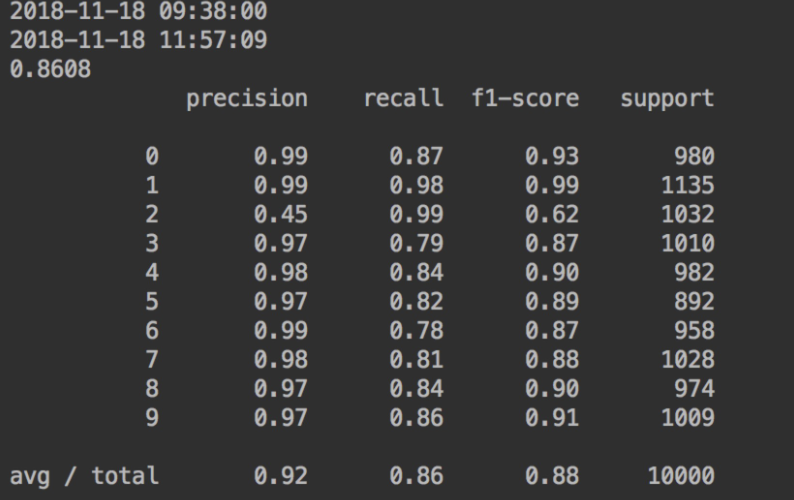
4.测试结果















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









