







一、一条SQL执行过程
先看看一条查询SQL
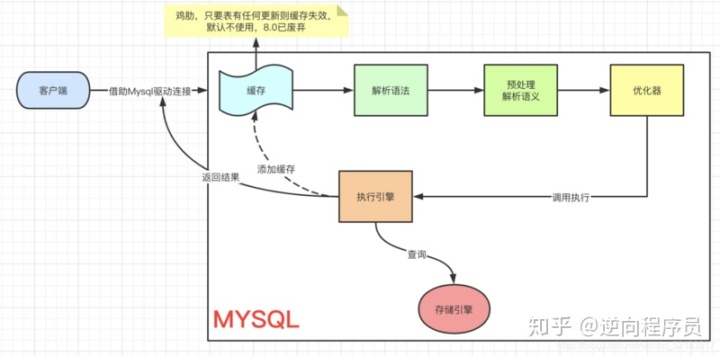
(这里提供一下官方对各存储引擎的文档说明 Mysql存储引擎)
一条 update SQL执行
update的执行 从客户端 => ··· => 执行引擎 是一样的流程,都要先查到这条数据,然后再去更新。要想理解 UPDATE 流程我们先来看看,Innodb的架构模型。
Innodb 架构上一张 MYSQL 官方InnoDB架构图:
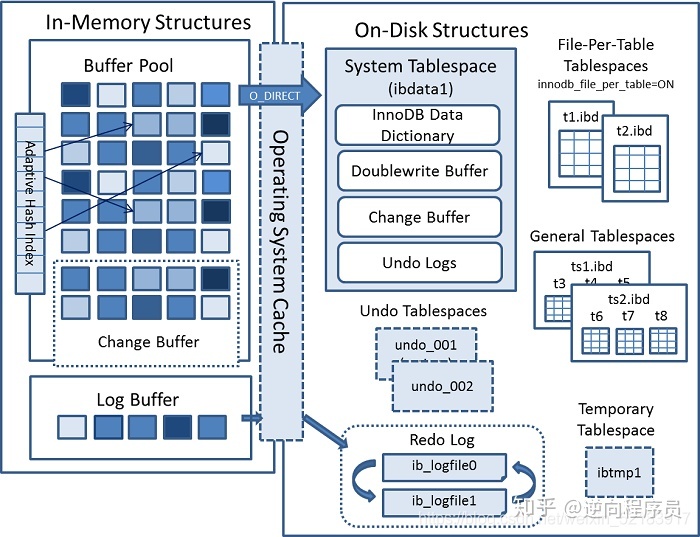
内部模块
连接器(JDBC、ODBC等) =>
[MYSQL 内部
[Connection Pool] (授权、线程复用、连接限制、内存检测等)
=>
[SQL Interface] (DML、DDL、Views等) [Parser] (Query Translation、Object privilege) [Optimizer] (Access Paths、 统计分析) [Caches & Buffers]
=>
[Pluggable Storage Engines]
=> [File]
二、内存结构
这里有个关键点,当我们去查询数据时候会先 拿着我们当前查询的 page 去 buffer pool 中查询 当前page是否在缓冲池中。如果在,则直接获取。
而如果是update操作时,则会直接修改 Buffer中的值。这个时候,buffer pool中的数据就和我们磁盘中实际存储的数据不一致了,称为脏页。每隔一段时间,Innodb存储引擎就会把脏页数据刷入磁盘。一般来说当更新一条数据,我们需要将数据给读取到buffer中修改,然后写回磁盘,完成一次 落盘IO 操作。
为了提高update的操作性能,Mysql在内存中做了优化,可以看到,在架构图的缓冲池中有一块区域叫做:change buffer。顾名思义,给change后的数据,做buffer的,当更新一个没有 unique index 的数据时,直接将修改的数据放到 change buffer,然后通过 merge 操作完成更新,从而减少了那一次 落盘的IO 操作。
- 我们上面说的有个条件:没有唯一索引的数据更新时,为什么必须要没有唯一索引的数据更新时才能直接放入changebuffer呢?如果是有唯一约束的字段,我们在更新数据后,可能更新的数据和已经存在的数据有重复,所以只能从磁盘中把所有数据读出来比对才能确定唯一性。
- 所以当我们的数据是 写多读少 的时候,就可以通过 增加 innodb_change_buffer_max_size 来调整 change
buffer在buffer pool 中所占的比例,默认25(即:25%)
问题又来了,merge是如何运作的有四种情况:
- 有其他访问,访问到了当前页的数据,就会合并到磁盘
- 后台线程定时merge
- 系统正常shut down之前,merge一次
- redo log写满的时候,merge到磁盘
学习资料视频免费获取,学习直通车。

首先恭喜您,能够认真的阅读到这里,如果对部分理解不太明白,建议先将文章收藏起来,然后对不清楚的知识点进行查阅,然后在进行阅读,相应你会有更深的认知。如果您喜欢这篇文章,就点个赞或者【关注我】吧!!















 942
942











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









