在实际的网络中,总会存在设备出现high CPU的情况,这种情况下,往往会让网络管理员比较着急,因为如果CPU持续high,可能导致设备的性能降低,严重还可能导致设备down掉。
本篇记录,主要记录一下关于high CPU的一些基本知识以及排查的方法。
1、关于high CPU
当设备启动完成后,CPU具有两个不同的功能,其一,是在IOS下运行不同的进程(Process);其二,是CPU从交换硬件中发送/接收报文进行处理。CPU同时执行这两个功能。
不管是IOS Process占用了太多的CPU还是CPU从硬件收到太多的报文,都会导致CPU high,这两者都会相互影响,例如,当CPU忙于处理收到的大量的报文,那么可能导致IOS Process无法访问CPU资源。
在正常情况下,在一些非堆叠的交换机上,CPU有一定的基线利用率,根据设备型号和类型,这个范围可以从5%到40%(设备设计上的差异),如果交换机是堆叠的,那么CPU的至少可以正常运行几个百分点利用率,堆叠中的成员数量会对整体的CPU利用率产生影响。在堆叠交换机中,CPU利用率仅仅在Master交换机上体现。另外,交换机不会报告0%的CPU利用率,因为在后台运行多个IOS进行,每秒都会执行多次。
One of the reasons that different ranges and models within those ranges will differ in the baseline utilization is differences in design. Where the earlier models of the switches with little usage of microcontrollers, the later ones do utilize these more. As more tasks are being offloaded to those microcontrollers there is an increase in communication between the CPU and the microcontrollers. The processes this will be reported under are the HULC led and the Redearth Tx an Rx processes.
通过show processes cpu sorted命令,可以看到CPU在过去5秒,1分钟,5分钟的繁忙情况,也可以看到每个系统进程对CPU占用的百分比。
Switch# show processes cpu sorted
PID Runtime(ms) Invoked uSecs 5Sec 1Min 5Min TTY Process
1 4539 89782 50 0.00% 0.00% 0.00% 0 Chunk Manager
2 1042 1533829 0 0.00% 0.00% 0.00% 0 Load Meter
3 0 1 0 0.00% 0.00% 0.00% 0 DiagCard3/-1
4 14470573 1165502 12415 0.00% 0.13% 0.16% 0 Check heaps
5 7596 212393 35 0.00% 0.00% 0.00% 0 Pool Manager
6 0 2 0 0.00% 0.00% 0.00% 0 Timers
7 0 1 0 0.00% 0.00% 0.00% 0 Image Licensing
8 0 2 0 0.00% 0.00% 0.00% 0 License Client N
9 1442263 25601 56336 0.00% 0.08% 0.02% 0 Licensing Auto U
10 0 1 0 0.00% 0.00% 0.00% 0 Crash writer
11 979720 2315501 423 0.00% 0.00% 0.00% 0 ARP Input
12 0 1 0 0.00% 0.00% 0.00% 0 CEF MIB API
如上输出示例,在最近5秒的CPU利用率有两个百分比(5%/0%)。
5%——告知CPU在最近5秒的繁忙情况,这个是活跃的系统进程CPU利用率的总量,包括了interrupt level的百分比。
0%——体现的是在最近5秒interrupt level的百分比占用情况。interrupt百分比是CPU花在从交换机硬件接收的数据包上的,该百分比总是小于等于总的CPU利用率。
2、识别并判断high CPU
2.1 正常的high CPU
在一些情况下,正常的high CPU不会对网络正常影响,我们可以通过show processes cpu history去查看过去60秒,60分钟,以及72小时的CPU利用情况,你可以看到CPU的利用情况,以及是否存在突发情况。
在一些例子中,CPU飙升可能是一些已知的网络事件,例如执行“write memory”、“A Large L2 Network”拓扑发生改变”、“IP路由表的更新”、“其他IOS命令”等。
- A Large L2 Network”拓扑发生改变:STP的计算,实例越多,活跃的接口越多,越可能出现。
- IP路由表更新:更新的路由表越大,周期越频繁,接收更新的路由协议进程数量,存在任何route map或者filters等情况都可能导致。
- IOS命令:show tech、write memory、show-running configuration、debug等命令
- 其他事件:
频繁或大量的IGMP请求,CPU会处理IGMP消息;
大量的IP SLA监控会话,CPU会生成ICMP或者traceroute数据包;
SNMP轮询活动,特别是MIB walk,Cisco IOS SNMP engine执行SNMP请求;
大量同时发出的DHCP请求;
ARP广播风暴;
Ethernet广播风暴。
2.2 通过high CPU造成的症状
high CPU会影响系统进程正常运行,当系统进程不执行时,交换机或直接连接的网络设备会反映对网络问题,对于L2网络,可能会发生STP从新收敛,对于L3网络,路由拓扑可能发生变化。
当交换机CPU high时可能出现的已知症状:
2.2.1、STP topo change:当二层网络设备未在RP上及时收到STP BPDU时,它会将Root Switch的二层路径视为down,并且交换机会尝试查找新路径,那么STP将会重新收敛。
2.2.2、routing topo change:例如BGP路由震荡或OSPF路由震荡。
2.2.3、EtherChannel链路反弹:当EtherChannel另一端的网络设备没有收到维护EtherChannel链路所需的协议数据包时,这可能导致链路断开。
2.2.4、交换机无法响应正常的管理请求:
- ICMP ping 请求
- SNMP timeout
- Telnet或SSH会话很慢或不能建立
- UDLD flapping
- IP SLAs failures
- DHCP或802.1x failures
- 丢包或者延迟增加
- HSRP flapping
2.3 确定中断百分比
CPU利用率历史记录仅显示随时间变化的总CPU利用率。它不显示中断所花费的CPU时间。了解中断所花费的时间对于确定CPU利用率的原因至关重要。 CPU利用率历史记录显示CPU何时持续接收网络数据包,但未显示原因。
输入Cisco IOS设备输入show processes cpu sorted 5sec 命令以显示当前CPU利用率以及哪些IOS进程占用的CPU时间最多。正常情况下,中断百分比大于0%且小于5%。中断百分比可以在5%到10%之间。应调查超过10%的中断百分比。
3、判断根本原因
一个输出示例,可以通过交换机用于管理数据包的系统进程识别充斥CPU的网络数据包的类型,当CPU interrupt百分比相对较高时,输入show processes cpu sorted 5sec命令来确认最活跃的进程,
输出首先会列出最为活跃的进程。
Switch#
show processes cpu sorted 5sec
CPU utilization for five seconds: 64%/19%; one minute: 65%; five minutes: 70%
PID Runtime(ms) Invoked uSecs 5Sec 1Min 5Min TTY Process
186 19472027 64796535 300 35.14% 37.50% 36.05% 0 IP Input
192 24538871 82738840 296 1.11% 0.71% 0.82% 0 Spanning Tree
458 5514 492 11207 0.63% 0.15% 0.63% 2 Virtual Exec
61 3872439 169098902 22 0.63% 0.63% 0.41% 0 RedEarth Tx Mana
99 10237319 12680120 807 0.47% 0.66% 0.59% 0 hpm counter proc
131 4232087 224923936 18 0.31% 0.50% 1.74% 0 Hulc LED Process
152 2032186 7964290 255 0.31% 0.21% 0.25% 0 PI MATM Aging Pr
140 22911628 12784253 1792 0.31% 0.23% 0.26% 0 HRPC qos request
250 27807274 62859001 442 0.31% 0.34% 0.34% 0 RIP Router
表1列出了一些常见的系统进程和相关的数据包类型。 如果列出的系统进程之一是CPU中最活跃的进程,则相应类型的网络数据包很可能充斥CPU。
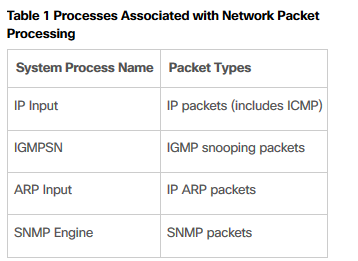
在三层交换机上,当IP route未知时,交换机硬件将会把IP数据包发送到CPU进行IP routing,发送的数据包会在interrupt level处理,并且会导致CPU繁忙。 如果命令输出中显示的中断百分比很高,但是最活跃的进程不是上表中所示的那些,或者没有任何进程看起来足够有效证明CPU利用率,那么高CPU利用率很可能是由于被发送到CPU的数据包引起的,示例输出中显示。
Switch# show processes cpu sorted 5sec
CPU utilization for five seconds: 53%/
28%; one minute: 48%; five minutes: 45%
PID Runtime(ms) Invoked uSecs 5Sec 1Min 5Min TTY Process
78 461805 220334990 2 11.82% 11.53% 10.37% 0 HLFM address lea
309 99769798 1821129 54784 5.27% 1.53% 1.39% 0 RIP Timers
192 19448090 72206697 269 1.11% 0.87% 0.81% 0 Spanning Tree
250 25992246 58973371 440 0.63% 0.27% 0.29% 0 RIP Router
99 6853074 11856895 577 0.31% 0.46% 0.44% 0 hpm counter proc
131 3184794 210112491 15 0.31% 0.13% 0.12% 0 Hulc LED Process
140 20821662 11950171 1742 0.31% 0.28% 0.26% 0 HRPC qos request
139 3166446 1498429 2113 0.15% 0.11% 0.11% 0 HQM Stack Proces
67 2809714 11642483 241 0.15% 0.03% 0.00% 0 hrpc <- response
223 449344 16515401 27 0.15% 0.03% 0.00% 0 Marvell wk-a Pow
10 0 1 0 0.00% 0.00% 0.00% 0 Crash writer
11 227226 666257 341 0.00% 0.00% 0.00% 0 ARP Input
表2列出了CPU忙于处理被发送到CPU的数据包时最活跃的系统进程,punted packets的CPU进程和列出的进程无关。

监视CPU接收队列的数据包计数
如果交换机被特定数据包类型泛洪,则硬件会将该数据包类型放入适当的CPU队列并对其进行计数。 输入show controllers cpu-interface 命令以查看每个队列的数据包计数。
Switch # show controllers cpu-interface
ASIC Rxbiterr Rxunder Fwdctfix Txbuflos Rxbufloc Rxbufdrain
-------------------------------------------------------------------------
cpu-queue-frames retrieved dropped invalid hol-block stray
----------------- ---------- ---------- ---------- ---------- ----------
routing protocol 3949 0 0 0 0
remote console 58 0 0 0 0
igmp snooping 3567 0 0 0 0
cpu heartbeat 322409 0 0 0 0
交换机还会计算由于拥塞而丢弃的CPU-bound数据包。 每个CPU接收队列都具有最大数据包计数。 当达到接收队列最大值时,交换机硬件会丢弃发往拥塞队列的数据包。 交换机为每个队列计算丢弃的数据包。 特定CPU队列的丢弃计数增加意味着该队列的使用率很高。
输入show platform port-asic stats drop 命令以查看CPU接收队列丢弃计数并识别丢弃数据包的队列。 此命令没有show controllers cpu-interface命令那么有用,因为输出显示接收队列的数字而不是名称,并且它仅显示丢弃。 由于交换机硬件将CPU接收队列丢弃的数据包视为发送给管理程序,因此丢弃的数据包在命令输出中称为Supervisor TxQueue Drop Statistics。
Switch #
show platform port-asic stats drop
Port-asic Port Drop Statistics - Summary
========================================
RxQueue Drop Statistics Slice0
RxQueue 0 Drop Stats Slice0: 0
RxQueue 1 Drop Stats Slice0: 0
RxQueue 2 Drop Stats Slice0: 0
RxQueue 3 Drop Stats Slice0: 0
RxQueue Drop Statistics Slice1
RxQueue 0 Drop Stats Slice1: 0
RxQueue 1 Drop Stats Slice1: 0
RxQueue 2 Drop Stats Slice1: 0
RxQueue 3 Drop Stats Slice1: 0
Port 27 TxQueue Drop Stats: 0
Supervisor TxQueue Drop Statistics
Supervisor TxQueue Drop Statistics的此输出中的队列号与show controllers cpu-interface命令输出中的队列名称的顺序相同。 例如,此输出中的队列0对应于前一输出中的rpc;。 队列15对应于cpu heartbeat,依此类推。
统计信息不会重置。 多次输入命令以查看活动队列丢弃。 命令输出还显示其他丢弃统计信息,其中一些在示例中被截断。
其他辅助命令:
A、您还可以使用show platform ip unicast statistics 来显示有关已发送数据包的相同信息。 发送的IP数据包计为CPUAdj,在此示例中以粗体显示。
Switch#
show platform ip unicast statistics
HWFwdLoc:0 HWFwdSec:0 UnRes:0 UnSup:0 NoAdj:0
EncapFail:0
CPUAdj:1344291253 Null:0 Drop:0
HWFwdLoc:0 HWFwdSec:0 UnRes:0 UnSup:0 NoAdj:0
EncapFail:0 CPUAdj:1344291253 Null:0 Drop:0
这些统计信息每2到3秒更新一次。 多次输入命令以查看CPUAdj计数的变化。 当CPUAdj计数快速递增时,许多IP数据包将被转发到CPU进行IP路由。
B、在第3层交换机上,硬件使用TCAM来容纳IP路由数据库。 用于第3层路由信息的TCAM空间是有限的。 当此空间已满时,Cisco IOS学习的新路由无法编程到TCAM中。 如果交换机硬件接收的IP数据包具有不在TCAM中的目标IP地址,则硬件将IP数据包发送到CPU。
Switch# show platform tcam utilization
CAM Utilization for ASIC# 0 Max Used
Masks/Values Masks/values
Unicast mac addresses: 6364/6364 31/31
IPv4 IGMP groups + multicast routes: 1120/1120 1/1
IPv4 unicast directly-connected routes: 6144/6144 4/4
IPv4 unicast indirectly-connected routes: 2048/2048 2047/2047
IPv4 policy based routing aces: 452/452 12/12
IPv4 qos aces: 512/512 21/21
IPv4 security aces: 964/964 30/30
Note: Allocation of TCAM entries per feature uses
a complex algorithm. The above information is meant
to provide an abstract view of the current TCAM utilization
Cisco IOS从路由协议(例如BGP,RIP,OSPF,EIGRP和IS-IS)以及静态配置的路由中学习路由。 您可以输入show platform ip unicast counts 命令,以查看有多少这些路由未正确编程到TCAM中。
Switch# show platform ip unicast counts
# of HL3U covering-fibs 0
# of HL3U fibs with adj failures 0
Fibs of Prefix length 0, with TCAM fails: 0
Fibs of Prefix length 1, with TCAM fails: 0
Fibs of Prefix length 2, with TCAM fails: 0
Fibs of Prefix length 3, with TCAM fails: 0
Fibs of Prefix length 4, with TCAM fails: 0
Fibs of Prefix length 5, with TCAM fails: 0
Fibs of Prefix length 6, with TCAM fails: 0
Fibs of Prefix length 7, with TCAM fails: 0
Fibs of Prefix length 8, with TCAM fails: 0
Fibs of Prefix length 9, with TCAM fails: 0
Fibs of Prefix length 10, with TCAM fails: 0
Fibs of Prefix length 11, with TCAM fails: 0
Fibs of Prefix length 12, with TCAM fails: 0
Fibs of Prefix length 13, with TCAM fails: 0
Fibs of Prefix length 14, with TCAM fails: 0
Fibs of Prefix length 15, with TCAM fails: 0
Fibs of Prefix length 16, with TCAM fails: 0
Fibs of Prefix length 17, with TCAM fails: 0
Fibs of Prefix length 18, with TCAM fails: 0
Fibs of Prefix length 19, with TCAM fails: 0
Fibs of Prefix length 20, with TCAM fails: 0
Fibs of Prefix length 21, with TCAM fails: 0
Fibs of Prefix length 22, with TCAM fails: 0
Fibs of Prefix length 23, with TCAM fails: 0
Fibs of Prefix length 24, with TCAM fails: 0
Fibs of Prefix length 25, with TCAM fails: 0
Fibs of Prefix length 26, with TCAM fails: 0
Fibs of Prefix length 27, with TCAM fails: 0
Fibs of Prefix length 28, with TCAM fails: 0
Fibs of Prefix length 29, with TCAM fails: 0
Fibs of Prefix length 30, with TCAM fails: 0
Fibs of Prefix length 31, with TCAM fails: 0
Fibs of Prefix length 32, with TCAM fails: 693
Fibs of Prefix length 33, with TCAM fails: 0
要查看每个路由协议使用的路由条目数,请输入show ip route summary 命令。
Switch# show ip route summary
IP routing table name is Default-IP-Routing-Table(0)
IP routing table maximum-paths is 32
Route Source Networks Subnets Overhead Memory (bytes)
Total 6 2390 153280 365212
参考:https://www.cisco.com/c/en/us/td/docs/switches/lan/catalyst3750/software/troubleshooting/cpu_util.html#pgfId-999591






















 178
178











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









