







本文对应UCL RL课程的第四课和第五课,第一节讲了如何估计value function,如蒙特卡洛,Temporal difference的过程,并进行了forward和backward两个方向的分析。第二节则讲了如何优化value function,如Sarsa和Q-learning的方法。
1.model free prediction
Estimate the value function of an unknown MDP
1.1.Mente-Carlo RL
- First-Visit MC

- Every-Visit MC
上述两者过程完全一样,只是在一个episode中(如玩一次牌),对于经过了多次的state,是否累计。
每次随机sample出一个路径trajectory,然后评估这个路径上的每个state依靠结果。如玩21点的时候,随机sample出一手牌,然后看是否赢。蒙特卡洛这种随机sample的方法非常简单,依据大数定理,sample足够多的时候就行。
通过incremental update的方式,每次sample出的新的
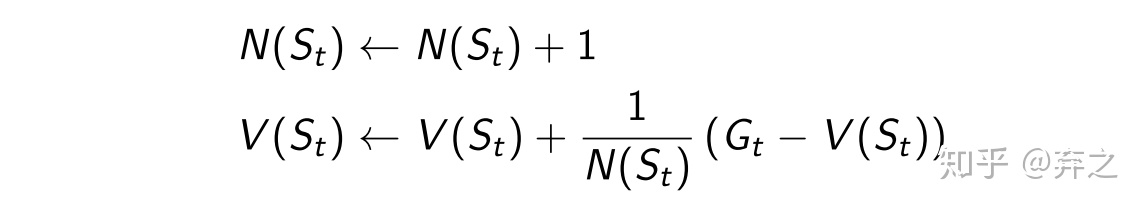
在non-stationary problems中,比如对之前的episode有一定的遗忘,自己定义一个小参数
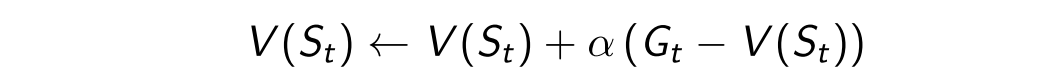
1.2.Temporal-Difference(TD) Learning
TD和MC的不同在于,可以利用incomplete episode,然后自己预估后面的return,下图是一个理论公式上的简单的比较

还记得
以开车回家为例
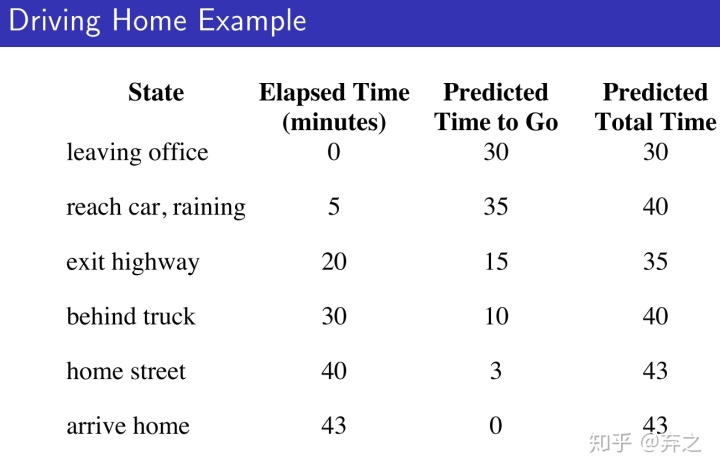
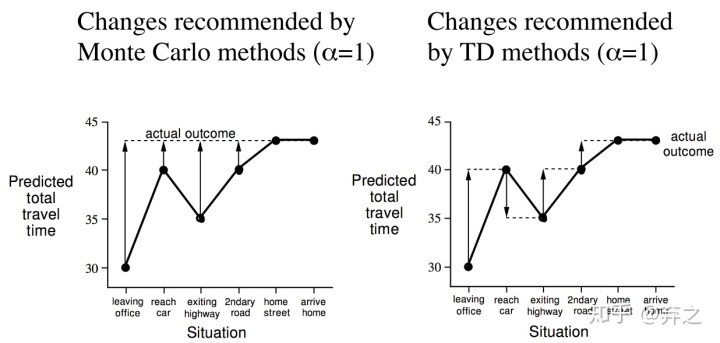
MC方法和TD的是不一样的。MC只有一个最终的return(actual outcome),43min,而TD可以根据每一步的结果对return进行一定的调整。
所以TD的优势在于
- 在最终的outcome出来之前也可以学习
- 没有最终的outcome的也可以学习
但是TD的缺点在于会有bias,我们可以看到TD是利用当前学习到的下一个状态
TD的优点就是low variance,显而易见,反馈更加及时,与下一个状态相关。并且通常会更加efficient。
其实TD的过程是一个markov过程在做MDP的东西,而显然MC不是。TD因此满足Markov property,在Markov的环境下当然会更加efficiency。举一个简单的计算例子

初始都认为为0,按照MC,那就直接看全过程了,
可以对比一下
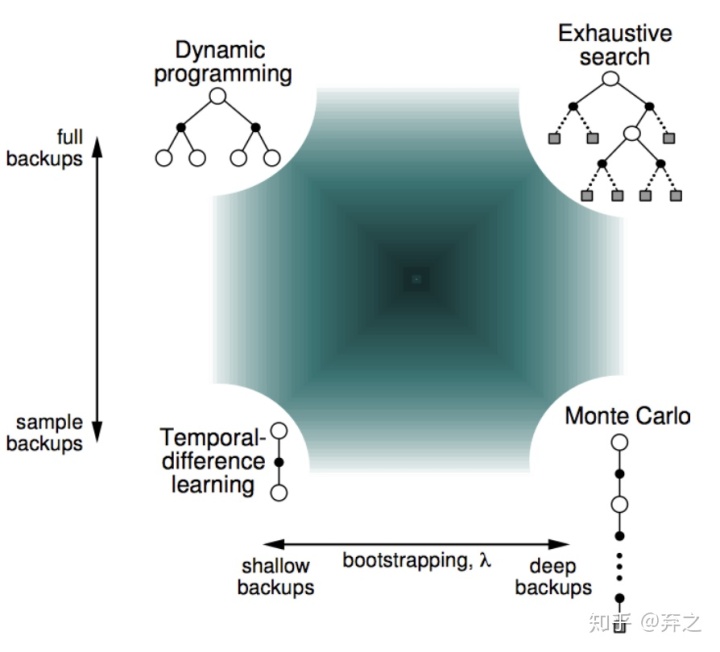
DP全部搜索太难,就用MC和TD进行sample来做。
1.2.1.n步的temporal difference
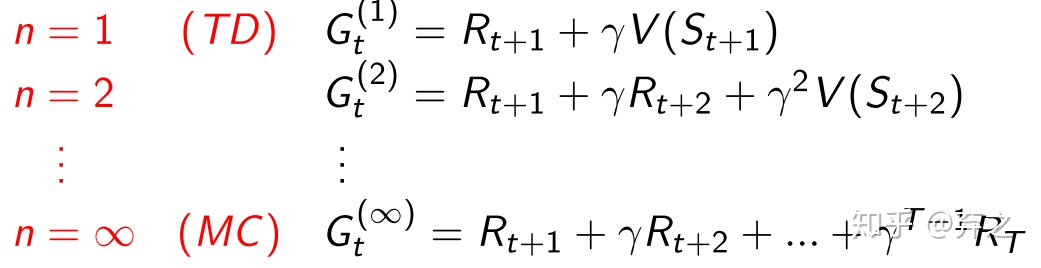
MC和TD分别是两个极端,一个只考虑一步,另一个则是只考虑全部。我们可以做一个折衷,做n-step的。
既然可以拓展TD,当然我们可以做更加深入的拓展和average做更加robust的,利用所有n-step来average,称之为
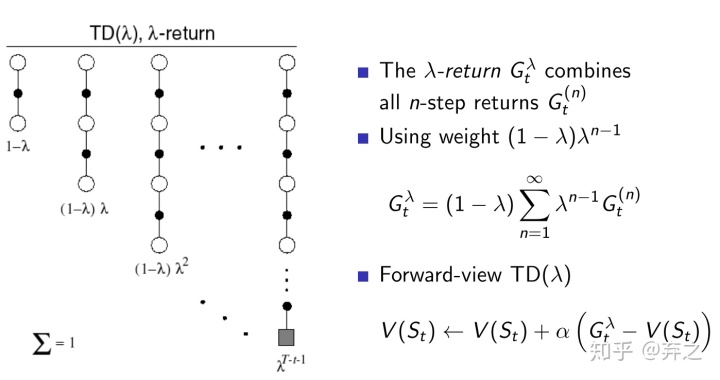
上图中,不同的TD(n)被加了一个权重然后加权,利用了geometry weighting的方法。
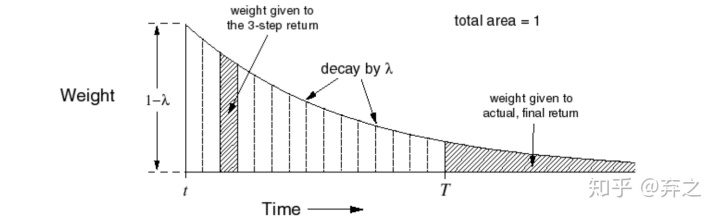
1.2.2.Eligibility Traces:backward view
在算return的时候,

比如上面点击这件事,我们可以有两种分析方法
- Frequency heuristic: assign credit to most frequent states 最频繁发生的:bell是决定性因素
- Recency heuristic: assign credit to most recent states Eligibility 最近发生的:light是决定性因素
eligibility trace就是做这件事:如何评估之前发生的事的重要性?这里可以看成是之前预估的error的重要性TD-error(预估值TD和均值的差值)。采用的上述两者的结合体
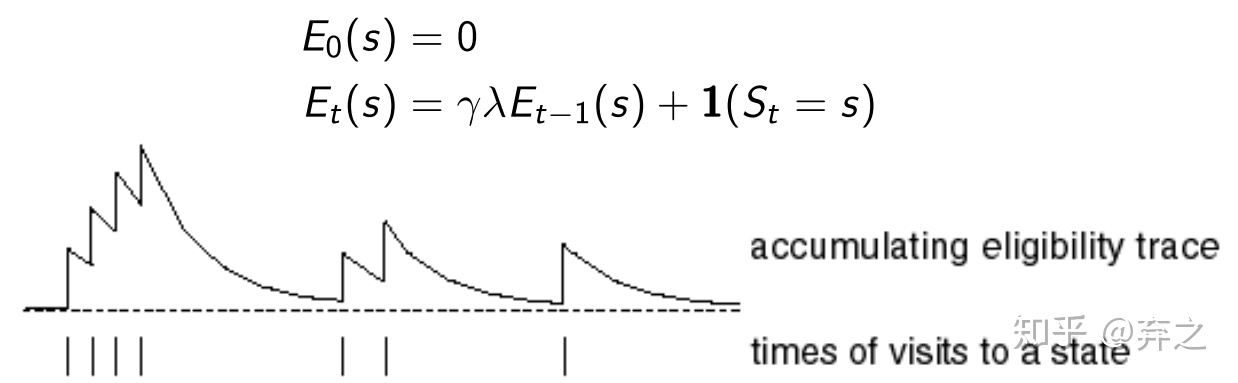
利用
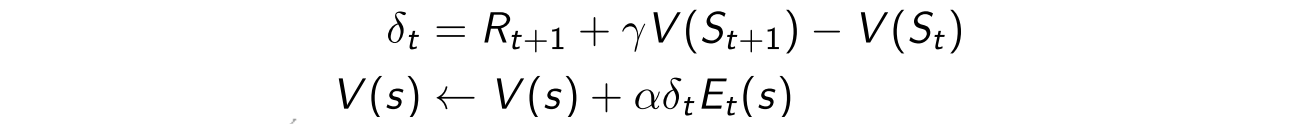
所以最终update的方式就是利用上一节的TD-error(预估值TD和均值的差值)和这个eligibility。
当
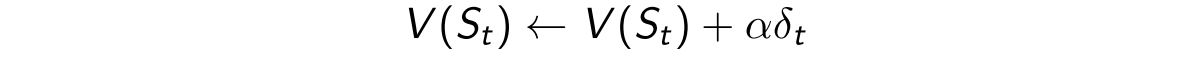
当
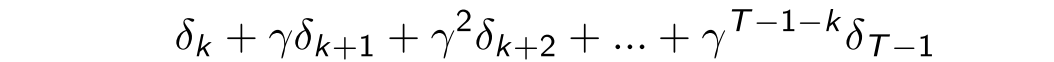
甚至可以进一步证明两者结果上也是完全一样的

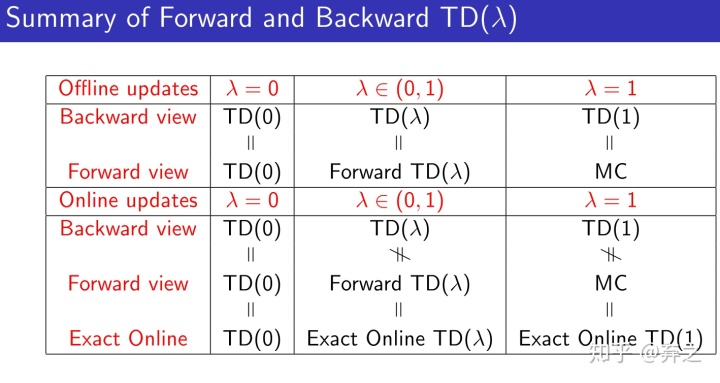
最后做一个总结:
2.model-free control
- Last lecture: Model-free prediction
Estimate the value function of an unknown MDP
- This lecture: Model-free control
Optimise the value function of an unknown MDP
用greedy可能不会explore,陷入局部最优。因此提出了一个折衷,一定概率选择greedy,一定概率选择random策略,然后逐渐减小random策略的权重,到最后减小到0,
Greedy in the Limit with Infinite Exploration (GLIE):所有的state在最后会被explore无限次,最终收敛到greedy policy。
TD也可以做,即Sarsa
2.1.Sarsa:on-policy的学习方法
on-policy的学习方法:行动策略和评估策略一致
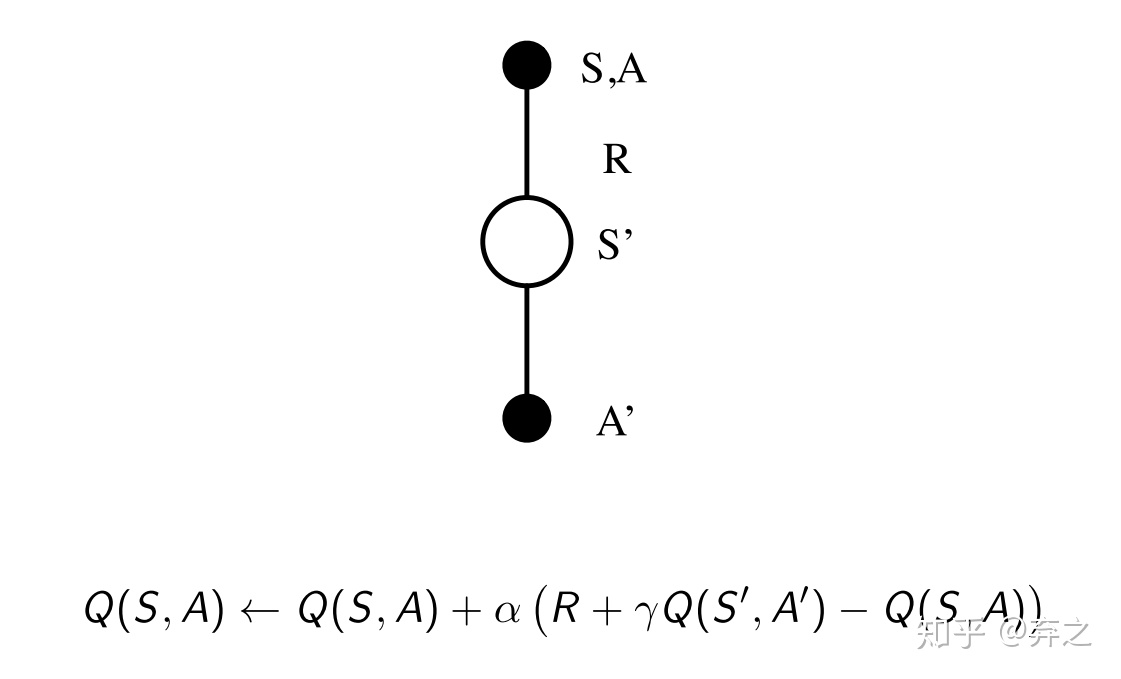

Sarsa全称是state-action-reward-state'-action',采用Q-table来存储q矩阵。Sarsa是一种on-policy的学习方法,上述算法流程中可以看出它的行动策略和评估策略都是ε-greedy策略。Sarsa的流程和分析和第一节中model-free prediciton是一致的,同样有n-step Sarsa以及Sarsa(

Sarsa(
2.2.Q-learning:off-policy
off-policy的学习方法:行动策略和评估策略不一致
在off-policy中,出现了了两个policy
- target policy:评估策略
- behaviour policy:行动策略
这样做的优点在于什么呢?
- 从一个observing human的视角来学习
- 可以在行动中采用一个更加exploratory policy,更好的探索
- 可以同时学多个policy
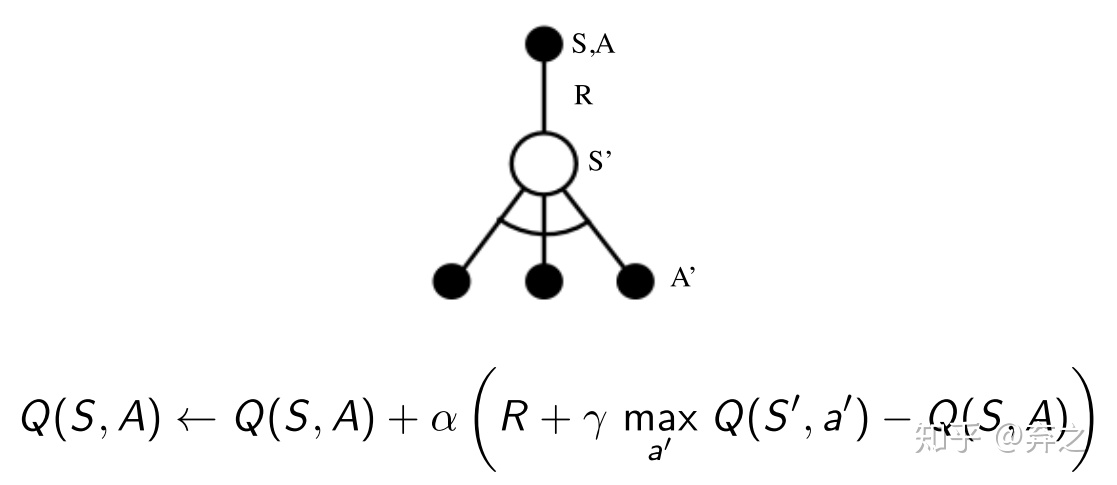

可以看出行为和评估的策略是不同的
importance sampling
在蒙特卡洛积分中我们需要一个分布
在预估分布的时候,有时候我们无法直接进行采样
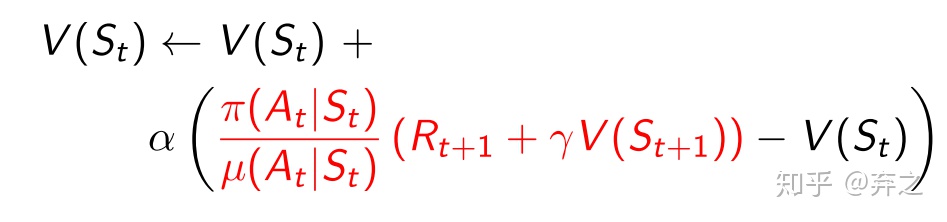
在Q-learning中我们计算的是
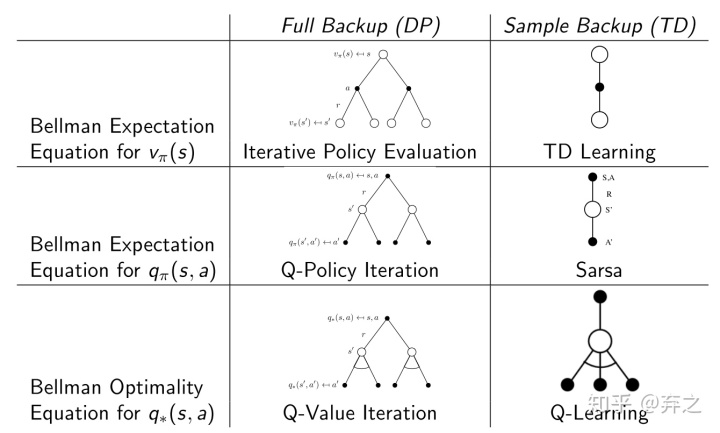
最后总结一下TD,Sarsa和Q-learning
















 6505
6505











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









