






Array
1. 数组定义:有序列,可容纳任意元素, 下标由0开始
1 array = [1, 'Bob', 4.33, 'another string'] 2 puts array.first #=>1 3 p array.last #=>another string 4 p array[2] #=>4.33
2. 修改数组


1 pop, push, <<, unshift 2 array = [1, 'Bob', 4.33, 'another string'] 3 p array.pop #=>"another string" 4 p array #=>[1, "Bob", 4.33] 5 p array.push("another string") #=>[1, "Bob", 4.33, "another string"] 6 p array << "another string" #=>[1, "Bob", 4.33, "another string", "another string"] 7 8 b = ['a', 'b'] ; b.unshift('c') # b = ["c", "a", "b"] 9 10 map,collect,delete,delete_at,uniq,uniq! 11 array = [1, 2, 3, 4] 12 #map对每个元素进行代码块内的操作,返回一个新的数组 13 p array.map{|num| num **2} #=>[1, 4, 9, 16] 14 p array #=>[1, 2, 3, 4] 15 #collect是map的别名 16 p array.collect{|num| num **2} #=>[1, 4, 9, 16] 17 #delete_at 删除index位置的元素 18 p array.delete_at(2),array #=>3, [1, 2, 4] 19 #delete 删除某个值 20 p array.delete(4), array #=>4, [1, 2] 21 22 for i in (1..5) do array.push(i); array.push(i) end 23 #now array:[1, 2, 1, 1, 2, 2, 3, 3, 4, 4, 5, 5] 24 #uniq,遍历数组元素,删除重复值,并返回一个新的数组 25 p array.uniq, array.length #=>[1, 2, 3, 4, 5] , array不变,长度仍为12 26 #uniq!永久删除原数组中的重复元素 27 p array.uniq!, array #=>[1, 2, 3, 4, 5] [1, 2, 3, 4, 5]
3. 遍历数组
1 arr = [] 2 #给数组赋值 3 (1..6).each do |i| 4 arr << i 5 end 6 7 arr.each do |e| 8 p e 9 end 10 11 p arr.select {|num| num > 4} #[5, 6] 12 p arr #[1, 2, 3, 4, 5, 6]
4.Copy
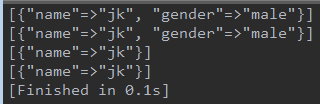
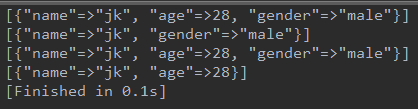
1 Hash copy: (数组同) 2 b = a #a,b指向同一个hash 3 b = a.clone # a,b是两个不同的hash 4 b = a.dup # 与clone效果相同 5 6 但当a中元素的值也为引用时,要注意clone,copy仍然是引用。有坑,调了俩小时才弄明白,要注意: 7 a = [{"name" => "jk", "age"=>28, "gender"=>"male"}] 8 9 param = ["age", "gender"] 10 param.each do |pa| 11 #b = a.clone #wrong output 12 b = [a[0].clone] #success 13 b[0].delete(pa) 14 p a, b 15 end
wrong output:
success:
5. nested arrays(平时用二维数组比较少)
1 nested_arrarys = [[1,2,3],["time","2016-12-6"],[1..20]] 2 p nested_arrarys[2]
6. 数组比较: ==
7. to_s 把数组转换成字符串,ruby在需要的情况下会自动转换。比较的时候可能会用到,如a.to_s.include?("abc")这种
8. 常用方法:
运行[].methods 查看一下,挺多,p [].methods.size 目前是176个。用的ruby是2.3.1p112
1 ##include? 2 a = [1,2] 3 p a.include?(1) #true 4 p a.include?(0) #false 5 ##flatten : 多维数组变一维(二向箔…) 6 nested_arrarys = [[1,2,3],["time","2016-12-6"],[1..20]] 7 p nested_arrarys.flatten #output:[1, 2, 3, "time", "2016-12-6", 1..20] 8 ##each_index:按数组index遍历 9 a = [2,3, 4,5] 10 a.each_index{|i| puts "This is index #{i}"} 11 ##output: 12 ##each_with_index:遍历index和对应value 13 a = [2,3, 4,5] 14 a.each_with_index{|va, i| puts "index:#{i} value:#{va}"} 15 ##sort: 排序 16 a = [3,1,3,7,5,9,0,8] 17 p a.sort #=>[0, 1, 3, 3, 5, 7, 8, 9] 18 p a #=>[3, 1, 3, 7, 5, 9, 0, 8] 19 ##product: combine two arrays in an interesting way 20 p [1, 2, 3].product([4, 5]) #=>[[1, 4], [1, 5], [2, 4], [2, 5], [3, 4], [3, 5]]
Hashes key-value
key和value都可以是多种数据类型
1. 写法:
1 p old_syntax_hash = {:name => 'bob'} #=>{:name=>"bob"} 2 p new_hash = {name: 'bob'} #=>{:name=>"bob"}
2. 访问&赋值&删除
1 p new_hash[:name] #=>"bob" 2 new_hash[:age] = 17 3 p new_hash #{:name=>"bob", :age=>17} 4 new_hash.delete(:name) 5 p new_hash #{:age=>17} 6 3. merge两个hash 7 old_syntax_hash.merge!(new_hash) 8 p old_syntax_hash #=>{:name=>"bob", :age=>17} 9 p new_hash #=>{:age=>17}
3. 遍历:
1 who = {:name => "who", :age => 6, :hobby => "sing"} 2 who.each do |key, value| 3 p "who's #{key} is #{value}" 4 end 5 #"who's name is who" 6 #"who's age is 6" 7 #"who's hobby is sing" 8 9 who = {:name => "who", :age => 6 } 10 who.each_key {|k| p k} #=>:name :age 11 who.each_value {|v| p v} #=> "who" 6
4. 常用方法:
1 ##has_key? 2 fruits = {:apple => "green", :strawberry => "red", :orange => "orange"} 3 p fruits.has_key?(:apple) #=>true 4 p fruits.has_key?("apple") #=>false 5 p fruits.has_key?(:pear) #=>false 6 7 ##select 8 p fruits.select {|k,v| k == :orange} #=>{:orange=>"orange"} 9 p fruits.select {|k,v| v == "orange" || k == :strawberry} 10 #=> {:strawberry=>"red", :orange=>"orange"} 11 12 ##fetch 13 #1.key存在,返回value; 2 key 不存在:打印指定信息;不指定信息,报错 14 p fruits.fetch(:apple) #=>"green" 15 p fruits.fetch(:banana , "banana is gone") #=>"banana is gone" 16 17 ##to_a: 转成array,不改变原值 18 p fruits.to_a #=>[[:apple, "green"], [:strawberry, "red"], [:orange, "orange"]] 19 p fruits #=>{:apple=>"green", :strawberry=>"red", :orange=>"orange"} 20 21 ##keys and values 22 p fruits.keys #=>[:apple, :strawberry, :orange] 23 p fruits.values #=>["green", "red", "orange"]
5. 小练习:
Write a program that prints out groups of words that are anagrams. (anagrams :字母相同,顺序不同而组成的词)
1 words = ['demo', 'none', 'tied', 'evil', 'dome', 2 'fowl', 'veil', 'wolf', 'diet', 'vile', 3 'flow', 'neon'] 4 5 result = {} 6 7 words.each do |word| 8 key = word.split('').sort.join 9 if result.has_key?(key) 10 result[key].push(word) 11 else 12 result[key] = [word] 13 end 14 end 15 16 result.each do |k, v| 17 puts "-------" 18 p v 19 end 20 output: 21 ["demo", "dome"] 22 ------- 23 ["none", "neon"] 24 …… 25 ……














 389
389











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









