






install.packages("randomForest")#安装R包
library(party)#输入数据
library(randomForest)#引入分析包
output.forest <- randomForest(nativeSpeaker ~ age + shoeSize + score,
data = readingSkills)#创建随机森林
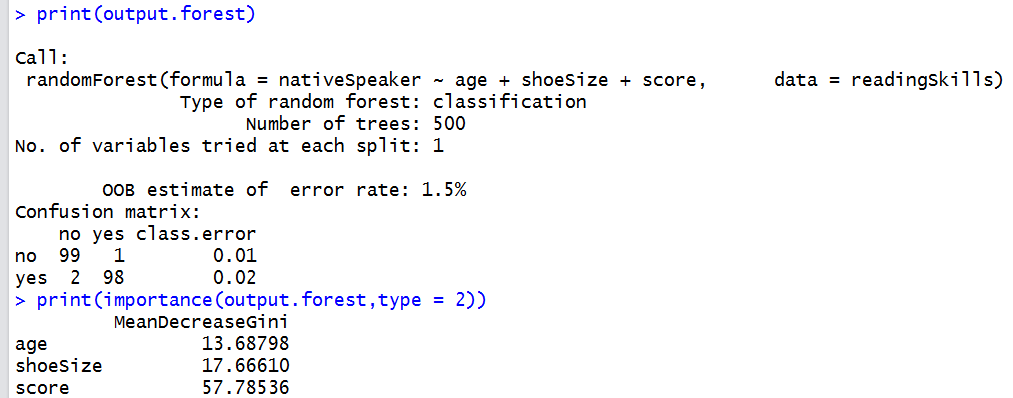
print(output.forest)#查看
print(importance(output.forest,type = 2))#Gini指数
gini指数表示节点的纯度,gini指数越大纯度越低。gini值平均降低量表示所有树的变量分割节点平均减小的不纯度。对于变量重要度衡量,步骤如同前面介绍,将变量数据打乱,gini指数变化的均值作为变量的重要程度度量。
结果如下:
varImpPlot(output.forest)#可视化
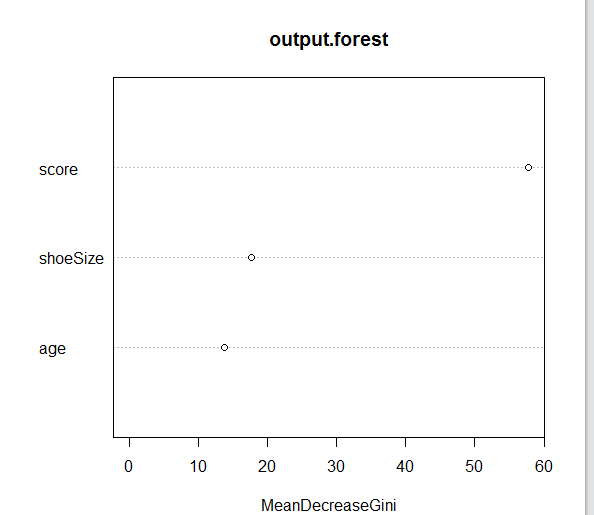
从上面显示的随机森林,我们可以得出结论,鞋码和成绩是决定如果某人是母语者或不是母语的重要因素。 此外,该模型只有1%~2%的误差,这意味着我们可以预测精度为98%。















 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









