






1:导入Lucene相关的jar包

其中:
- lucene-core-3.6.2.jar(核心包)
- lucene-analyzers-3.6.2.jar(分词器)
- lucene-highlighter-3.6.2.jar(高亮)
- lucene-memory-3.6.2.jar(高亮)
- IKAnalyzer2012_u6.jar(中文分词器)
2:lucene原理图
(1)索引库操作原理
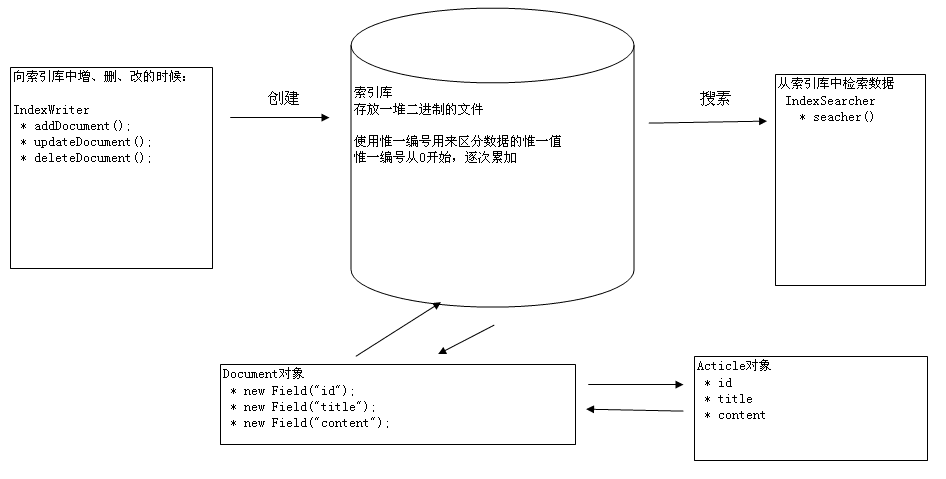
(2)索引库中存放数据原理


-
3:lucene开发原理(数据库与索引库同步)
-

-
数据库与索引库中存放相同的数据,可以使用数据库中存放的ID用来表示和区分同一条数据。
l 数据库中用来存放数据
l 索引库中用来查询、检索
检索库支持查询检索多种方式,
特点:
1:由于是索引查询(通过索引查询数据),检索速度快,搜索的结果更加准确
2:生成文本摘要,摘要截取搜索的文字出现最多的地方
3:显示查询的文字高亮
4:分词查询等
-
4:配置文件
-
(1)导入以下3个配置文件,放置到项目的资源路径下(类路径)
-

-
IKAnalyzer.cfg.xml
-
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext.dic;</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stopword.dic;</entry>
</properties>
以及ext.dic(扩展词库)
- stopword.dic(停用词库)
-
5:索引库基本代码
(1)导入以下3个文件,放置到项目的util包下 
l Configuration.java
public class Configuration {
//索引库的目录位置
private static Directory directory;
//分词器
private static Analyzer analyzer;
static{
try {
/**索引库目录为D盘indexDir*/
directory = FSDirectory.open(new File("D:/indexDir/"));
/**词库分词*/
analyzer = new IKAnalyzer();
} catch (Exception e) {
e.printStackTrace();
}
}
public static Directory getDirectory() {
return directory;
}
public static Analyzer getAnalyzer() {
return analyzer;
}
}
分析:
/**索引库目录为D盘indexDir*/
directory = FSDirectory.open(new File("D:/indexDir/"));
表示指定索引库的位置,在D盘的indexDir文件夹下,索引库存放的数据将采用二进制的方式
/**词库分词*/
analyzer = new IKAnalyzer();
表示分词器,对索引库新增数据和对索引库查询数据,都需要对操作的数据进行分词,将分词后的数据存放,查询的时候也要通过你的条件,分词查询和检索
l FileUploadDocument.java
public class FileUploadDocument {
/**将ElecFileUpload对象转换成Document对象*/
public static Document FileUploadToDocument(ElecFileUpload elecFileUpload){
Document document = new Document();
String seqId = NumericUtils.intToPrefixCoded(elecFileUpload.getSeqId());
//主键ID
document.add(new Field("seqId",seqId,Store.YES,Index.NOT_ANALYZED));
//文件名
document.add(new Field("fileName", elecFileUpload.getFileName(), Store.YES, Index.ANALYZED));
//文件描述
document.add(new Field("comment", elecFileUpload.getComment(), Store.YES, Index.ANALYZED));
//所属单位
document.add(new Field("projId",elecFileUpload.getProjId(),Store.YES,Index.NOT_ANALYZED));
//图纸类别
document.add(new Field("belongTo",elecFileUpload.getBelongTo(),Store.YES,Index.NOT_ANALYZED));
return document;
}
/**将Document对象转换成ElecFileUpload对象*/
public static ElecFileUpload documentToFileUpload(Document document){
ElecFileUpload elecFileUpload = new ElecFileUpload();
Integer seqId = NumericUtils.prefixCodedToInt(document.get("seqId"));
//主键ID
elecFileUpload.setSeqId(seqId);
//文件名
elecFileUpload.setFileName(document.get("fileName"));
//文件描述
elecFileUpload.setComment(document.get("comment"));
//所属单位
elecFileUpload.setProjId(document.get("projId"));
//图纸类别
elecFileUpload.setBelongTo(document.get("belongTo"));
return elecFileUpload;
}
}
-
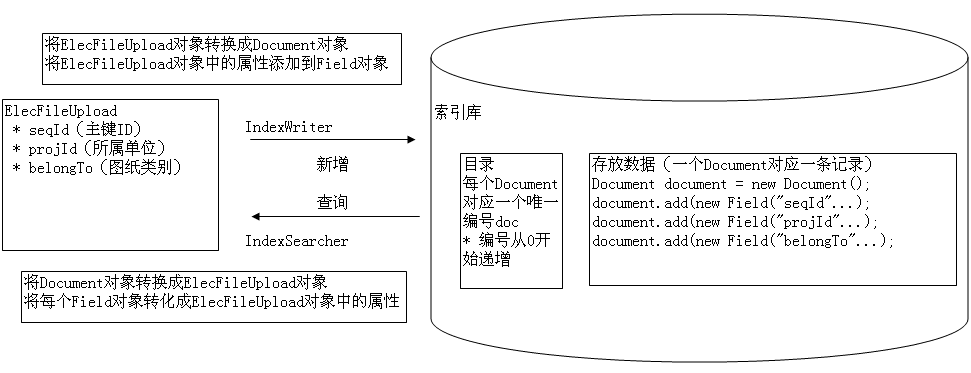
-
这里要注意:索引库中存放的数据要转换成Document对象(每条数据就是一个Document对象),并向Document对象中存放Field对象(每条数据对应的字段,例如主键ID、所属单位、图纸类别、文件名称、备注等),将每个字段中的值都存放到Field对象中
l LuceneUtils.java
public class LuceneUtils {
/**向索引库中新增数据*/
public void saveFileUpload(ElecFileUpload elecFileUpload) {
Document document = FileUploadDocument.FileUploadToDocument(elecFileUpload);
try {
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(Version.LUCENE_36,Configuration.getAnalyzer());
IndexWriter indexWriter = new IndexWriter(Configuration.getDirectory(),indexWriterConfig);
indexWriter.addDocument(document);
indexWriter.close();
} catch (Exception e) {
throw new RuntimeException();
}
}
/**索引库中删除数据*/
public void deleteFileUploadByID(Integer seqId) {
//指定词条的最小单位,相当于id=1
String id = NumericUtils.intToPrefixCoded(seqId);
Term term = new Term("seqId", id);
try {
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(Version.LUCENE_36,Configuration.getAnalyzer());
IndexWriter indexWriter = new IndexWriter(Configuration.getDirectory(),indexWriterConfig);
indexWriter.deleteDocuments(term);
indexWriter.close();
} catch (Exception e) {
e.printStackTrace();
}
}
/**使用搜索条件,从索引库中搜索出对应的结果*/
public List<ElecFileUpload> searchFileUploadByCondition(String queryString,String projId,String belongTo) {
List<ElecFileUpload> list = new ArrayList<ElecFileUpload>();
try {
IndexSearcher indexSearcher = new IndexSearcher(IndexReader.open(Configuration.getDirectory()));
/**使用lucene的多条件查询,即boolean查询,即必须满足3个条件*/
BooleanQuery booleanQuery = new BooleanQuery();
//【按文件名称和描述搜素】搜素的条件
if(StringUtils.isNotBlank(queryString)){
//指定查询条件在文件名称和文件描述、所属单位、图纸类别的字段上进行搜索
QueryParser queryParser = new MultiFieldQueryParser(Version.LUCENE_36,new String[]{"fileName","comment"},Configuration.getAnalyzer());
Query query1 = queryParser.parse(queryString);
booleanQuery.add(query1,Occur.MUST);
}
//【所属单位】搜素的条件
if(StringUtils.isNotBlank(projId)){
Query query2 = new TermQuery(new Term("projId", projId));
booleanQuery.add(query2, Occur.MUST);
}
//【图纸类别】搜素的条件
if(StringUtils.isNotBlank(belongTo)){
Query query3 = new TermQuery(new Term("belongTo", belongTo));
booleanQuery.add(query3, Occur.MUST);
}
//返回前100条数据
TopDocs topDocs = indexSearcher.search(booleanQuery, 100);
//返回结果集
ScoreDoc [] scoreDocs = topDocs.scoreDocs;
/**设置高亮效果 begin*/
Formatter formatter = new SimpleHTMLFormatter("<font color='red'>","</font>");
Scorer scorer = new QueryScorer(booleanQuery);
Highlighter highlighter = new Highlighter(formatter,scorer);
//摘要大小(设置大点,最好比文件名大,因为文件名最好不要截取)
int fragmentSize = 50;
Fragmenter fragmenter = new SimpleFragmenter(fragmentSize);
highlighter.setTextFragmenter(fragmenter);
/**设置高亮效果 end*/
if(scoreDocs!=null && scoreDocs.length>0){
for(int i=0;i<scoreDocs.length;i++){
ScoreDoc scoreDoc = scoreDocs[i];
//使用内部惟一编号,获取对应的数据,编号从0开始
Document document = indexSearcher.doc(scoreDoc.doc);
/**获取高亮效果begin*/
/**返回文件名的高亮效果*/
String fileNameText = highlighter.getBestFragment(Configuration.getAnalyzer(), "fileName", document.get("fileName"));
//没有高亮的效果
if(fileNameText==null){
fileNameText = document.get("fileName");
if(fileNameText!=null && fileNameText.length()>fragmentSize){
fileNameText = fileNameText.substring(0, fragmentSize);
}
}
document.getField("fileName").setValue(fileNameText);
/**返回文件描述的高亮效果*/
String commentText = highlighter.getBestFragment(Configuration.getAnalyzer(), "comment", document.get("comment"));
//没有高亮的效果
if(commentText==null){
commentText = document.get("comment");
if(commentText!=null && commentText.length()>fragmentSize){
commentText = commentText.substring(0, fragmentSize);
}
}
document.getField("comment").setValue(commentText);
/**获取高亮效果end*/
//将Document转换成ElecFileUpload
ElecFileUpload elecFileUpload = FileUploadDocument.documentToFileUpload(document);
list.add(elecFileUpload);
}
}
} catch (Exception e) {
throw new RuntimeException();
}
return list;
}
}
查看索引库中的数据,使用lukeall-3.5.0.jar:
- java -jar lukeall-3.5.0.jar















 99
99











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









