






设计了基于DPDK的包捕获系统,以及把包分配到不同队列的hash算法且实现核心的负载均衡。
传统报文处理流程
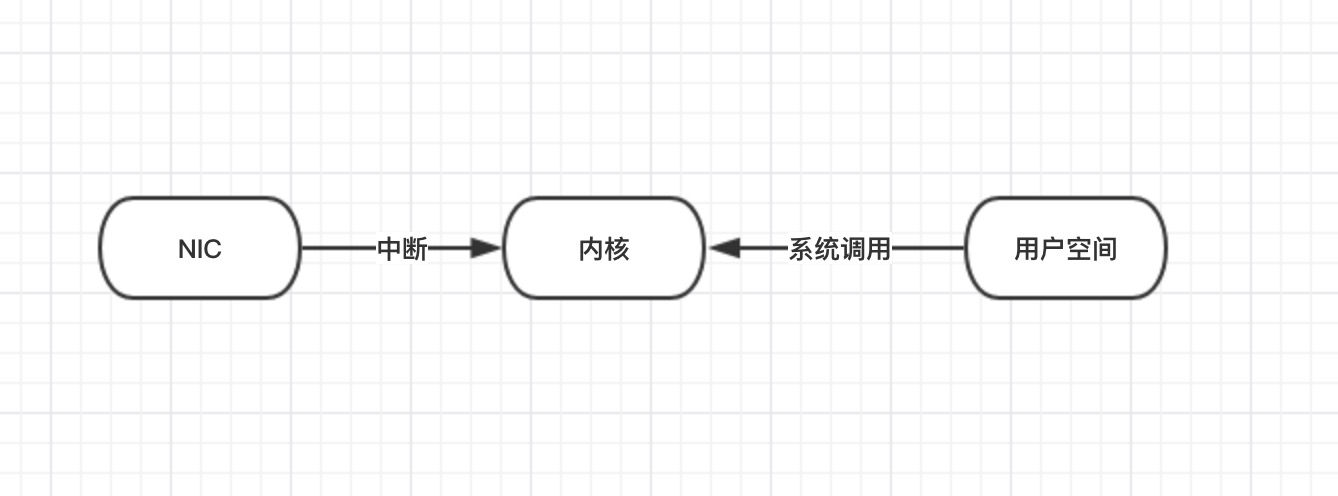
缺点
- 多次中断。
- 多次拷贝,占用总线资源,降低cache利用率。
根据Linux报文处理,分析性能瓶颈
- Linux下也有很多加速数据包捕获的技术。
NAPI技术:用于多个包连续到达的情况。使得一个CPU周期内捕获尽可能多的包。
RSS技术:数据包根据hash算法被分配到多个接收队列,每个队列绑定一个CPU核心和NAPI线程。并行化。
虽然有如此强劲的技术,但是还存在着技术瓶颈。
- 针对单个数据包级别的资源分配和释放.每 当一个数据包到达网卡,系统就会分配一个分组描述符用于存储数据包的信息和头部,直到分组传送到用户态空间,其描述符才被释放。分配与释放造成了很大的资源浪费。
- 流量串行访问。虽然说RSS技术具有并行化的优点。但是这只限于链路层,上层协议栈需要将RSS队列合并,这就造成了单一模块处理数据包、数据包可能乱序的问题。

- 从NIC到用户空间,多次的拷贝浪费时间。
- 中断造成的上下文切换浪费时间。
- 缺少内存本地化,cache不断的被替换,造成miss次数增加。
对传统模式的一些改进
- 预分配、重用内存资源。开始分组接收之前,预先分配好将要到达的数据包所需的内存空间用来存储数据和元数据(分组描述符)。来一个数据包,为之分配一个描述符。等它被送到用户空间时,它所携带的描述符也不会被释放,而是被收回留给下一个数据包使用。
- 数据包采用并行直接通道传递。“RSS队列+CPU核心+用户应用程序”三者直接绑定增加并行性。缺点就是对RSS散列精准度有很大的要求。
- 内存映射,零拷贝。
- 亲和性与预取。
- 内存亲和性: 为进程分配的内存,尽量分配到CPU正在访问的内存块附近。
- CPU亲和性:进程或线程可以自主选择执行它的CPU核心。
- 中断亲和性:软件硬件中断可以自主选择CPU核心来执行中断服务程序。
Intel DPDK
允许用户空间的进程使用DPDK所提供的库直接访问网卡而无需经过内核。
DPDK队列管理
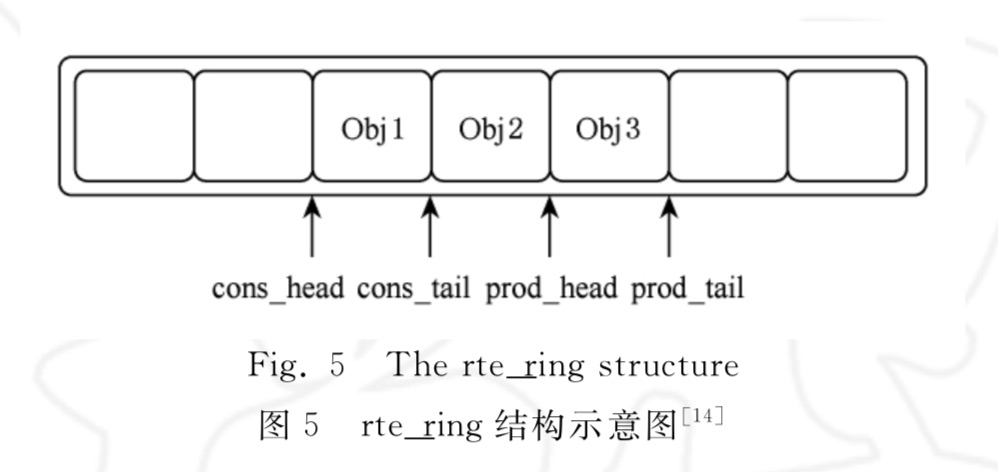
由
librte_ring库提供的rte_ring无锁队列,环形,大小固定,先进先出,单/多生产者/消费者的排队场景,存储对象的指针。各个 P C 有指针来访问控制。相较于普通的用长度不限的双链表实现的队列,有两个好处:无锁、减少突发操作和大量数据传输导致的 cache miss。
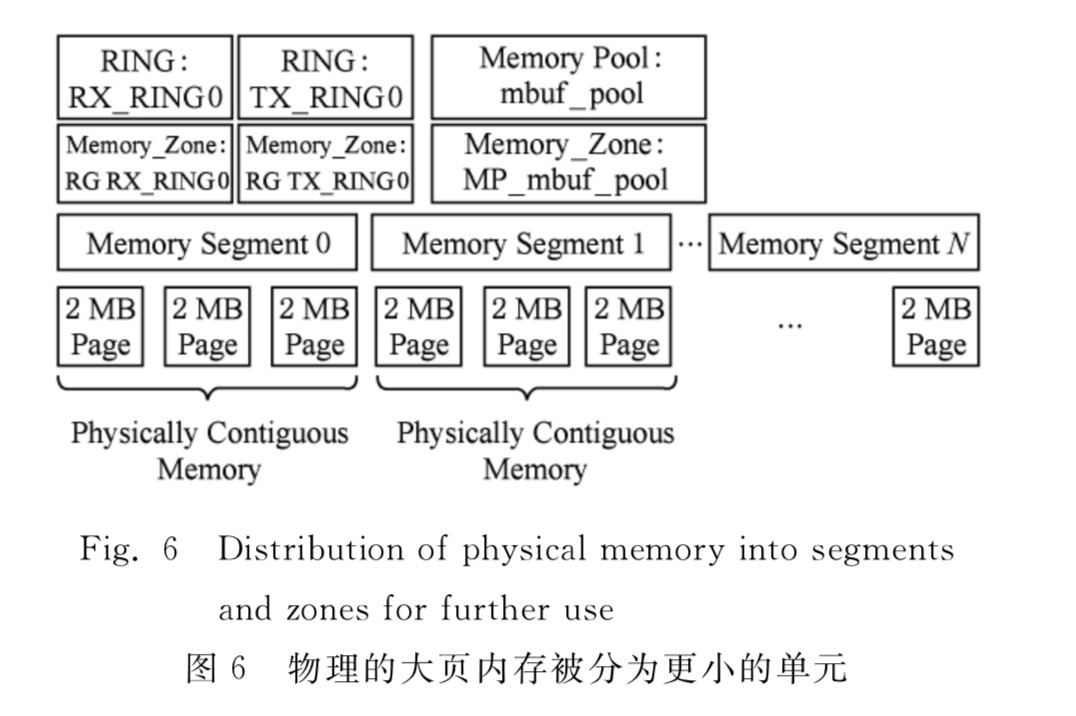
DPDK的内存管理
EAL可以提供物理内存的映射,它会创建一个叫做RTE_memseg的表来将地址上不连续的物理内存映射为可连续访问的。然后将这些内存分成多个内存区域。这些区域是构建于DPDK库之上的应用使用内存的基本单元。这些基本单元用rte_ring来存放。
DPDK缓存管理
lib_mbuf库提供的缓冲区rte_mbuf。缓冲区会在应用程序实际运行之前就被创建出来并存放在内存池中。应用现在可以通过指定mbuf来指定访问某一个mempool。释放一个rte_mbuf只是将回到它来自的mempool。为了容纳更大的数据包的元数据,可以将多个rte_mbuf链接在一起。说白了就是程序通过rte_mbuf来申请内存。















 1346
1346











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









