






最近开始跟随《子雨大数据之Spark入门教程(Python版)》 学习大数据方面的知识。
这里是网页教程的链接:
http://dblab.xmu.edu.cn/blog/1709-2/
在学习中遇到的一些问题,将会在这里进行总结,并贴上我的解决方法。
1、Spark独立应用程序编程时报错:
按照教程所写的配置好环境之后,运行第一个spark 程序时报错显示:
1 python3 ~/test.py 2 WARNING: An illegal reflective access operation has occurred 3 WARNING: Illegal reflective access by org.apache.hadoop.security.authentication.util.KerberosUtil (file:/usr/local/hadoop/share/hadoop/common/lib/hadoop-auth-2.9.1.jar) to method sun.security.krb5.Config.getInstance() 4 WARNING: Please consider reporting this to the maintainers of org.apache.hadoop.security.authentication.util.KerberosUtil 5 WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations 6 WARNING: All illegal access operations will be denied in a future release 7 2018-09-11 19:54:12 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 8 Setting default log level to "WARN". 9 To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). 10 Traceback (most recent call last): 11 File "/home/hadoop/test.py", line 6, in <module> 12 numAs = logData.filter(lambda line: 'a' in line).count() 13 File "/usr/local/spark/python/pyspark/rdd.py", line 1073, in count 14 return self.mapPartitions(lambda i: [sum(1 for _ in i)]).sum() 15 File "/usr/local/spark/python/pyspark/rdd.py", line 1064, in sum 16 return self.mapPartitions(lambda x: [sum(x)]).fold(0, operator.add) 17 File "/usr/local/spark/python/pyspark/rdd.py", line 935, in fold 18 vals = self.mapPartitions(func).collect() 19 File "/usr/local/spark/python/pyspark/rdd.py", line 834, in collect 20 sock_info = self.ctx._jvm.PythonRDD.collectAndServe(self._jrdd.rdd()) 21 File "/usr/local/spark/python/lib/py4j-0.10.7-src.zip/py4j/java_gateway.py", line 1257, in __call__ 22 File "/usr/local/spark/python/lib/py4j-0.10.7-src.zip/py4j/protocol.py", line 328, in get_return_value 23 py4j.protocol.Py4JJavaError: An error occurred while calling z:org.apache.spark.api.python.PythonRDD.collectAndServe. 24 : java.lang.IllegalArgumentException 25 at org.apache.xbean.asm5.ClassReader.<init>(Unknown Source) 26 at org.apache.xbean.asm5.ClassReader.<init>(Unknown Source) 27 at org.apache.xbean.asm5.ClassReader.<init>(Unknown Source) 28 at org.apache.spark.util.ClosureCleaner$.getClassReader(ClosureCleaner.scala:46) 29 at org.apache.spark.util.FieldAccessFinder$$anon$3$$anonfun$visitMethodInsn$2.apply(ClosureCleaner.scala:449) 30 at org.apache.spark.util.FieldAccessFinder$$anon$3$$anonfun$visitMethodInsn$2.apply(ClosureCleaner.scala:432) 31 at scala.collection.TraversableLike$WithFilter$$anonfun$foreach$1.apply(TraversableLike.scala:733) 32 at scala.collection.mutable.HashMap$$anon$1$$anonfun$foreach$2.apply(HashMap.scala:103) 33 at scala.collection.mutable.HashMap$$anon$1$$anonfun$foreach$2.apply(HashMap.scala:103) 34 at scala.collection.mutable.HashTable$class.foreachEntry(HashTable.scala:230) 35 at scala.collection.mutable.HashMap.foreachEntry(HashMap.scala:40) 36 at scala.collection.mutable.HashMap$$anon$1.foreach(HashMap.scala:103) 37 at scala.collection.TraversableLike$WithFilter.foreach(TraversableLike.scala:732) 38 at org.apache.spark.util.FieldAccessFinder$$anon$3.visitMethodInsn(ClosureCleaner.scala:432) 39 at org.apache.xbean.asm5.ClassReader.a(Unknown Source) 40 at org.apache.xbean.asm5.ClassReader.b(Unknown Source) 41 at org.apache.xbean.asm5.ClassReader.accept(Unknown Source) 42 at org.apache.xbean.asm5.ClassReader.accept(Unknown Source) 43 at org.apache.spark.util.ClosureCleaner$$anonfun$org$apache$spark$util$ClosureCleaner$$clean$14.apply(ClosureCleaner.scala:262) 44 at org.apache.spark.util.ClosureCleaner$$anonfun$org$apache$spark$util$ClosureCleaner$$clean$14.apply(ClosureCleaner.scala:261) 45 at scala.collection.immutable.List.foreach(List.scala:381) 46 at org.apache.spark.util.ClosureCleaner$.org$apache$spark$util$ClosureCleaner$$clean(ClosureCleaner.scala:261) 47 at org.apache.spark.util.ClosureCleaner$.clean(ClosureCleaner.scala:159) 48 at org.apache.spark.SparkContext.clean(SparkContext.scala:2299) 49 at org.apache.spark.SparkContext.runJob(SparkContext.scala:2073) 50 at org.apache.spark.SparkContext.runJob(SparkContext.scala:2099) 51 at org.apache.spark.rdd.RDD$$anonfun$collect$1.apply(RDD.scala:939) 52 at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151) 53 at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112) 54 at org.apache.spark.rdd.RDD.withScope(RDD.scala:363) 55 at org.apache.spark.rdd.RDD.collect(RDD.scala:938) 56 at org.apache.spark.api.python.PythonRDD$.collectAndServe(PythonRDD.scala:162) 57 at org.apache.spark.api.python.PythonRDD.collectAndServe(PythonRDD.scala) 58 at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method) 59 at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) 60 at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) 61 at java.base/java.lang.reflect.Method.invoke(Method.java:564) 62 at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244) 63 at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357) 64 at py4j.Gateway.invoke(Gateway.java:282) 65 at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132) 66 at py4j.commands.CallCommand.execute(CallCommand.java:79) 67 at py4j.GatewayConnection.run(GatewayConnection.java:238) 68 at java.base/java.lang.Thread.run(Thread.java:844)
有人说是JAVA版本的问题。
google找了很久之后发现在Stack Overflow 中有人遇到了相同的问题。
首先移除原有Java 我的设备默认安装的是10 版本
sudo apt-get purge openjdk-\* icedtea-\* icedtea6-\*
安装java-1.8.0-openjdk-amd64
sudo apt install openjdk-8-jre-headless
之后要修改当前用户的环境变量vim ~/.bashrc
把JAVA_HOME 的路径修改为:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64
之后再运行spark脚本,没有报错。问题解决。
关于安装多版本JAVA ,和多版本java的切换 可以查看这篇文章。
https://ywnz.com/linuxjc/2948.html
2、安装集群环境hadoop,ubuntu1804作为master节点,两台centos7.5 系统作为从节点。三台设备都添加了hadoop用户。
所有的操作都是使用hadoop用户进行的。
最好保证用于hadoop集群的所有机器都使用相同版本的hadoop 和java。
为了保证java版本的统一,直接从网上下载了
jdk-8u181-linux-x64.tar.gz
这个版本的java 放到三台设备中。解压到/usr/lib/jvm/ 目录下。
su hadoop
vim ~/.bashrc
在~/.bashrc 文件中添加环境变量
export HADOOP_HOME=/usr/local/hadoop export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_181 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$JAVA_HOME/bin
要改成实际使用的文件路径、和java版本。这样就可以直接使用hadoop和java的相关命令了。
输入命令:
source ~/.bashrc
使环境变量立即生效。
如果之前执行过hadoop程序,需要先删除之前的文件。
sudo rm -r ./hadoop/tmp # 删除主从节点的 Hadoop 临时文件(注意这会删除 HDFS 中原有的所有数据,如果原有的数据很重要请不要这样做) sudo rm -r ./hadoop/logs/*
在主节点执行
hdfs namenode -format # 首次运行需要执行初始化,之后不需要
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver
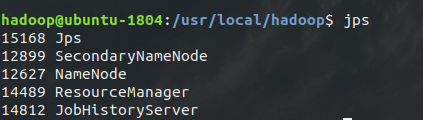
通过命令 jps 可以查看各个节点所启动的进程。正确的话,在 Master 节点上可以看到 NameNode、ResourceManager、SecondrryNameNode、JobHistoryServer 进程,如下图所示:
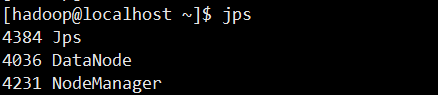
在 Slave 节点可以看到 DataNode 和 NodeManager 进程,如下图所示:
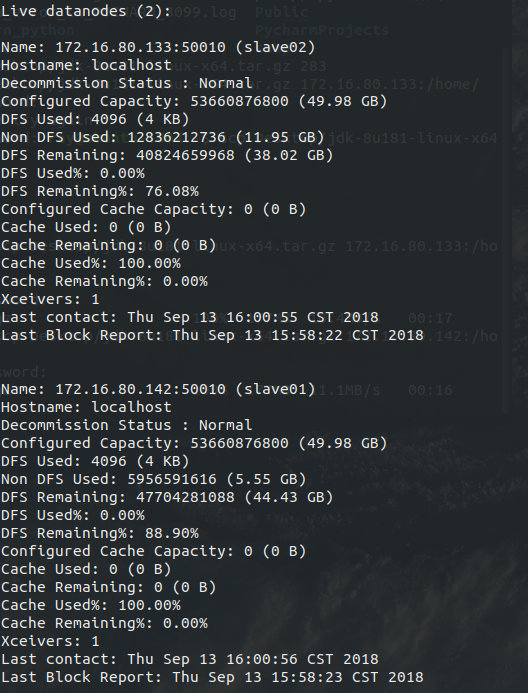
缺少任一进程都表示出错。另外还需要在 Master 节点上通过命令 hdfs dfsadmin -report 查看 DataNode 是否正常启动,如果 Live datanodes 不为 0 ,则说明集群启动成功。
在进行hdfs文件操作时报错:
hadoop@ubuntu-1804:/usr/local/hadoop$ hdfs dfs -mkdir -p /user/hadoop
mkdir: Cannot create directory /user/hadoop. Name node is in safe mode.
这是由于HDFS处于安全模式下。
安全模式是HDFS所处的一种特殊状态,在这种状态下,文件系统只接受读数据请求,而不接受删除、修改等变更请求。在NameNode主节点启动时,HDFS首先进入安全模式,DataNode在启动的时候会向namenode汇报可用的block等状态,当整个系统达到安全标准时,HDFS自动离开安全模式。如果HDFS出于安全模式下,则文件block不能进行任何的副本复制操作,因此达到最小的副本数量要求是基于datanode启动时的状态来判定的,启动时不会再做任何复制(从而达到最小副本数量要求)
https://blog.csdn.net/yh_zeng2/article/details/53144304
https://blog.csdn.net/bingduanlbd/article/details/51900512
输入命令退出安全模式
hdfs dfsadmin -safemode leave
再次执行
hdfs dfs -mkdir -p /user/hadoop
没有报错。
启动pyspark 并连接mysql数据库,在启动时指定使用jar包
pyspark --jars /usr/local/spark/jars/mysql-connector-java-8.0.12/mysql-connector-java-8.0.12.jar --driver-class-path /usr/local/spark/jars/mysql-connector-java-8.0.12/mysql-connector-java-8.0.12.jar
启动kafka consumer:
执行:
./bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic wordsendertest --from-beginning
报错提示:
zookeeper is not a recognized option
修改命令为:
./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic wordsendertest --from-beginning














 2866
2866











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









