






MapReduce:将下面的两排数字先按第一排排序,然后再按第二排排序,要求顺序排序
文件如下:
12 1 13 34 1 12 5 78 7 63 8 66 9 3 3 6 22 70 4 6 6 32 5 14 78 22 5 25 89 21 72 13 4 15 1 11
这个案例主要考察我们对排序的理解,我们可以这样做:
代码如下(由于水平有限,不保证完全正确,如果发现错误欢迎指正):
①建一个TestBean
package com; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; import org.apache.hadoop.io.WritableComparable; public class TestBean implements WritableComparable<TestBean>{ private long a; private long b; public TestBean() { super(); } public TestBean(long a, long b) { super(); this.a = a; this.b = b; } public long getA() { return a; } public void setA(long a) { this.a = a; } public long getB() { return b; } public void setB(long b) { this.b = b; } @Override public String toString() { return a + " " + b; } @Override public void readFields(DataInput in) throws IOException { this.a=in.readLong(); this.b=in.readLong(); } @Override public void write(DataOutput out) throws IOException { out.writeLong(a); out.writeLong(b); }
//排序主要代码 @Override public int compareTo(TestBean o) { long i=this.a-o.getA(); if(i==0){ long j=this.b-o.getB(); return (int) j; }else{ return (int)i; } } }
②测试代码:
package com; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class TestCount { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration config = new Configuration(); config.set("fs.defaultFS", "hdfs://192.168.0.100:9000"); config.set("yarn.resourcemanager.hostname", "192.168.0.100"); FileSystem fs = FileSystem.get(config); Job job = Job.getInstance(config); job.setJarByClass(TestCount.class); //设置所用到的map类 job.setMapperClass(myMapper.class); job.setMapOutputKeyClass(TestBean.class); job.setMapOutputValueClass(NullWritable.class); //设置用到的reducer类 job.setReducerClass(myReducer.class); job.setOutputKeyClass(TestBean.class); job.setOutputValueClass(NullWritable.class); //设置输出地址 FileInputFormat.addInputPath(job, new Path("/input/order.txt")); Path path = new Path("/output/"); if(fs.exists(path)){ fs.delete(path, true); } //指定文件的输出地址 FileOutputFormat.setOutputPath(job, path); //启动处理任务job boolean completion = job.waitForCompletion(true); if(completion){ System.out.println("Job Success!"); } } public static class myMapper extends Mapper<LongWritable, Text,TestBean, NullWritable>{ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String values=value.toString(); String words[]=values.split(" "); TestBean bean = new TestBean(Long.parseLong(words[0]),Long.parseLong(words[1])); context.write(bean, NullWritable.get()); } } public static class myReducer extends Reducer<TestBean, NullWritable, LongWritable, LongWritable>{ @Override protected void reduce(TestBean key, Iterable<NullWritable> values,Context context)throws IOException, InterruptedException { context.write(new LongWritable(key.getA()), new LongWritable(key.getB())); } } }
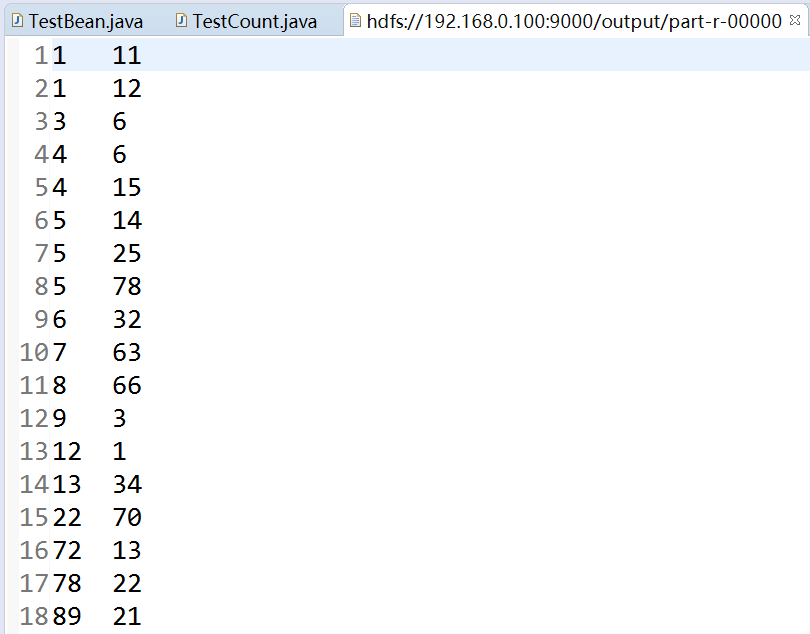
这样就能得到最终结果:
如果您认为这篇文章还不错或者有所收获,您可以通过右边的“打赏”功能 打赏我一杯咖啡【物质支持】,也可以点击下方的【好文要顶】按钮【精神支持】,因为这两种支持都是使我继续写作、分享的最大动力!















 1934
1934











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









