






今日内容概要
1、cookie操作
2、pipeline
3、中间件
4、扩展
5、自定义命令
6、scrapy-redis
7、flask使用
- 路由系统
- 视图
- 模版
- message(闪现)
- 中间件
- session
- 蓝图
- 安装第三方插件


Scrapy - 创建project - 创建爬虫 - 编写 - 类 - start_urls = ['http://www.xxx.com'] - def parse(self,response): yield Item对象 yield Request对象 - pipeline - process_item @classmethod - from_clawer - open_spider - close_spider 配置 - request对象("地址",回调函数) - 执行 高性能相关: - 多线程【IO】和多进程【计算】 - 尽可能利用线程: 一个线程(Gevent),基于协程: - 协程,greenlet - 遇到IO就切换 一个线程(Twisted,Tornado),基于事件循环: - IO多路复用 - Socket,setBlocking(Flase)
一、scrapy补充
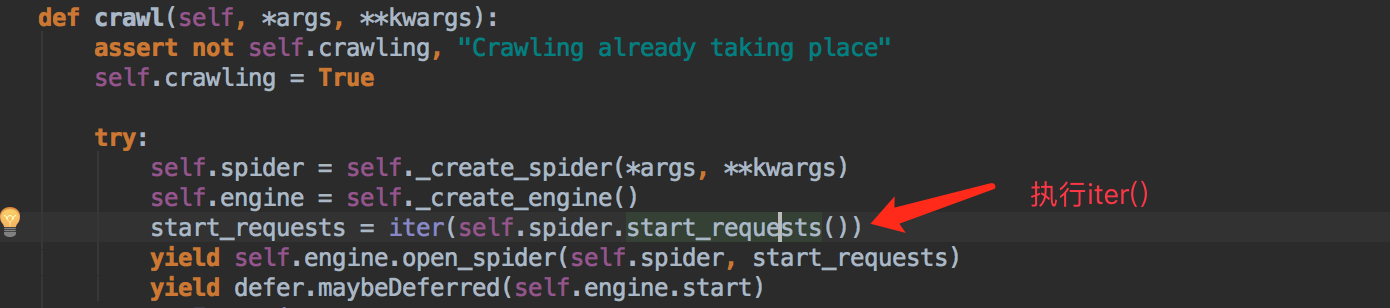
start_requests
支持返回值有两种(scrapy内部通过会执行iter()):
一、生成器yield Request
二、可迭代对象 [url1,url2,url3]
通过源码查看源码入口:
from scrapy.crawler import Crawler
Crawler.crawl 方法
例子:
def start_requests(self):
for url in self.start_urls:
yield Request(url=url,callback=self.parse)
# return [Request(url=url,callback=self.parse),]
***迭代器和可迭代对象的区别:
迭代器,具有__next__方法,并逐一向后取值
li = [11,22,33] #迭代器有iter和next方法
obj = iter(li)
obj.__next__()
可迭代对象,具有__iter__方法,返回迭代器
li = list([11,22,33]) //可迭代对象没有next方法
迭代器 = li.__iter__()
生成器,函数中具有yield关键字
__iter__
__next__
迭代器 = iter(obj)















 359
359











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









