






摘要
目前检测的准确率受物体视频中变化的影响,如运动模糊,镜头失焦等。现有工作是想要在框的级别上寻找时序信息,但这样的方法通常不能端到端训练。我们提出了flow-guided feature aggregation,一个用于视频物体检测的端到端学习框架。在特征级别上利用时序信息,通过相邻帧的运动路径提高每帧的特征,从而提高检测的准确率。
简介
特征提取网络提取出每帧的feature maps。为了enhance被处理帧的特征,用一个光流网络(flownet)预测相邻帧和该帧之间的motions。从邻近帧得到的feature maps 被光流 warped to the reference frame。The warped feature maps以及its own feature maps在一个自适应的加权网络中聚合。聚合后的feature maps are fed to 检测网络得到该帧最后的检测结果。其中,所有的特征提取模型都是trained end-to-end。
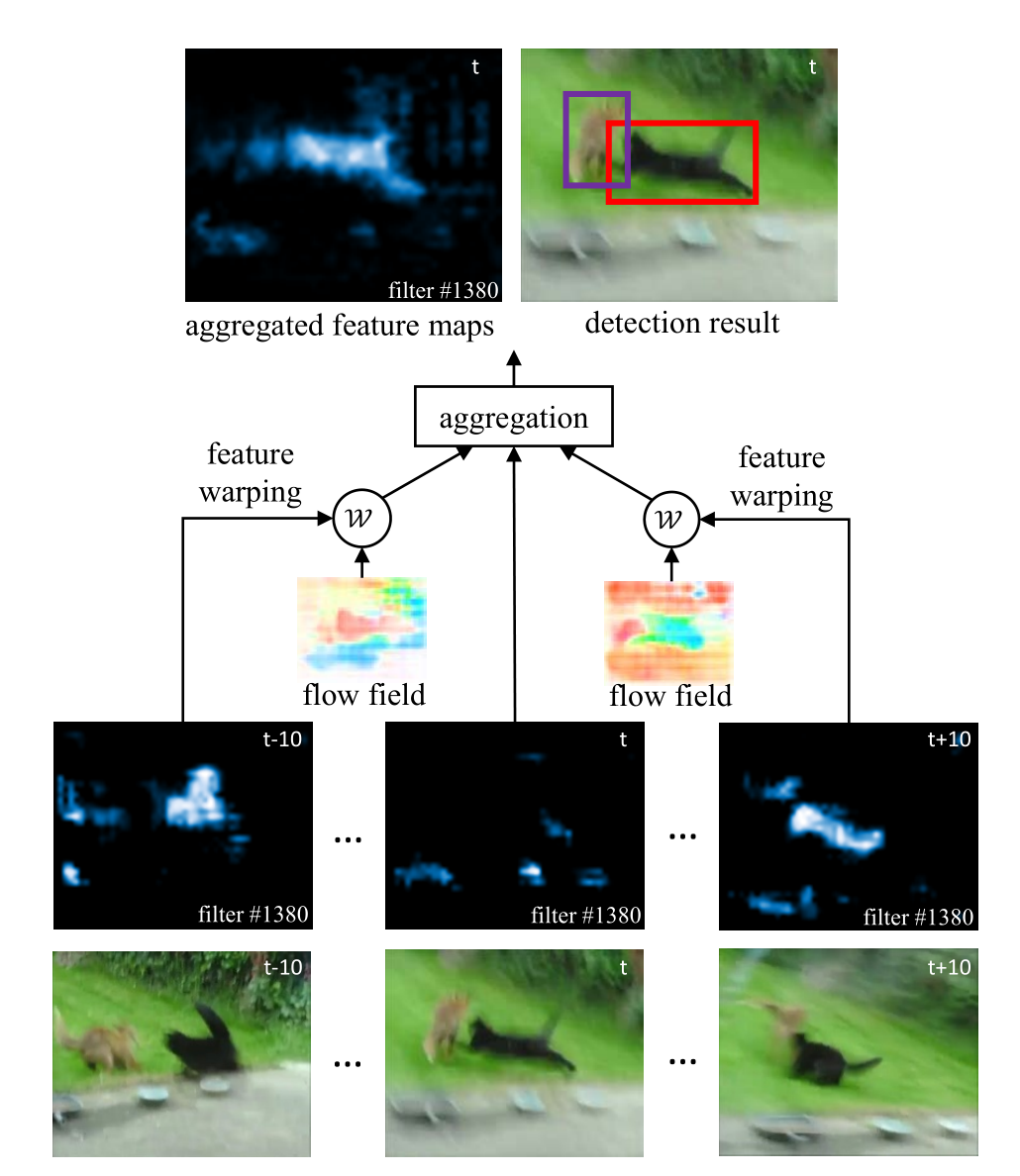
框架的主要思想如上图。最后一层为原图,可以发现第t帧经过光流处理的特征并不明显,而第t-10帧及t+10帧较明显,于是用motion-guided spatial warping预测帧之间的motion。得到warping后的feature maps,将这些特征融合。将融合后的feature map fed to detection network得到最后的检测结果。
由上文可知,框架需要两个主要模型,一是motion-guided spatial warping, 另一个是feature融合。
框架介绍
1. flow-guided warping
对于相邻两帧,首先用flownet得到 a flow field(Mi->j = F(Ii,Ij))。之后warping得到的初始化feature maps,得到flow-guided warp(fj->i = W(fj, Mi->j))。
2. feature aggregation
如何求解融合的weights?首先在不同的空间位置用不同的weights,让所有的特征通道用相同的空间weights。得到的weights记作wj->i。每个位置的wj->i(p)都被normalized,即相邻2k+1帧该点的weights之和为1。
3. adaptive weight
adaptive weight表示相邻2K帧对当前帧影响的程度。if fj->i(p) is close to fi(p), 则将被分配一个较大的weight,相反。用余弦相似度来测量两者之间close的程度。
除此之外,不直接用融合得到的特征,而是用一个tiny fcn处理 fi 和 fj->i,用于计算embedding features。
4. 算法流程
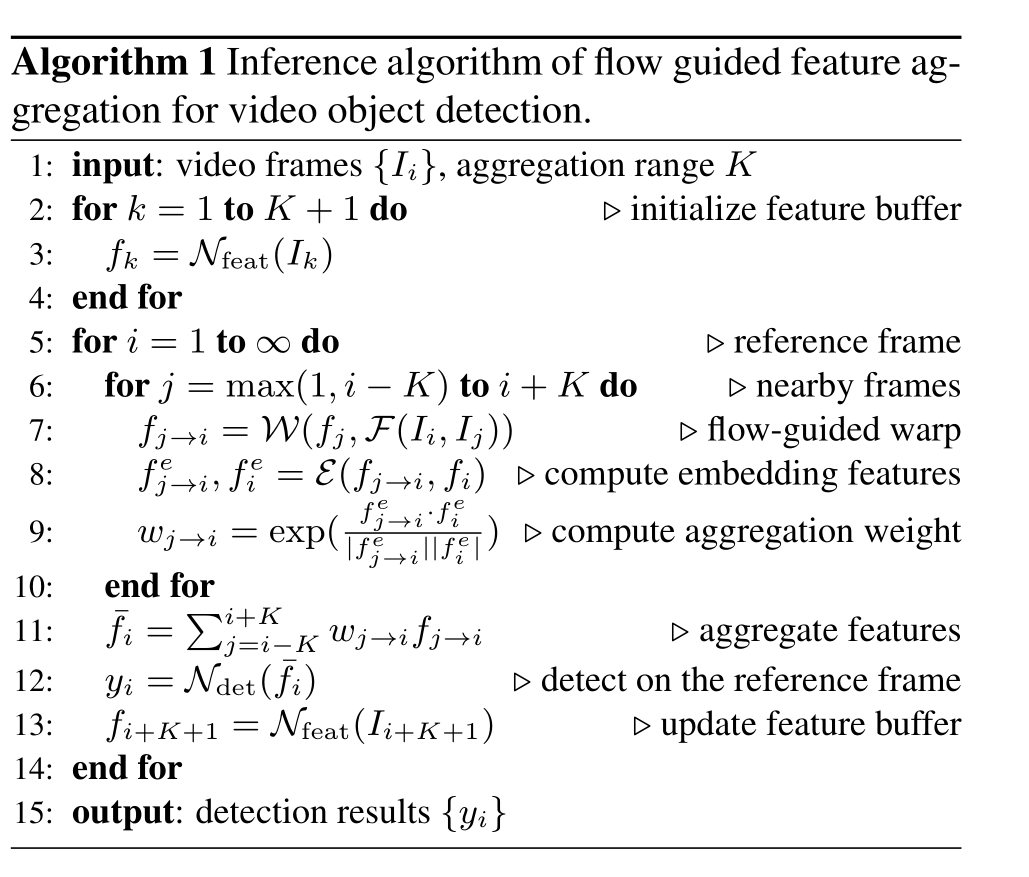
上图对算法流程介绍的很详细,就不再一一解释了。
实验
光流用的flownet, feature network实验了resnet-50, resnet-101,tiny fcn只有三层,检测网络用的R-FCN。
论文中对不同运动速度及不同网络不同条件下的实验结果做了详细介绍。

福利:代码这个月已经在github上开源 : https://github.com/msracver/Flow-Guided-Feature-Aggregation
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









