






Django打造大型企业官网-项目实战(四)
一、新闻相关功能
在项目实战三中,我们完成了新闻分类相关的一些功能,现在我们来完成新闻列表、发布新闻、编辑新闻、删除新闻的功能
1、发布新闻/编辑新闻 功能实现
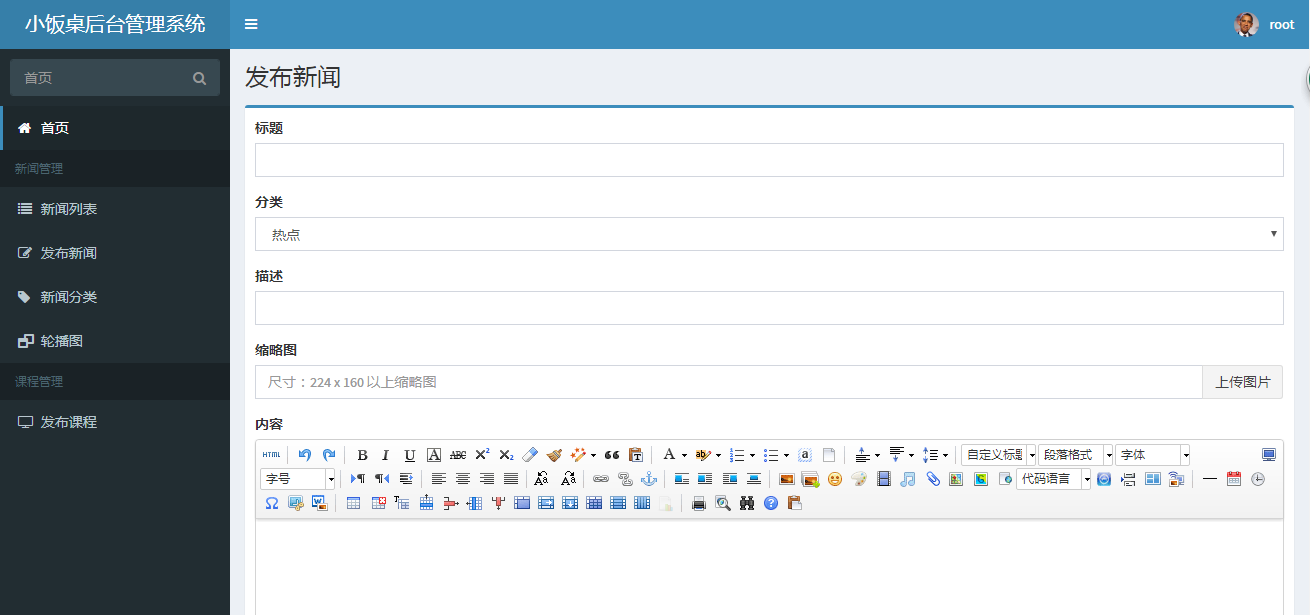
发布新闻、编辑新闻结合了 UEditor 富文本编辑器,关于UEditor编辑器使用,可参考随笔:https://www.cnblogs.com/Eric15/p/11022175.html
1)HTML前端代码:发布新闻/编辑新闻 共用
HTML代码 + UEditor 编辑器 + jQuery


{% extends 'crm/base.html' %}
{% block title %}
{% if news %}
编辑新闻
{% else %}
发布新闻
{% endif %}
{% endblock %}
{% block head %}
{# <script src="https://unpkg.com/qiniu-js@2.4.0/dist/qiniu.min.js"></script>#}
<script src="{% static 'ueditor/ueditor.config.js' %}"></script>
<script src="{% static 'ueditor/ueditor.all.min.js' %}"></script>
{# <script src="{% static 'js/write_news.min.js' %}"></script>#}
{% endblock %}
{% block content-header %}
<h1>
{% if news %}
编辑新闻
{% else %}
发布新闻
{% endif %}
</h1>
{% endblock %}
{% block content %}
<div class="row">
<div class="col-md-12">
<div class="box box-primary">
<form method="post" class="form">
{% csrf_token %}
<div class="box-body">
<div class="form-group">
<label for="title-form">标题</label>
{% if news %}
<input type="text" class="form-control" required name="title" id="title-form" value="{{ news.title }}"> {% else %}
<input type="text" class="form-control" required name="title" id="title-form">
{% endif %}
</div>
<div class="form-group">
<label for="category-form">分类</label>
<select name="category" id="category-form" class="form-control">
{% for category in categories %}
{% if news and news.category_id == category.id %}
<option value="{{ category.id }}" selected>{{ category.name }}</option>
{% else %}
<option value="{{ category.id }}">{{ category.name }}</option>
{% endif %}
{% endfor %}
</select>
</div>
<div class="form-group">
<label for="desc-form">描述</label>
{% if news %}
<input type="text" class="form-control" required id="desc-form" name="desc" value="{{ news.desc }}"> {% else %}
<input type="text" class="form-control" required id="desc-form" name="desc">
{% endif %}
</div>
<div class="form-group">
<label for="thumbnail-form">缩略图</label>
<div class="input-group">
{% if news %}
<input type="text" class="form-control" required id="thumbnail-file" name="thumbnail" value="{{ news.thumbnail }}" placeholder="尺寸:224 x 160 以上缩略图">
{% else %}
<input type="text" class="form-control" required id="thumbnail-file" name="thumbnail" placeholder="尺寸:224 x 160 以上缩略图">
{% endif %}
<span class="input-group-btn">
<label class="btn btn-default btn-file">
上传图片<input hidden type="file" class="btn btn-default" id="thumbnail-btn">
</label>
</span>
</div>
</div>
<div id="progress-group" class="form-group" style="display: none;">
<div class="progress">
<div class="progress-bar progress-bar-success progress-bar-striped" role="progressbar"
aria-valuenow="40" aria-valuemin="0" aria-valuemax="100" style="width: 0">
0%
</div>
</div>
</div>
<div class="form-group">
<label for="content-form">内容</label>
<script id="editor" type="text/plain">
{{ news.content|safe }}
</script>
<input type="hidden"name="id" value="{{ news.id }}">
</div>
</div>
<div class="box-footer">
<button id="submit-btn" class="btn btn-primary pull-right">发布新闻</button>
</div>
</form>
</div>
</div>
</div>
{% endblock %}
{% block front-js %}
<script>
// 初始化 ueditor
$(function () {
window.ue = UE.getEditor('editor',{ // window.ue 全局变量
'initialFrameHeight': 400, // ueditor 高度
'serverUrl': '{% url "ueditor:upload" %}' // ueditor 服务端url
})
});
// 文件上传
$("#thumbnail-btn").change(function () { // 上传图片/文件,同时将上传成功后图片的路径显示到输入框中
var uploadBtn = $("#thumbnail-btn");
var file = uploadBtn[0].files[0]; // 可上传多个文件,取第一个
// 上传成功获取到的file内容: File(66809) {name: "01.jpg", lastModified: 1483186816000, lastModifiedDate: Sat Dec 31 2016 20:20:16 GMT+0800 (中国标准时间), webkitRelativePath: "", size: 66809, …}
var formData = new FormData(); // 上传文件是可以使用这种FromData的方式
formData.append('file',file);
$.ajax({
'url': "{% url 'upload_file' %}",
'data': formData,
type: 'post',
headers:{"X-CSRFToken":"{{ csrf_token }}"},
'processData': false, //告诉jQuery不要去处理发送的数据, 默认为true
'contentType': false, // 告诉jQuery不要去设置Content-Type请求头
'success':function (result) {
if(result['status'] === true){
var url = result['url'];
$("#thumbnail-file").val(url);
}
}
})
});
// ajax方式 提交表单数据
$("#submit-btn").click(function (event) {
event.preventDefault(); // 阻止使用传统的表单提交方式,即form表单提交方式
var id = $("input[name='id']").val(); // 用于判断当前提交方式是 新增新闻 还是 编辑新闻提交
var title = $("input[name='title']").val();
var category = $("select[name='category']").val();
var desc = $("input[name='desc']").val();
var thumbnail = $("input[name='thumbnail']").val();
var content = window.ue.getContent(); // 获取 UEditor 内容数据
// alert(id);
var url = "";
if(id){
url = "crm/edit_news/"+id+"/" // 编辑新闻 提交表单
}else {
url = "{% url 'add_news' %}" // 新增新闻 提交表单
}
$.ajax({
'url': url,
'data': {
'title': title,
'category': category,
'desc': desc,
'thumbnail': thumbnail,
'content': content,
// 'id': id
},
type: 'post',
headers:{"X-CSRFToken":"{{ csrf_token }}"},
'success':function (result) {
alert(result['message']);
if(result['status'] === true){
window.location.reload();
}
}
})
})
</script>
{% endblock %}
2)views:后端代码
发布新闻:
class AddNews(View): """新增新闻""" def get(self, request): categories = NewsCategory.objects.all() return render(request, 'crm/edit_news.html', {"categories": categories}) def post(self, request): news_form = NewsForm(request.POST) if news_form.is_valid(): # news_form.save() # 也可以直接用此种方法,如果是更新则不能用 title = news_form.cleaned_data.get('title') desc = news_form.cleaned_data.get('desc') thumbnail = news_form.cleaned_data.get('thumbnail') content = news_form.cleaned_data.get('content') category = news_form.cleaned_data.get('category') News.objects.create(title=title, desc=desc, thumbnail=thumbnail, content=content, category=category, author=request.user) return JsonResponse({'status': True, 'message': '恭喜!新闻已发布成功!'}) else: return JsonResponse({'status': False, 'message': '输入数据有误,新闻无法发布!'})
编辑新闻:
class EditNews(View): """编辑新闻""" def get(self, request, news_id): news = News.objects.get(id=news_id) categories = NewsCategory.objects.all() return render(request, 'crm/edit_news.html', {'news': news, 'categories': categories}) def post(self, request, news_id): news_obj = News.objects.filter(id=news_id).first() news_form = NewsForm(request.POST, instance=news_obj) if news_form.is_valid(): title = news_form.cleaned_data.get('title') desc = news_form.cleaned_data.get('desc') thumbnail = news_form.cleaned_data.get('thumbnail') content = news_form.cleaned_data.get('content') category = news_form.cleaned_data.get('category') News.objects.filter(id=news_id).update(title=title, desc=desc, thumbnail=thumbnail, content=content, category=category) return JsonResponse({"status": True, "message": "恭喜!新闻更新成功并完成发布!"}) else: return JsonResponse({"status": False, "message": "数据更改有误,新闻更新失败!"})
3)forms.py:发布新闻/编辑新闻 共用
from django import forms from news.models import News class NewsForm(forms.ModelForm): """新闻""" class Meta: # models中将author设置可为null,pub_time自动添加,因此我们可以不用另加 exclude 字段限制(剔除不需要的字段) model = News fields = "__all__"
4)urls.py:
from django.urls import path, re_path from crm import views urlpatterns = [ path("add_news/", views.AddNews.as_view(), name='add_news'), # crm 管理后台 新增新闻 path("add_news/upload_file", views.upload_file, name='upload_file'), # crm 管理后台 新增新闻[上传缩略图] re_path("edit_news/(\w+)/$", views.EditNews.as_view(), name='edit_news'), # crm 管理后台 编辑新闻 ]
5)缩略图上传相关js代码已经集成到 edit_news.html 中 ,后端代码如下:
@require_POST def upload_file(request): """新闻缩略图上传""" file = request.FILES.get('file') name = file.name with open(os.path.join(settings.MEDIA_ROOT, 'news', 'images', name), 'wb') as fp: # 图片保存路径 for chunk in file.chunks(): fp.write(chunk) url = request.build_absolute_uri(settings.MEDIA_URL+"news/"+"images/"+name) # url 返回给前端显示 return JsonResponse({"status": True, "url": url})
二、django-rest -framework 实现:首页展示新闻文章篇数,通过点击 '加载更多',异步加载更多文章篇数
原理:根据前端传递的页码,目前指定一页显示两篇文章,每点击一次 '加载更多' 则加载多一页的文章(即两篇),后端拿到页码,获取相应的文章数据并序列化传回给前端。传统做法:News.objects.all().value()[start:end],获取到的是字典类型(最外层还是QuerySet)对象,可序列化后传递到前端使用。但这种方式碰到带有外键字段的会有所缺陷,即外键字段只能获取到相应的外键id,如外键关联作者,获取到的只有id数值:author_id: 2 ,而外键关联的作者其他数据并不能获取到。
此时,可以使用django-rest -framework 来实现后端数据无损序列化。
关于django-rest-framework 可参考链接:https://www.cnblogs.com/Eric15/articles/9532648.html
1、虚拟环境下安装 django-rest-framework
pip install djangorestframework
2、在settings.py/INSTALLED_APP 中注册:
记得 makemigrations 、migrate 生成表数据
INSTALLED_APPS = [ '…', 'rest_framework', ]
3、使用django-rest-framework 下的serializers 序列化
后端代码相关
1)序列化 serializers.py:
# user/serializers.py from rest_framework import serializers from users.models import UserProfile class UserSerializer(serializers.ModelSerializer): class Meta: model = UserProfile fields = ('id', 'mobile', 'username', 'email', 'employee', 'is_active') # news/serializers.py from rest_framework import serializers from news.models import News,NewsCategory, Comment, Banner from users.serializers import UserSerializer class NewsCategorySerializer(serializers.ModelSerializer): class Meta: model = NewsCategory fields = ('id', 'name') class NewsSerializer(serializers.ModelSerializer): category = NewsCategorySerializer() author = UserSerializer() class Meta: model = News fields = ('id', 'title', 'desc', 'thumbnail', 'pub_time', 'category', 'author')
2)views.py:
from django.http import JsonResponse from xfz.settings import ONE_PAGE_NEWS_COUNT, INDEX_CATEGORY_COUNT from news.models import News, NewsCategory from news.serializers import NewsSerializer def news_list(request): # 通过 p 参数,来指定要获取第几页的数据, 通过新闻分类category_id获取该分类下新闻数据 # p category_id 参数是通过查询字符串的方式传递过来的:/news/list/?p=2&category_id=1 page = int(request.GET.get('p', 1)) # 分类为0是,表示不进行任何分类,直接按照时间倒序排序,在models.py中已经默认新闻数据按倒序排序 category_id = int(request.GET.get("category_id", 0)) start = (page - 1) * ONE_PAGE_NEWS_COUNT end = start + ONE_PAGE_NEWS_COUNT if category_id == 0: # 不考虑新闻分类限制 newses = News.objects.select_related('category', 'author').all()[start:end] else: newses = News.objects.select_related('category', 'author').filter(category__id=category_id)[start:end] serializer = NewsSerializer(newses, many=True) data = serializer.data # 序列化后数据保存在serializers.data中 return JsonResponse({"status": True, "data": data}) # 转换成json格式
3)urls.py:
from django.urls import path from . import views urlpatterns = [ path("news_list/", views.news_list, name='news_list'), # 新闻列表 ]
4)前端html代码:包括功能→ 时间日期过滤器、点击'加载更多' 加载更多文章、点击'新闻分类'如'热点' 加载更多热点相关新闻
{% load news_filters %}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>{% block title %}小饭桌{% endblock %}</title>
<link rel="stylesheet" href="{% static 'css/news/index.min.css' %}">
<script src="{% static 'js/jquery-3.3.1.min.js' %}"></script>
<script src="{% static 'js/index.min.js' %}"></script>
<script src="{% static 'arttemplate/template-web.js' %}"></script>
<script id="news-item" type="text/html">
{% verbatim %} <!-- verbatim 内代码不转义 js动态添加新闻列表 -->
{{ each newses news index }}
<li>
<div class="thumbnail-group">
<a href="/news/detail/{{ news.id }}/">
<img src="{{ news.thumbnail }}" alt="">
</a>
</div>
<div class="news-group">
<p class="title">
<a href="/news/detail/{{ news.id }}">{{ news.title }}</a>
</p>
<p class="desc">
{{ news.desc }}
</p>
<p class="more">
<span class="category">{{ news.category.name }}</span>
<span class="pub-time">{{ news.pub_time|timeSince }}</span>
<span class="author">{{ news.author.username }}</span>
</p>
</div>
</li>
{{ /each }}
{% endverbatim %}
</script>
</head>
<body>
<!-- 导航栏 -->
<header class="header">
<div class="container">
<!-- logo -->
<div class="logo-box">
<a href=""></a>
</div>
<!-- 主体中间部分 标题 -->
<div class="nav">
<ul class="daohangtiao">
<li {% if request.path|slice:'5' == '/news' %}class="active"{% endif %} ><a href="{% url 'index' %}">资讯</a></li>
<li {% if request.path|slice:'8' == '/courses' %}class="active"{% endif %} ><a class="chuangyeketang" href="{% url 'course' %}">创业课堂</a></li>
<li><a class="qiyefuwu" href="#">企业服务</a></li>
<li {% if request.path|slice:'8' == '/payinfo' %}class="active"{% endif %} ><a href="{% url 'payinfo' %}">付费资讯</a></li>
<li {% if request.path|slice:'7' == '/search' %}class="active"{% endif %} ><a href="{% url 'search' %}">搜索</a></li>
</ul>
<div class="nav-float">
<ul class="ketang">
<li><a href="#">在线课堂</a></li>
<li><a href="#">线下课堂</a></li>
</ul>
<ul class="qiye">
<li><a href="#">创业礼包</a></li>
<li><a href="#">企业资讯</a></li>
</ul>
</div>
</div>
<!-- 登录注册 -->
<div class="auth-box">
{% if request.user.is_authenticated%}
<div class="auth-login">
<div class="personal">
<div class="user">
<p class="current-user">{{ request.user }}</p>
<span class="top-down"><img src="{% static 'images/auth/top_down.png' %}"/></span>
<span class="touxiang"><img width="45" height="45" src="{{ MEDIA_URL }}{{ request.user.image }}"/></span>
</div>
</div>
</div>
<div class="userdetail">
<div class="personal-info">
<span><img width="60" height="60" src="{{ MEDIA_URL }}{{ request.user.image }}"/></span>
<div class="user-info">
<h2>{{ request.user }}</h2>
<p>{{ request.user.employee }}111</p>
</div>
</div>
<div class="personal-center">
{% if request.user.is_staff %}
<a class="personcenter" href="{% url 'crm_index' %}">后台管理系统</a>
{% endif %}
<a class="fr" href="{% url 'auth_logout' %}">退出</a>
</div>
</div>
{% else %}
<p class="personal-p"></p>
<div class="auth-login">
<a href="{% url 'auth_login' %}">登录 |</a>
<a href="{% url 'auth_register' %}"> 注册</a>
</div>
{% endif %}
</div>
</div>
</header>
{% block body %}
<!-- body主体[中间部分] -->
<div class="main">
<div class="wrapper">
{% block left-content %}
<!-- 内容左边[新闻部分] -->
<div class="main-content-wrapper">
<!-- 轮播图 -->
<div class="banner-group" id="banner-group">
<ul class="banner-ul" id="banner-ul">
<li>
<a href="#">
<img src="{% static 'images/banners/lunbo_2.jpeg' %}" alt="">
</a>
</li>
<li>
<a href="#">
<img src="{% static 'images/banners/lunbo_3.jpg' %}" alt="">
</a>
</li>
<li>
<a href="#">
<img src="{% static 'images/banners/lunbo_4.jpg' %}" alt="">
</a>
</li>
<li>
<a href="#">
<img src="{% static 'images/banners/lunbo_5.png' %}" alt="">
</a>
</li>
</ul>
<ul class="num">
<li class="current"><a href="#">1</a></li>
<li><a href="#">2</a></li>
<li><a href="#">3</a></li>
<li><a href="#">4</a></li>
</ul>
<span class="left-btn btn">‹</span>
<span class="right-btn btn">›</span>
</div>
<!-- 新闻主体 -->
<div class="news-list-group">
<div class="news-inner">
<ul class="list-tab">
<li id="news-category-val" data-category="0" {% if category_id == 0 %}class="active"{% endif %} οnclick="categoryAction(this)"><a href="javascript:void(0)">最新资讯</a></li>
{% for news_category in news_categories %}
<li id="news-category-val" data-category="{{ news_category.id }}" {% if category_id == news_category.id %}class="active"{% endif %} οnclick="categoryAction(this)"><a href="javascript:void(0)">{{ news_category.name }}</a></li>
{% endfor %}
</ul>
<div>
<a href="{% url 'news_categories' %}" class="category-more">更多</a>
</div>
<!-- 新闻list -->
<ul class="news-list">
{% for news in news_list %}
<li>
<div class="thumbnail-group">
<a href="{% url 'news_detail' news.id %}">
<img src={{ news.thumbnail }}
alt="">
</a>
</div>
<div class="news-group">
<p class="title">
<a href="{% url 'news_detail' news.id %}">{{ news.title }}</a>
</p>
<p class="desc">
{{ news.desc }}
</p>
<p class="more">
<span class="category">{{ news.category }}</span>
<span class="pub-time">{{ news.pub_time|time_since }}</span>
<span class="author">{{ news.author }}</span>
</p>
</div>
</li>
{% endfor %}
</ul>
<div class="load-more-group">
<button class="load-more" id="load-more-btn">查看更多</button>
</div>
</div>
</div>
</div>
{% endblock %}
{% block right-wrapper %}
<!-- 内容右边[侧边栏] -->
<div class="sidebar-wrapper">
<div class="online-class">
<span class="class-title">在线课堂</span>
<span class="more"><a href="#">更多</a></span>
</div>
<div class="hot-advertist">
<a href="#">
<img src="{% static 'images/build/hot-advertist.png' %}" alt="">
</a>
</div>
<div class="platform-group">
<div class="online-class">
<span class="class-title">关注小饭桌</span>
</div>
<div class="focus-group">
<ul class="left-group">
<li class="zhihu">
<a href="#" target="_blank">小饭桌创业课堂</a>
</li>
<li class="weibo">
<a href="#" target="_blank">小饭桌创业课堂</a>
</li>
<li class="toutiao">
<a href="#" target="_blank">小饭桌</a>
</li>
</ul>
<div class="right-group">
<p class="desc">扫码关注小饭桌微信公众平台xfz008</p>
</div>
</div>
</div>
<div class="hot-news-group">
<div class="online-class">
<span class="class-title">热门推荐</span>
</div>
<ul class="hot-list-group">
<li>
<div class="left-group">
<p class="title">
<a href="#">王健林卖掉进军海外首个项目:17亿售伦敦ON...</a>
</p>
<p class="more">
<span class="category"><a href="#">深度报道</a></span>
<span class="pub-time">1小时前</span>
</p>
</div>
<div class="right-group">
<a href="#">
<img src="{% static 'images/build/hot-news_01.png' %}" alt="">
</a>
</div>
</li>
<li>
<div class="left-group">
<p class="title">
<a href="#">王健林卖掉进军海外首个项目:17亿售伦敦ON...</a>
</p>
<p class="more">
<span class="category"><a href="#">深度报道</a></span>
<span class="pub-time">1小时前</span>
</p>
</div>
<div class="right-group">
<a href="#">
<img src="{% static 'images/build/hot-news_01.png' %}" alt="">
</a>
</div>
</li>
</ul>
</div>
</div>
{% endblock %}
</div>
</div>
{% endblock %}
<!-- footer -->
<footer class="footer">
<div class="top-group">
<div class="top-inner-group">
<div class="logo-box"></div>
<div class="detail-group">
<div class="line1">
<ul class="links">
<li><a href="#">关于小饭桌</a></li>
<li><a href="#">创业课堂</a></li>
<li><a href="#">寻求报道</a></li>
<li><a href="#">创业礼包</a></li>
</ul>
<div class="about-us">
<span class="title">关于我们:</span>
<ul class="social-group">
<li class="weixin">
<div class="wx-qrcode"></div>
<span class="text">xfz2019</span>
</li>
<li class="weibo">
<a href="#" class="text">小饭桌创业课堂</a>
</li>
</ul>
</div>
</div>
<div class="line2">
<p class="address">
地址:北京市朝阳区东三环北路38号院1号楼17层2001内1、16室
</p>
<p class="contact">
联系方式:400-810-1090(工作日10点-18点)
</p>
</div>
</div>
</div>
</div>
<div class="bottom-group">
©2017 北京子木投资顾问有限公司 京ICP备15051289号-1
</div>
</footer>
<script>
var page = 2; // 全局变量
$(function () {
timeSince(); // 自定义时间日期过滤器
// 点击'加载更多' - 加载更多新闻功能
$("#load-more-btn").click(function () {
var category_id = $(".list-tab li.active").attr('data-category');
$.ajax({
'url': "{% url 'news_list' %}",
type: 'get',
'data': {"p":page, "category_id":category_id},
'success': function (result) {
if(result['status'] === true){
var newses = result['data'];
if(newses.length > 0){
var tpl = template("news-item",{"newses":newses}); // 第三方插件 ,加载新闻列表
var ul = $(".news-list");
ul.append(tpl); // append 新闻列表
page += 1; // 每点击一次 page+1
}else{
$("#load-more-btn").hide();
page = 2;
}
}
}
})
})
});
// 点击新闻分类 - 加载新闻列表数据
function categoryAction(self) {
var li = $(self);
page = 2; // 每切换一种分类,让page重新初始化,即page=2
var category_id = li.attr("data-category");
// var page = 1;
$.ajax({
'url': "{% url 'news_list' %}",
type: 'get',
'data': {"p":"1", "category_id":category_id},
'success': function (result) {
if(result['status'] === true){
var newses = result['data'];
var tpl = template("news-item",{"newses":newses}); // 第三方插件 ,加载新闻列表
var ul = $(".news-list");
ul.empty(); // 清空旧新闻列表
ul.append(tpl); // append 新的新闻列表
li.addClass("active").siblings().removeClass("active");
$("#load-more-btn").show();
}
}
})
}
// 自定义时间日期过滤器
function timeSince() {
if(template){
template.defaults.imports.timeSince = function (dateValue) {
var date = new Date(dateValue);
var datets = date.getTime(); // 得到的是毫秒的
var nowts = (new Date()).getTime(); //得到的是当前时间的时间戳
var timestamp = (nowts - datets)/1000; // 除以1000,得到的是秒
if(timestamp < 60) {
return '刚刚';
}
else if(timestamp >= 60 && timestamp < 60*60) {
minutes = parseInt(timestamp / 60);
return minutes+'分钟前';
}
else if(timestamp >= 60*60 && timestamp < 60*60*24) {
hours = parseInt(timestamp / 60 / 60);
return hours+'小时前';
}
else if(timestamp >= 60*60*24 && timestamp < 60*60*24*30) {
days = parseInt(timestamp / 60 / 60 / 24);
return days + '天前';
}else{
var year = date.getFullYear();
var month = date.getMonth();
var day = date.getDay();
var hour = date.getHours();
var minute = date.getMinutes();
return year+'/'+month+'/'+day+" "+hour+":"+minute;
}
}
}
}
</script>
</body>
</html>
三、django-debug-toolbar 使用介绍
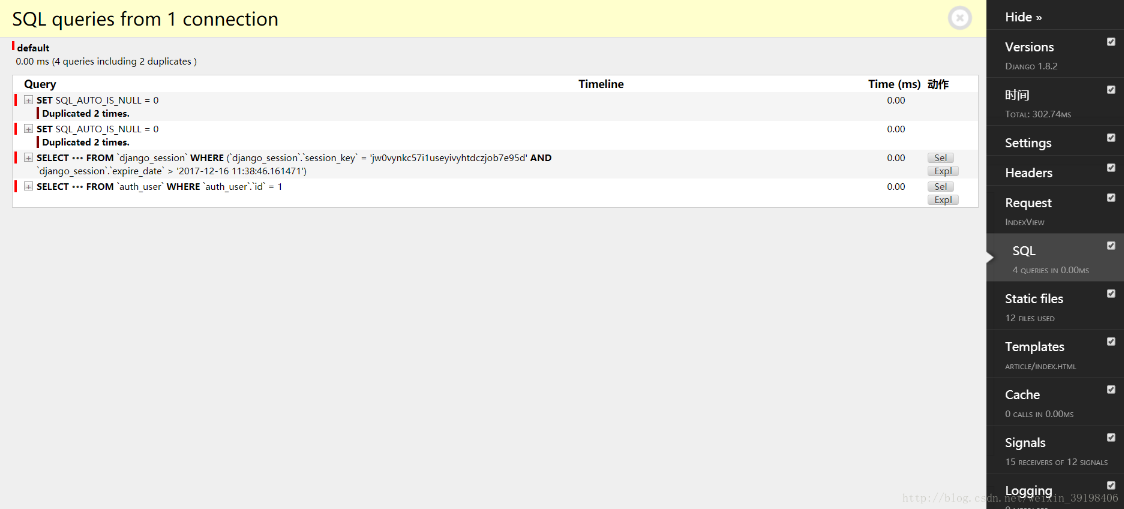
django_debug_toolbar 是django的第三方工具包,给django扩展了很多便利的调试功能。包括查看执行的sql语句、db查询次数、request、headers、调试概览等
界面:
1、虚拟环境下安装:
pip install django_debug_toolbar
2、settings.py中配置:
1)INSTALLED_APPS 注册:
需要注意的是,debug_toolbar要放在django.contrib.staticfiles 之后,当然不要理解为紧跟着django.contrib.staticfiles后面,只要在后面即可
INSTALLED_APPS = [ # ... 'django.contrib.staticfiles', # ... 'debug_toolbar', # 这个 ]
2)Middleware 中间件配置:
MIDDLEWARE_CLASSES = [ # ... 'debug_toolbar.middleware.DebugToolbarMiddleware', # ... ]
在settings中的MIDDLEWARE配置’debug_toolbar.middleware.DebugToolbarMiddleware’,我们要把django-debug-toolbar这个中间件尽可能配置到最前面,但是,必须要要放在处理编码和响应内容的中间件后面,比如我们要是使用了GZipMiddleware,就要把DebugToolbarMiddleware放在GZipMiddleware后面。
如下图,我没有使用到处理编码和响应内容的中间件后面,所以直接放在了最前面

3)配置 IP 地址
我们需要在settings.py文件中配置INTERNAL_IPS,只有访问这里面配置的ip地址时, Debug Toolbar才是展示出来。因为我们一般都是本地开发,所以,直接配置为127.0.0.1就可以了
# settings.py INTERNAL_IPS = ("127.0.0.1",)
3、url路由配置:
urlpatterns = [ "…" ] if settings.DEBUG: # 只有在debug 模式下,才能使用django-debug-toolbar import debug_toolbar urlpatterns.append(path("__debug__/", include(debug_toolbar.urls)))
简单配置后,我们启动项目,前端界面就会显示一个 DjDt 图标,用于 django-debug-toolbar 调试:

点击 DjDT 图标,展开详细信息:
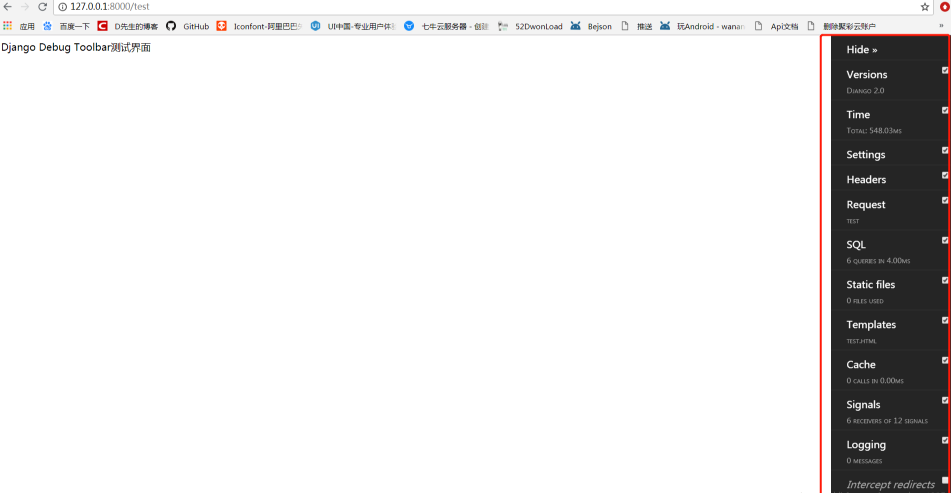
4、django-debug-toolbar 面板介绍
- Versions :代表是哪个django版本
- Timer : 用来计时的,判断加载当前页面总共花的时间
- Settings : 读取django中的配置信息
- Headers : 当前请求头和响应头信息
- Request: 当前请求的想信息(视图函数,Cookie信息,Session信息等)
- SQL:查看当前界面执行的SQL语句
- StaticFiles:当前界面加载的静态文件
- Templates:当前界面用的模板
- Cache:缓存信息
- Signals:信号
- Logging:当前界面日志信息
- Redirects:当前界面的重定向信息
自定义django-debug-toolbar面板:
# settings.py DEBUG_TOOLBAR_PANELS = [ # 代表是哪个django版本 'debug_toolbar.panels.versions.VersionsPanel', # 用来计时的,判断加载当前页面总共花的时间 'debug_toolbar.panels.timer.TimerPanel', # 读取django中的配置信息 'debug_toolbar.panels.settings.SettingsPanel', # 看到当前请求头和响应头信息 'debug_toolbar.panels.headers.HeadersPanel', # 当前请求的想信息(视图函数,Cookie信息,Session信息等) 'debug_toolbar.panels.request.RequestPanel', # 查看SQL语句 'debug_toolbar.panels.sql.SQLPanel', # 静态文件 'debug_toolbar.panels.staticfiles.StaticFilesPanel', # 模板文件 'debug_toolbar.panels.templates.TemplatesPanel', # 缓存 'debug_toolbar.panels.cache.CachePanel', # 信号 'debug_toolbar.panels.signals.SignalsPanel', # 日志 'debug_toolbar.panels.logging.LoggingPanel', # 重定向 'debug_toolbar.panels.redirects.RedirectsPanel',
可通过在settings.py 中自定义 DEBUG_TOOLBAR_PANELS 面板选项,在前端DrDTV面板中展示我们所需要的面板信息
5、debug_toolbar 配置项:
默认为如下选项,不写则按如下默认,可根据需要调整
# settings.py CONFIG_DEFAULTS = { # Toolbar options 'DISABLE_PANELS': {'debug_toolbar.panels.redirects.RedirectsPanel'}, 'INSERT_BEFORE': '</body>', 'JQUERY_URL': '//cdn.bootcss.com/jquery/2.1.4/jquery.min.js', 'RENDER_PANELS': None, 'RESULTS_CACHE_SIZE': 10, 'ROOT_TAG_EXTRA_ATTRS': '', 'SHOW_COLLAPSED': False, 'SHOW_TOOLBAR_CALLBACK': 'debug_toolbar.middleware.show_toolbar', # Panel options 'EXTRA_SIGNALS': [], 'ENABLE_STACKTRACES': True, 'HIDE_IN_STACKTRACES': ( 'socketserver' if six.PY3 else 'SocketServer', 'threading', 'wsgiref', 'debug_toolbar', 'django', ), 'PROFILER_MAX_DEPTH': 10, 'SHOW_TEMPLATE_CONTEXT': True, 'SKIP_TEMPLATE_PREFIXES': ( 'django/forms/widgets/', 'admin/widgets/', ), 'SQL_WARNING_THRESHOLD': 500, # milliseconds
需要注意的一点是:CONFIG_DEFAULTS 中 'JQUERY_URL': '//cdn.bootcss.com/jquery/2.1.4/jquery.min.js' 指向的是Google 下的 js文件,属国外网(服务器),在国内引用容易造成网络慢或404页面的错误,因此,在使用django-debug-toolbar时,建议将 'JQUERY_URL' 设置指向国内相关js,如:'JQUERY_URL': '//cdn.bootcss.com/jquery/2.1.4/jquery.min.js' , 如果在项目中有引用 jquery.min.js 文件,也可以直接配置为空,本项目中便是这样配置的。
# django-debug-toolbar 配置 DEBUG_TOOLBAR_CONFIG = { 'JQUERY_URL': '' }
四、实现搜索功能
1、普通方式实现搜索功能
适用于数据不是特别多的场景
后端代码实现:views.py
from django.shortcuts import render from django.db.models import Q from courses.models import Course def search(request): """搜索""" search_field = request.GET.get("q", "") if search_field: newses = News.objects.select_related("category", "author").filter(Q(title__icontains=search_field)|Q(content__icontains=search_field)) return render(request, 'search/search.html', locals()) else: hot_newses = News.objects.select_related("category", "author")[0:4] #热门推荐 return render(request, 'search/search.html', {"hot_newses": hot_newses})
urls.py:
urlpatterns = [ path("search/", search, name='search'), ]
前端代码实现:search.html
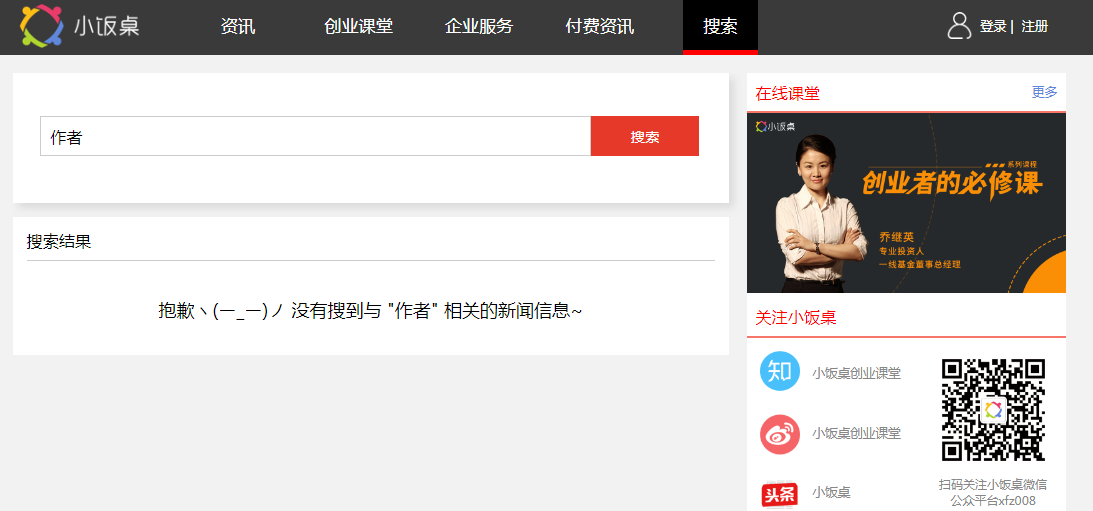
{% extends 'front_base.html' %} {% block title %}搜索{% endblock %} {% block front-css %} <link rel="stylesheet" href="{% static 'css/search/search.min.css' %}"> {% endblock %} {% block left-content %} <!-- 内容左边 --> <div class="main-content-wrapper"> <!-- 搜索 --> <div class="search-group"> <form action="" method="get"> <input type="text" name="q" class="search-input" placeholder="可输入新闻内容、简介关键字" value="{{ search_field }}"> <input type="submit" class="search-btn" value="搜索"> </form> </div> {% if newses %} <div class="recommend-group"> <p class="recommend-title">搜索结果</p> <ul class="recommend-list"> {% for news in newses %} <li> <div class="thumbnail-group"> <a href="{% url 'news_detail' news.id %}"> <img src="{{ news.thumbnail }}" alt=""> </a> </div> <div class="news-group"> <p class="title"> <a href="{% url 'news_detail' news.id %}">{{ news.title }}</a> </p> <p class="desc"> {{ news.desc }} </p> <p class="more"> <span class="category">{{ news.category.name }}</span> <span class="pub-time">{{ news.pub_time|timesince }}</span> <span class="author">{{ news.author.username }}</span> </p> </div> </li> {% endfor %} </ul> </div> {% elif hot_newses %} <!-- 热门推荐 --> <div class="recommend-group"> <p class="recommend-title">热门推荐</p> <ul class="recommend-list"> {% for hot_news in hot_newses %} <li> <div class="thumbnail-group"> <a href="{% url 'news_detail' hot_news.id %}"> <img src="{{ hot_news.thumbnail }}" alt=""> </a> </div> <div class="news-group"> <p class="title"> <a href="{% url 'news_detail' hot_news.id %}">{{ hot_news.title }}</a> </p> <p class="desc"> {{ hot_news.desc }} </p> <p class="more"> <span class="category">{{ hot_news.category.name }}</span> <span class="pub-time">{{ hot_news.pub_time|timesince }}</span> <span class="author">{{ hot_news.author.username }}</span> </p> </div> </li> {% endfor %} </ul> <!-- <div class="load-more-group"> <button class="load-more">查看更多</button> </div> --> </div> {% else %} <div class="recommend-group"> <p class="recommend-title">搜索结果</p> <p style="width: 100%;height: 100px;text-align: center;line-height: 100px; font-size: 20px">抱歉ヽ(ー_ー)ノ 没有搜到与 "{{ search_field }}" 相关的新闻信息~</p> </div> {% endif %} </div> {% endblock %} {% block right-wrapper %} <!-- 内容右边[侧边栏] --> <div class="sidebar-wrapper"> <div class="online-class"> <span class="class-title">在线课堂</span> <span class="more"><a href="#">更多</a></span> </div> <div class="hot-advertist"> <a href="#"> <img src="{% static 'images/build/hot-advertist.png' %}" alt=""> </a> </div> <div class="platform-group"> <div class="online-class"> <span class="class-title">关注小饭桌</span> </div> <div class="focus-group"> <ul class="left-group"> <li class="zhihu"> <a href="#" target="_blank">小饭桌创业课堂</a> </li> <li class="weibo"> <a href="#" target="_blank">小饭桌创业课堂</a> </li> <li class="toutiao"> <a href="#" target="_blank">小饭桌</a> </li> </ul> <div class="right-group"> <p class="desc">扫码关注小饭桌微信公众平台xfz008</p> </div> </div> </div> <div class="hot-news-group"> <div class="online-class"> <span class="class-title">热门课程</span> </div> <ul class="hot-list-group"> <li> <div class="left-group"> <p class="title"> <a href="#">对赌是什么?该不该做对赌...</a> </p> <p class="more"> <span class="category"><a href="#">知了课堂CEO</a></span> <span class="price free">免费</span> </p> </div> <div class="right-group"> <a href="#"> <img src="{% static 'images/course/1513577022_550.png' %}" alt=""> </a> </div> </li> <li> <div class="left-group"> <p class="title"> <a href="#">对赌是什么?该不该做对赌...</a> </p> <p class="more"> <span class="category"><a href="#">知了课堂CEO</a></span> <span class="price pay">¥19.9</span> </p> </div> <div class="right-group"> <a href="#"> <img src="{% static 'images/course/1513577022_550.png' %}" alt=""> </a> </div> </li> </ul> </div> </div> {% endblock %}
界面:
2、使用 django-haystack实现全文搜索
1)django-haystack插件:
django-haystack 插件,是专门给 django 提供搜索功能的。django-haystack 提供了一个搜索的接口,底层可以根据自己的需求更好搜索引擎。它其实有点类似于 django 中的ORM 插件,提供了一个操作数据库的接口,但是底层具体使用哪个数据库是可以自己设置的。安装方式也非常简单,通过 pip install django-haystack 即可安装
2)搜索引擎:
django-haystack 支持的搜索引擎有 Solr 、Elasticsearch 、Whoosh 、Xapian 等,whoosh 是基于纯python 的搜索引擎,检索速度快,集成方便,因此这里我们就选择 Whoosh 来作为 haystack 的搜索引擎。 安装方式同样是通过 pip 安装的:pip install whoosh
注意:django-haystack 适用于 数据比较多的场景(上千万、上亿数据),如果数据量较少,使用普通的搜索方式就可以了
3)集成步骤:
3.1)在项目中安装 django-haystack 、Whoosh
pip install django-haystack
pip install whoosh
3.2)在 INSTALLED_APPS 中注册 django-haystack:
INSTALLED_APPS = [ 'haystack', # django-haystack ]
3.3)在settings.py 中配置相应的搜索引擎:
# 全局搜索django-haystack 配置 HAYSTACK_CONNECTIONS = { 'default': { # 设置 haystack 的搜索引擎 'ENGINE': 'haystack.backends.whoosh_backend.WhooshEngine', # 设置索引文件的位置,同时在项目目录中新建 whoosh_index 文件夹 'PATH': os.path.join(BASE_DIR, 'whoosh_index'), } }
3.4)在 相应的 app目录下新建一个 search_indexes.py 文件,然后创建索引类。比如要给 news app 创建索引,在news 目录下新建 search_indexes.py 文件 ,里面代码编写:
# news.py/search_indexes.py from haystack import indexes from news.models import News class NewsIndex(indexes.SearchIndex, indexes.Indexable): text = indexes.CharField(document=True, use_template=True) # 为了方便,必须取名为 text def get_model(self): return News def index_queryset(self, using=None): return self.get_model().objects.all()
3.5)索引创建好了,需要指定字段为索引的字段,如本例中使用 news models下的news表 中的 title 、content 作为索引字段 , 步骤:
在 templates 目录下新建 search 文件夹 → 进入search 目录 ,新建子文件夹:indexes → 进入 indexes 目录,再新建 news子文件夹(对应 news app) → 进入 news 目录下,新建txt文件:news_text.txt (命名规则:appname_索引name)→ 最后,在 news_text.txt 文件中指定索引字段:
# templates/search/indexes/news/news_text.txt {{ object.title }} # title 为索引字段 {{ object.content }} # content 为索引字段
3.6)urls.py 映射:
urlpatterns = [ path("search/", include("haystack.urls")), ]
3.7)templates/search 文件夹下创建 search.html 模板文件, haystack 会自动的在 templates 文件夹下寻找这个模板文件然后渲染,并且会给这个模板文件传入 page、paginator 、query 等参数。其中 page 和 paginator 分别是django内置的Page类和Paginator类的对象,query 是查询的关键字, 我们可以通过 page.object_list 获取到查找出来的数据。
从 page.object_list 获取所有 newses 数据 ,但此时的 newses 数据类型并不是QuerySet ,需要 for 循环操作取出 每一个 news 相关数据,再通过 .object 语法获取到我们要的 news 数据 。代码实现如下:
<ul class="recommend-list"> {% for result in page.object_list %} {% with result.object as news %} # news = result.object <li> <div class="thumbnail-group"> <a href="{% url 'news_detail' news.id %}"> <img src="{{ news.thumbnail }}" alt=""> </a> </div> <div class="news-group"> <p class="title"> <a href="{% url 'news_detail' news.id %}">{{ news.title }}</a> </p> <p class="desc"> {{ news.desc }} </p> <p class="more"> <span class="category">{{ news.category.name }}</span> <span class="pub-time">{{ news.pub_time|timesince }}</span> <span class="author">{{ news.author.username }}</span> </p> </div> </li> {% endwith %} {% endfor %} </ul>
3.8)上述工作都处理好了,在启动项目 运用搜索功能前,我们需要先进行创建索引指令操作:
# 在 pycharm 下的 manage.py 下执行创建索引指令: rebuild_index # 直接创建索引指令: python manage.py rebuild_index

这样,便创建完索引,可以使用 django-haystack搜索功能了
4)使用 jieba 分词替换 Whoosh 默认的分词
Whoosh 默认是采用正则表达式进行分词的,这对于英文来说是足够了,但是对于中文却支持不好。因此我们需要替换该默认分词为 jieba 分词,jieba分词是中文分词中最好用的免费的分词库,但对英文分词比较不是很友好,要使用 jieba 分词库,需要通过 pip install jieba 进行安装
安装完成后,我们采取 Whoosh与 jieba 分词相结合的方式来实现适用于英文、中文的搜索。在 news app 目录下创建一个名为 whoosh_cn_backend.py 的文件 ,把下述代码复制粘贴到里面
# whoosh_cn_backend.py # encoding: utf-8 from __future__ import absolute_import, division, print_function, unicode_literals import json import os import re import shutil import threading import warnings from django.conf import settings from django.core.exceptions import ImproperlyConfigured from django.utils import six from django.utils.datetime_safe import datetime from django.utils.encoding import force_text from haystack.backends import BaseEngine, BaseSearchBackend, BaseSearchQuery, EmptyResults, log_query from haystack.constants import DJANGO_CT, DJANGO_ID, ID from haystack.exceptions import MissingDependency, SearchBackendError, SkipDocument from haystack.inputs import Clean, Exact, PythonData, Raw from haystack.models import SearchResult from haystack.utils import log as logging from haystack.utils import get_identifier, get_model_ct from haystack.utils.app_loading import haystack_get_model try: import whoosh except ImportError: raise MissingDependency("The 'whoosh' backend requires the installation of 'Whoosh'. Please refer to the documentation.") # Handle minimum requirement. if not hasattr(whoosh, '__version__') or whoosh.__version__ < (2, 5, 0): raise MissingDependency("The 'whoosh' backend requires version 2.5.0 or greater.") # Bubble up the correct error. from whoosh import index from whoosh.analysis import StemmingAnalyzer from whoosh.fields import ID as WHOOSH_ID from whoosh.fields import BOOLEAN, DATETIME, IDLIST, KEYWORD, NGRAM, NGRAMWORDS, NUMERIC, Schema, TEXT from whoosh.filedb.filestore import FileStorage, RamStorage from whoosh.highlight import highlight as whoosh_highlight from whoosh.highlight import ContextFragmenter, HtmlFormatter from whoosh.qparser import QueryParser from whoosh.searching import ResultsPage from whoosh.writing import AsyncWriter DATETIME_REGEX = re.compile('^(?P<year>\d{4})-(?P<month>\d{2})-(?P<day>\d{2})T(?P<hour>\d{2}):(?P<minute>\d{2}):(?P<second>\d{2})(\.\d{3,6}Z?)?$') LOCALS = threading.local() LOCALS.RAM_STORE = None import jieba from whoosh.analysis import Tokenizer, Token class ChineseTokenizer(Tokenizer): def __call__(self, value, positions=False, chars=False, keeporiginal=False, removestops=True, start_pos=0, start_char=0, mode='', **kwargs): t = Token(positions, chars, removestops=removestops, mode=mode, **kwargs) seglist = jieba.cut(value, cut_all=True) for w in seglist: t.original = t.text = w t.boost = 1.0 if positions: t.pos = start_pos + value.find(w) if chars: t.startchar = start_char + value.find(w) t.endchar = start_char + value.find(w) + len(w) yield t def ChineseAnalyzer(): return ChineseTokenizer() class WhooshHtmlFormatter(HtmlFormatter): """ This is a HtmlFormatter simpler than the whoosh.HtmlFormatter. We use it to have consistent results across backends. Specifically, Solr, Xapian and Elasticsearch are using this formatting. """ template = '<%(tag)s>%(t)s</%(tag)s>' class WhooshSearchBackend(BaseSearchBackend): # Word reserved by Whoosh for special use. RESERVED_WORDS = ( 'AND', 'NOT', 'OR', 'TO', ) # Characters reserved by Whoosh for special use. # The '\\' must come first, so as not to overwrite the other slash replacements. RESERVED_CHARACTERS = ( '\\', '+', '-', '&&', '||', '!', '(', ')', '{', '}', '[', ']', '^', '"', '~', '*', '?', ':', '.', ) def __init__(self, connection_alias, **connection_options): super(WhooshSearchBackend, self).__init__(connection_alias, **connection_options) self.setup_complete = False self.use_file_storage = True self.post_limit = getattr(connection_options, 'POST_LIMIT', 128 * 1024 * 1024) self.path = connection_options.get('PATH') if connection_options.get('STORAGE', 'file') != 'file': self.use_file_storage = False if self.use_file_storage and not self.path: raise ImproperlyConfigured("You must specify a 'PATH' in your settings for connection '%s'." % connection_alias) self.log = logging.getLogger('haystack') def setup(self): """ Defers loading until needed. """ from haystack import connections new_index = False # Make sure the index is there. if self.use_file_storage and not os.path.exists(self.path): os.makedirs(self.path) new_index = True if self.use_file_storage and not os.access(self.path, os.W_OK): raise IOError("The path to your Whoosh index '%s' is not writable for the current user/group." % self.path) if self.use_file_storage: self.storage = FileStorage(self.path) else: global LOCALS if getattr(LOCALS, 'RAM_STORE', None) is None: LOCALS.RAM_STORE = RamStorage() self.storage = LOCALS.RAM_STORE self.content_field_name, self.schema = self.build_schema(connections[self.connection_alias].get_unified_index().all_searchfields()) self.parser = QueryParser(self.content_field_name, schema=self.schema) if new_index is True: self.index = self.storage.create_index(self.schema) else: try: self.index = self.storage.open_index(schema=self.schema) except index.EmptyIndexError: self.index = self.storage.create_index(self.schema) self.setup_complete = True def build_schema(self, fields): schema_fields = { ID: WHOOSH_ID(stored=True, unique=True), DJANGO_CT: WHOOSH_ID(stored=True), DJANGO_ID: WHOOSH_ID(stored=True), } # Grab the number of keys that are hard-coded into Haystack. # We'll use this to (possibly) fail slightly more gracefully later. initial_key_count = len(schema_fields) content_field_name = '' for field_name, field_class in fields.items(): if field_class.is_multivalued: if field_class.indexed is False: schema_fields[field_class.index_fieldname] = IDLIST(stored=True, field_boost=field_class.boost) else: schema_fields[field_class.index_fieldname] = KEYWORD(stored=True, commas=True, scorable=True, field_boost=field_class.boost) elif field_class.field_type in ['date', 'datetime']: schema_fields[field_class.index_fieldname] = DATETIME(stored=field_class.stored, sortable=True) elif field_class.field_type == 'integer': schema_fields[field_class.index_fieldname] = NUMERIC(stored=field_class.stored, numtype=int, field_boost=field_class.boost) elif field_class.field_type == 'float': schema_fields[field_class.index_fieldname] = NUMERIC(stored=field_class.stored, numtype=float, field_boost=field_class.boost) elif field_class.field_type == 'boolean': # Field boost isn't supported on BOOLEAN as of 1.8.2. schema_fields[field_class.index_fieldname] = BOOLEAN(stored=field_class.stored) elif field_class.field_type == 'ngram': schema_fields[field_class.index_fieldname] = NGRAM(minsize=3, maxsize=15, stored=field_class.stored, field_boost=field_class.boost) elif field_class.field_type == 'edge_ngram': schema_fields[field_class.index_fieldname] = NGRAMWORDS(minsize=2, maxsize=15, at='start', stored=field_class.stored, field_boost=field_class.boost) else: schema_fields[field_class.index_fieldname] = TEXT(stored=True, analyzer=ChineseAnalyzer(), field_boost=field_class.boost, sortable=True) if field_class.document is True: content_field_name = field_class.index_fieldname schema_fields[field_class.index_fieldname].spelling = True # Fail more gracefully than relying on the backend to die if no fields # are found. if len(schema_fields) <= initial_key_count: raise SearchBackendError("No fields were found in any search_indexes. Please correct this before attempting to search.") return (content_field_name, Schema(**schema_fields)) def update(self, index, iterable, commit=True): if not self.setup_complete: self.setup() self.index = self.index.refresh() writer = AsyncWriter(self.index) for obj in iterable: try: doc = index.full_prepare(obj) except SkipDocument: self.log.debug(u"Indexing for object `%s` skipped", obj) else: # Really make sure it's unicode, because Whoosh won't have it any # other way. for key in doc: doc[key] = self._from_python(doc[key]) # Document boosts aren't supported in Whoosh 2.5.0+. if 'boost' in doc: del doc['boost'] try: writer.update_document(**doc) except Exception as e: if not self.silently_fail: raise # We'll log the object identifier but won't include the actual object # to avoid the possibility of that generating encoding errors while # processing the log message: self.log.error(u"%s while preparing object for update" % e.__class__.__name__, exc_info=True, extra={"data": {"index": index, "object": get_identifier(obj)}}) if len(iterable) > 0: # For now, commit no matter what, as we run into locking issues otherwise. writer.commit() def remove(self, obj_or_string, commit=True): if not self.setup_complete: self.setup() self.index = self.index.refresh() whoosh_id = get_identifier(obj_or_string) try: self.index.delete_by_query(q=self.parser.parse(u'%s:"%s"' % (ID, whoosh_id))) except Exception as e: if not self.silently_fail: raise self.log.error("Failed to remove document '%s' from Whoosh: %s", whoosh_id, e, exc_info=True) def clear(self, models=None, commit=True): if not self.setup_complete: self.setup() self.index = self.index.refresh() if models is not None: assert isinstance(models, (list, tuple)) try: if models is None: self.delete_index() else: models_to_delete = [] for model in models: models_to_delete.append(u"%s:%s" % (DJANGO_CT, get_model_ct(model))) self.index.delete_by_query(q=self.parser.parse(u" OR ".join(models_to_delete))) except Exception as e: if not self.silently_fail: raise if models is not None: self.log.error("Failed to clear Whoosh index of models '%s': %s", ','.join(models_to_delete), e, exc_info=True) else: self.log.error("Failed to clear Whoosh index: %s", e, exc_info=True) def delete_index(self): # Per the Whoosh mailing list, if wiping out everything from the index, # it's much more efficient to simply delete the index files. if self.use_file_storage and os.path.exists(self.path): shutil.rmtree(self.path) elif not self.use_file_storage: self.storage.clean() # Recreate everything. self.setup() def optimize(self): if not self.setup_complete: self.setup() self.index = self.index.refresh() self.index.optimize() def calculate_page(self, start_offset=0, end_offset=None): # Prevent against Whoosh throwing an error. Requires an end_offset # greater than 0. if end_offset is not None and end_offset <= 0: end_offset = 1 # Determine the page. page_num = 0 if end_offset is None: end_offset = 1000000 if start_offset is None: start_offset = 0 page_length = end_offset - start_offset if page_length and page_length > 0: page_num = int(start_offset / page_length) # Increment because Whoosh uses 1-based page numbers. page_num += 1 return page_num, page_length @log_query def search(self, query_string, sort_by=None, start_offset=0, end_offset=None, fields='', highlight=False, facets=None, date_facets=None, query_facets=None, narrow_queries=None, spelling_query=None, within=None, dwithin=None, distance_point=None, models=None, limit_to_registered_models=None, result_class=None, **kwargs): if not self.setup_complete: self.setup() # A zero length query should return no results. if len(query_string) == 0: return { 'results': [], 'hits': 0, } query_string = force_text(query_string) # A one-character query (non-wildcard) gets nabbed by a stopwords # filter and should yield zero results. if len(query_string) <= 1 and query_string != u'*': return { 'results': [], 'hits': 0, } reverse = False if sort_by is not None: # Determine if we need to reverse the results and if Whoosh can # handle what it's being asked to sort by. Reversing is an # all-or-nothing action, unfortunately. sort_by_list = [] reverse_counter = 0 for order_by in sort_by: if order_by.startswith('-'): reverse_counter += 1 if reverse_counter and reverse_counter != len(sort_by): raise SearchBackendError("Whoosh requires all order_by fields" " to use the same sort direction") for order_by in sort_by: if order_by.startswith('-'): sort_by_list.append(order_by[1:]) if len(sort_by_list) == 1: reverse = True else: sort_by_list.append(order_by) if len(sort_by_list) == 1: reverse = False sort_by = sort_by_list if facets is not None: warnings.warn("Whoosh does not handle faceting.", Warning, stacklevel=2) if date_facets is not None: warnings.warn("Whoosh does not handle date faceting.", Warning, stacklevel=2) if query_facets is not None: warnings.warn("Whoosh does not handle query faceting.", Warning, stacklevel=2) narrowed_results = None self.index = self.index.refresh() if limit_to_registered_models is None: limit_to_registered_models = getattr(settings, 'HAYSTACK_LIMIT_TO_REGISTERED_MODELS', True) if models and len(models): model_choices = sorted(get_model_ct(model) for model in models) elif limit_to_registered_models: # Using narrow queries, limit the results to only models handled # with the current routers. model_choices = self.build_models_list() else: model_choices = [] if len(model_choices) > 0: if narrow_queries is None: narrow_queries = set() narrow_queries.add(' OR '.join(['%s:%s' % (DJANGO_CT, rm) for rm in model_choices])) narrow_searcher = None if narrow_queries is not None: # Potentially expensive? I don't see another way to do it in Whoosh... narrow_searcher = self.index.searcher() for nq in narrow_queries: recent_narrowed_results = narrow_searcher.search(self.parser.parse(force_text(nq)), limit=None) if len(recent_narrowed_results) <= 0: return { 'results': [], 'hits': 0, } if narrowed_results: narrowed_results.filter(recent_narrowed_results) else: narrowed_results = recent_narrowed_results self.index = self.index.refresh() if self.index.doc_count(): searcher = self.index.searcher() parsed_query = self.parser.parse(query_string) # In the event of an invalid/stopworded query, recover gracefully. if parsed_query is None: return { 'results': [], 'hits': 0, } page_num, page_length = self.calculate_page(start_offset, end_offset) search_kwargs = { 'pagelen': page_length, 'sortedby': sort_by, 'reverse': reverse, } # Handle the case where the results have been narrowed. if narrowed_results is not None: search_kwargs['filter'] = narrowed_results try: raw_page = searcher.search_page( parsed_query, page_num, **search_kwargs ) except ValueError: if not self.silently_fail: raise return { 'results': [], 'hits': 0, 'spelling_suggestion': None, } # Because as of Whoosh 2.5.1, it will return the wrong page of # results if you request something too high. :( if raw_page.pagenum < page_num: return { 'results': [], 'hits': 0, 'spelling_suggestion': None, } results = self._process_results(raw_page, highlight=highlight, query_string=query_string, spelling_query=spelling_query, result_class=result_class) searcher.close() if hasattr(narrow_searcher, 'close'): narrow_searcher.close() return results else: if self.include_spelling: if spelling_query: spelling_suggestion = self.create_spelling_suggestion(spelling_query) else: spelling_suggestion = self.create_spelling_suggestion(query_string) else: spelling_suggestion = None return { 'results': [], 'hits': 0, 'spelling_suggestion': spelling_suggestion, } def more_like_this(self, model_instance, additional_query_string=None, start_offset=0, end_offset=None, models=None, limit_to_registered_models=None, result_class=None, **kwargs): if not self.setup_complete: self.setup() field_name = self.content_field_name narrow_queries = set() narrowed_results = None self.index = self.index.refresh() if limit_to_registered_models is None: limit_to_registered_models = getattr(settings, 'HAYSTACK_LIMIT_TO_REGISTERED_MODELS', True) if models and len(models): model_choices = sorted(get_model_ct(model) for model in models) elif limit_to_registered_models: # Using narrow queries, limit the results to only models handled # with the current routers. model_choices = self.build_models_list() else: model_choices = [] if len(model_choices) > 0: if narrow_queries is None: narrow_queries = set() narrow_queries.add(' OR '.join(['%s:%s' % (DJANGO_CT, rm) for rm in model_choices])) if additional_query_string and additional_query_string != '*': narrow_queries.add(additional_query_string) narrow_searcher = None if narrow_queries is not None: # Potentially expensive? I don't see another way to do it in Whoosh... narrow_searcher = self.index.searcher() for nq in narrow_queries: recent_narrowed_results = narrow_searcher.search(self.parser.parse(force_text(nq)), limit=None) if len(recent_narrowed_results) <= 0: return { 'results': [], 'hits': 0, } if narrowed_results: narrowed_results.filter(recent_narrowed_results) else: narrowed_results = recent_narrowed_results page_num, page_length = self.calculate_page(start_offset, end_offset) self.index = self.index.refresh() raw_results = EmptyResults() searcher = None if self.index.doc_count(): query = "%s:%s" % (ID, get_identifier(model_instance)) searcher = self.index.searcher() parsed_query = self.parser.parse(query) results = searcher.search(parsed_query) if len(results): raw_results = results[0].more_like_this(field_name, top=end_offset) # Handle the case where the results have been narrowed. if narrowed_results is not None and hasattr(raw_results, 'filter'): raw_results.filter(narrowed_results) try: raw_page = ResultsPage(raw_results, page_num, page_length) except ValueError: if not self.silently_fail: raise return { 'results': [], 'hits': 0, 'spelling_suggestion': None, } # Because as of Whoosh 2.5.1, it will return the wrong page of # results if you request something too high. :( if raw_page.pagenum < page_num: return { 'results': [], 'hits': 0, 'spelling_suggestion': None, } results = self._process_results(raw_page, result_class=result_class) if searcher: searcher.close() if hasattr(narrow_searcher, 'close'): narrow_searcher.close() return results def _process_results(self, raw_page, highlight=False, query_string='', spelling_query=None, result_class=None): from haystack import connections results = [] # It's important to grab the hits first before slicing. Otherwise, this # can cause pagination failures. hits = len(raw_page) if result_class is None: result_class = SearchResult facets = {} spelling_suggestion = None unified_index = connections[self.connection_alias].get_unified_index() indexed_models = unified_index.get_indexed_models() for doc_offset, raw_result in enumerate(raw_page): score = raw_page.score(doc_offset) or 0 app_label, model_name = raw_result[DJANGO_CT].split('.') additional_fields = {} model = haystack_get_model(app_label, model_name) if model and model in indexed_models: for key, value in raw_result.items(): index = unified_index.get_index(model) string_key = str(key) if string_key in index.fields and hasattr(index.fields[string_key], 'convert'): # Special-cased due to the nature of KEYWORD fields. if index.fields[string_key].is_multivalued: if value is None or len(value) is 0: additional_fields[string_key] = [] else: additional_fields[string_key] = value.split(',') else: additional_fields[string_key] = index.fields[string_key].convert(value) else: additional_fields[string_key] = self._to_python(value) del(additional_fields[DJANGO_CT]) del(additional_fields[DJANGO_ID]) if highlight: sa = StemmingAnalyzer() formatter = WhooshHtmlFormatter('em') terms = [token.text for token in sa(query_string)] whoosh_result = whoosh_highlight( additional_fields.get(self.content_field_name), terms, sa, ContextFragmenter(), formatter ) additional_fields['highlighted'] = { self.content_field_name: [whoosh_result], } result = result_class(app_label, model_name, raw_result[DJANGO_ID], score, **additional_fields) results.append(result) else: hits -= 1 if self.include_spelling: if spelling_query: spelling_suggestion = self.create_spelling_suggestion(spelling_query) else: spelling_suggestion = self.create_spelling_suggestion(query_string) return { 'results': results, 'hits': hits, 'facets': facets, 'spelling_suggestion': spelling_suggestion, } def create_spelling_suggestion(self, query_string): spelling_suggestion = None reader = self.index.reader() corrector = reader.corrector(self.content_field_name) cleaned_query = force_text(query_string) if not query_string: return spelling_suggestion # Clean the string. for rev_word in self.RESERVED_WORDS: cleaned_query = cleaned_query.replace(rev_word, '') for rev_char in self.RESERVED_CHARACTERS: cleaned_query = cleaned_query.replace(rev_char, '') # Break it down. query_words = cleaned_query.split() suggested_words = [] for word in query_words: suggestions = corrector.suggest(word, limit=1) if len(suggestions) > 0: suggested_words.append(suggestions[0]) spelling_suggestion = ' '.join(suggested_words) return spelling_suggestion def _from_python(self, value): """ Converts Python values to a string for Whoosh. Code courtesy of pysolr. """ if hasattr(value, 'strftime'): if not hasattr(value, 'hour'): value = datetime(value.year, value.month, value.day, 0, 0, 0) elif isinstance(value, bool): if value: value = 'true' else: value = 'false' elif isinstance(value, (list, tuple)): value = u','.join([force_text(v) for v in value]) elif isinstance(value, (six.integer_types, float)): # Leave it alone. pass else: value = force_text(value) return value def _to_python(self, value): """ Converts values from Whoosh to native Python values. A port of the same method in pysolr, as they deal with data the same way. """ if value == 'true': return True elif value == 'false': return False if value and isinstance(value, six.string_types): possible_datetime = DATETIME_REGEX.search(value) if possible_datetime: date_values = possible_datetime.groupdict() for dk, dv in date_values.items(): date_values[dk] = int(dv) return datetime(date_values['year'], date_values['month'], date_values['day'], date_values['hour'], date_values['minute'], date_values['second']) try: # Attempt to use json to load the values. converted_value = json.loads(value) # Try to handle most built-in types. if isinstance(converted_value, (list, tuple, set, dict, six.integer_types, float, complex)): return converted_value except: # If it fails (SyntaxError or its ilk) or we don't trust it, # continue on. pass return value class WhooshSearchQuery(BaseSearchQuery): def _convert_datetime(self, date): if hasattr(date, 'hour'): return force_text(date.strftime('%Y%m%d%H%M%S')) else: return force_text(date.strftime('%Y%m%d000000')) def clean(self, query_fragment): """ Provides a mechanism for sanitizing user input before presenting the value to the backend. Whoosh 1.X differs here in that you can no longer use a backslash to escape reserved characters. Instead, the whole word should be quoted. """ words = query_fragment.split() cleaned_words = [] for word in words: if word in self.backend.RESERVED_WORDS: word = word.replace(word, word.lower()) for char in self.backend.RESERVED_CHARACTERS: if char in word: word = "'%s'" % word break cleaned_words.append(word) return ' '.join(cleaned_words) def build_query_fragment(self, field, filter_type, value): from haystack import connections query_frag = '' is_datetime = False if not hasattr(value, 'input_type_name'): # Handle when we've got a ``ValuesListQuerySet``... if hasattr(value, 'values_list'): value = list(value) if hasattr(value, 'strftime'): is_datetime = True if isinstance(value, six.string_types) and value != ' ': # It's not an ``InputType``. Assume ``Clean``. value = Clean(value) else: value = PythonData(value) # Prepare the query using the InputType. prepared_value = value.prepare(self) if not isinstance(prepared_value, (set, list, tuple)): # Then convert whatever we get back to what pysolr wants if needed. prepared_value = self.backend._from_python(prepared_value) # 'content' is a special reserved word, much like 'pk' in # Django's ORM layer. It indicates 'no special field'. if field == 'content': index_fieldname = '' else: index_fieldname = u'%s:' % connections[self._using].get_unified_index().get_index_fieldname(field) filter_types = { 'content': '%s', 'contains': '*%s*', 'endswith': "*%s", 'startswith': "%s*", 'exact': '%s', 'gt': "{%s to}", 'gte': "[%s to]", 'lt': "{to %s}", 'lte': "[to %s]", 'fuzzy': u'%s~', } if value.post_process is False: query_frag = prepared_value else: if filter_type in ['content', 'contains', 'startswith', 'endswith', 'fuzzy']: if value.input_type_name == 'exact': query_frag = prepared_value else: # Iterate over terms & incorportate the converted form of each into the query. terms = [] if isinstance(prepared_value, six.string_types): possible_values = prepared_value.split(' ') else: if is_datetime is True: prepared_value = self._convert_datetime(prepared_value) possible_values = [prepared_value] for possible_value in possible_values: terms.append(filter_types[filter_type] % self.backend._from_python(possible_value)) if len(terms) == 1: query_frag = terms[0] else: query_frag = u"(%s)" % " AND ".join(terms) elif filter_type == 'in': in_options = [] for possible_value in prepared_value: is_datetime = False if hasattr(possible_value, 'strftime'): is_datetime = True pv = self.backend._from_python(possible_value) if is_datetime is True: pv = self._convert_datetime(pv) if isinstance(pv, six.string_types) and not is_datetime: in_options.append('"%s"' % pv) else: in_options.append('%s' % pv) query_frag = "(%s)" % " OR ".join(in_options) elif filter_type == 'range': start = self.backend._from_python(prepared_value[0]) end = self.backend._from_python(prepared_value[1]) if hasattr(prepared_value[0], 'strftime'): start = self._convert_datetime(start) if hasattr(prepared_value[1], 'strftime'): end = self._convert_datetime(end) query_frag = u"[%s to %s]" % (start, end) elif filter_type == 'exact': if value.input_type_name == 'exact': query_frag = prepared_value else: prepared_value = Exact(prepared_value).prepare(self) query_frag = filter_types[filter_type] % prepared_value else: if is_datetime is True: prepared_value = self._convert_datetime(prepared_value) query_frag = filter_types[filter_type] % prepared_value if len(query_frag) and not isinstance(value, Raw): if not query_frag.startswith('(') and not query_frag.endswith(')'): query_frag = "(%s)" % query_frag return u"%s%s" % (index_fieldname, query_frag) class WhooshEngine(BaseEngine): backend = WhooshSearchBackend query = WhooshSearchQuery
然后,需要在settings.py 下 django-haystack 配置中修改: HAYSTACK_CONNECTIONS
原:
# 全局搜索django-haystack 配置 HAYSTACK_CONNECTIONS = { 'default': { # 设置 haystack 的搜索引擎 'ENGINE': 'haystack.backends.whoosh_backend.WhooshEngine', # 设置索引文件的位置 'PATH': os.path.join(BASE_DIR, 'whoosh_index'), } }
新:
# 全局搜索django-haystack 配置 HAYSTACK_CONNECTIONS = { 'default': { # 设置 haystack 的搜索引擎 'ENGINE': 'news.whoosh_cn_backend.WhooshEngine', # 改 # 设置索引文件的位置 'PATH': os.path.join(BASE_DIR, 'whoosh_index'), } }
5)建立索引的方式
方式1:在项目的根目录下,使用命令:python manage.py rebuild_index 来创建索引
方式2:在settings中做如下配置 ,这样每次进行数据增删改查后系统都能自动创建索引,不需要每次都手动创建:
# settings.py # 配置后, 增删改查操作后都能自动创建索引 HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor'
五、权限管理
1、自定义 django 命令
在需要创建权限管理相关的 APP 下新建 python 包 ,包名称必须命名为:management → 接着在 management 包目录下,再新建 python 包 ,命名同样唯一:commands → 进入 commands 包中,新建 python文件,文件名即为命令名,如初始化分组操作,命名 python 文件名为:initgroup.py ,目录如下所示:
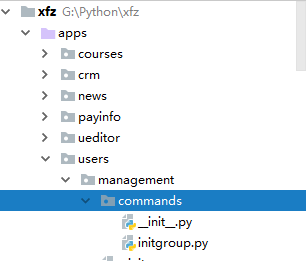
在 initgroup.py 中编写代码,实现执行指令:python manage.py initgroup 时,控制台打印 hello world :
from django.core.management.base import BaseCommand class Command(BaseCommand): """执行python manage.py initgroup命令时,会执行此类""" def handle(self, *args, **options): # 执行initgroup命令时,打印 hello world self.stdout.write(self.style.SUCCESS("hello world"))

2、实现网站分组管理及权限配置
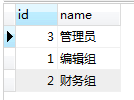
分组示例:编辑组/财务组/管理员/超级管理员
代码实现:
from django.core.management.base import BaseCommand from django.contrib.auth.models import Group, Permission, ContentType from news.models import News, NewsCategory, Comment, Banner from courses.models import Course, CourseCategory, Teacher, CourseOrder class Command(BaseCommand): def handle(self, *args, **options): # 1. 编辑组:管理新闻/管理课程/管理评论/管理轮播图 edit_content_types = { # 获取相关models下指定表的 contenttype ContentType.objects.get_for_model(News), ContentType.objects.get_for_model(NewsCategory), ContentType.objects.get_for_model(Banner), ContentType.objects.get_for_model(Comment), ContentType.objects.get_for_model(Course), ContentType.objects.get_for_model(CourseCategory), ContentType.objects.get_for_model(Teacher), } edit_permissions = Permission.objects.filter(content_type__in=edit_content_types) # 找到相关表的所有权限 editGroup = Group.objects.create(name="编辑组") # 创建组 editGroup.permissions.set(edit_permissions) # 将表权限分配给 编辑组 editGroup.save() self.stdout.write(self.style.SUCCESS("编辑分组完成!")) # 2. 财务组:管理课程订单 finance_content_types = { # 获取相关models下指定表的 contenttype ContentType.objects.get_for_model(CourseOrder), } finance_permissions = Permission.objects.filter(content_type__in=finance_content_types) # 找到相关表的所有权限 financeGroup = Group.objects.create(name="财务组") # 创建组 financeGroup.permissions.set(finance_permissions) # 将表权限分配给 编辑组 financeGroup.save() self.stdout.write(self.style.SUCCESS("财务分组完成!")) # 3. 管理员:包含编辑组 + 财务组 权限 admin_permissions = edit_permissions.union(finance_permissions) adminGroup = Group.objects.create(name="管理员") # 创建组 adminGroup.permissions.set(admin_permissions) # 将表权限分配给 编辑组 adminGroup.save() self.stdout.write(self.style.SUCCESS("管理员分组完成!")) # 4.超级管理员 # is_superuser
执行命令:

数据库中生成分组数据:
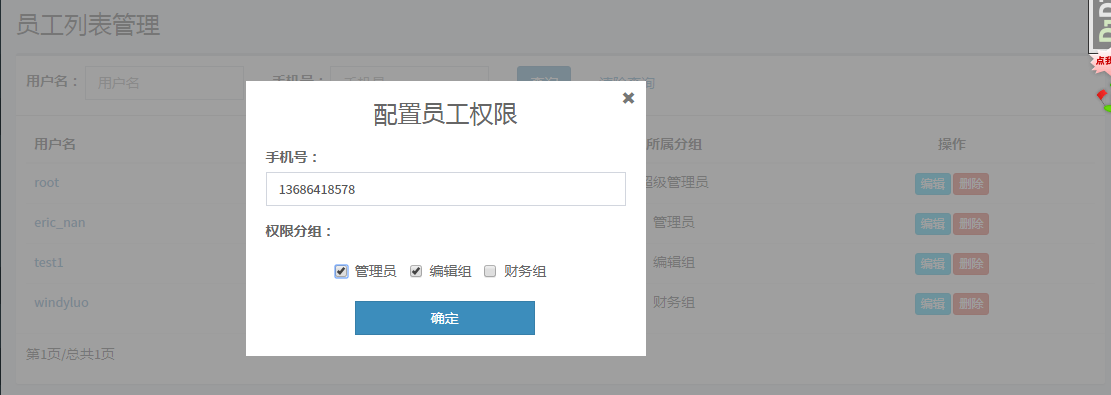
分组完成,实现给用户配置分组权限:
后端代码实现:
@require_POST def edit_staff(request): """配置员工权限""" mobile = request.POST.get("mobile", None) user = UserProfile.objects.filter(mobile=mobile).first() if user.is_staff: group_ids =[] group_info = request.POST.get("groups", None) if group_info: # 从前端获取的权限分组是这样的:1/2/3 ,数字代表的是分组group id group_list = group_info.split("/") for group_id in group_list: if group_id != "": group_ids.append(group_id) if group_ids: groups = Group.objects.filter(id__in=group_ids) user.groups.clear() # 清除旧分组 user.groups.add(*groups) # 添加新分组 user.save() else: user.groups.clear() user.save() return JsonResponse({"status": True, "message": "员工权限配置完成!"}) else: return JsonResponse({"status": True, "message": "该用户不是员工,无法配置权限!"})














 1063
1063











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









