






主要:
数据操作语言DML
数据查询语言DQL


数据操作语言DML
DML: Data Mutipulation Language
插入数据(增)
一般插入数据形式
1)形式1: insert [into] 表名 [(字段名1,字段名2,....)] values(值表达式1, 值表达式2,.......),(.....),...;
以"行"为单位进行插入,可以一次插入多行数据,使用逗号分隔。
值列表与字段名列表一一对应。 值表达式可以是一个“直接值”, 或函数调用的结果,或变量
2)形式2: replace [into] 表名 [(字段名1,字段名2,....)] values(值表达式1, 值表达式2,.......),(.....),...;
与形式1的区别: 如果插入的数据的主键或唯一键有重复, 则此时就会变为“修改该行数据”。
既会先删除原来的数据行,然后插入该数据。
3)形式3: insert [into] 表名 [(字段名1,字段名2,....)] select 字段名1,字段名2,..... from 其他表名;
将select语句查询的结果都插入到指定的数据表中。注意:字段要对应,既select 结果字段与 插入表的字段要一一对应。
4) 形式4: insert [into] 表名 set 字段名1=值表达式1,字段名2=值表达式2,....;
一次只能插入一行语句
完整复制表(包括表结构和表数据): create table 新表名 select * from 旧表名;
字符串类型和时间类型的字面量需要用引号括起来。


#主键的作用: 保证每一行数据具有唯一性:create tabletab_no_primary (
idint,
namevarchar(10)
);insert into tab_no_primary values(1,'aa');insert into tab_no_primary values(1,'aa');
#对比表和对比数据--主键与非主键表插入重复数据对比
create tabletab_primary(
idint,
namevarchar(10),primary key(id)
);insert into tab_primary values(1,'aa');insert into tab_primary values(1,'aa'); #报错
#replace into语句insert into tab_primary values(1,'bb'); # 会报错 主键已经存在replace into tab_primary values(1,'bb'); # 会将相同主键的数据给修改
#insert into ...... select...语句insert into tab_no_primary select * from tab_primary;
【点击查看】插入数据Demo
load 插入
载入文本数据:load data infile 完整数据路径 into table 表名
适用于: 结构整齐的纯文本数据
删除数据 (删)
形式: delete from 表名 【where 条件】 【order by 排序】 【limit 限定行数】
以行为单位进行删除。为了安全通常删除都要带where条件
常见使用形式: delete from 表名 where 条件
修改数据 (改)
形式: update 表名 set 字段1=值1,字段2=值2,.... 【where 条件】 【order by 排序】 【limit 限定行数】
update时一把需加where条件,否则会同时修改全部数据。
字符串或时间类型的值要加引号。
常见形式: update 表名 set 字段1=值1,字段2=值2,.... where条件
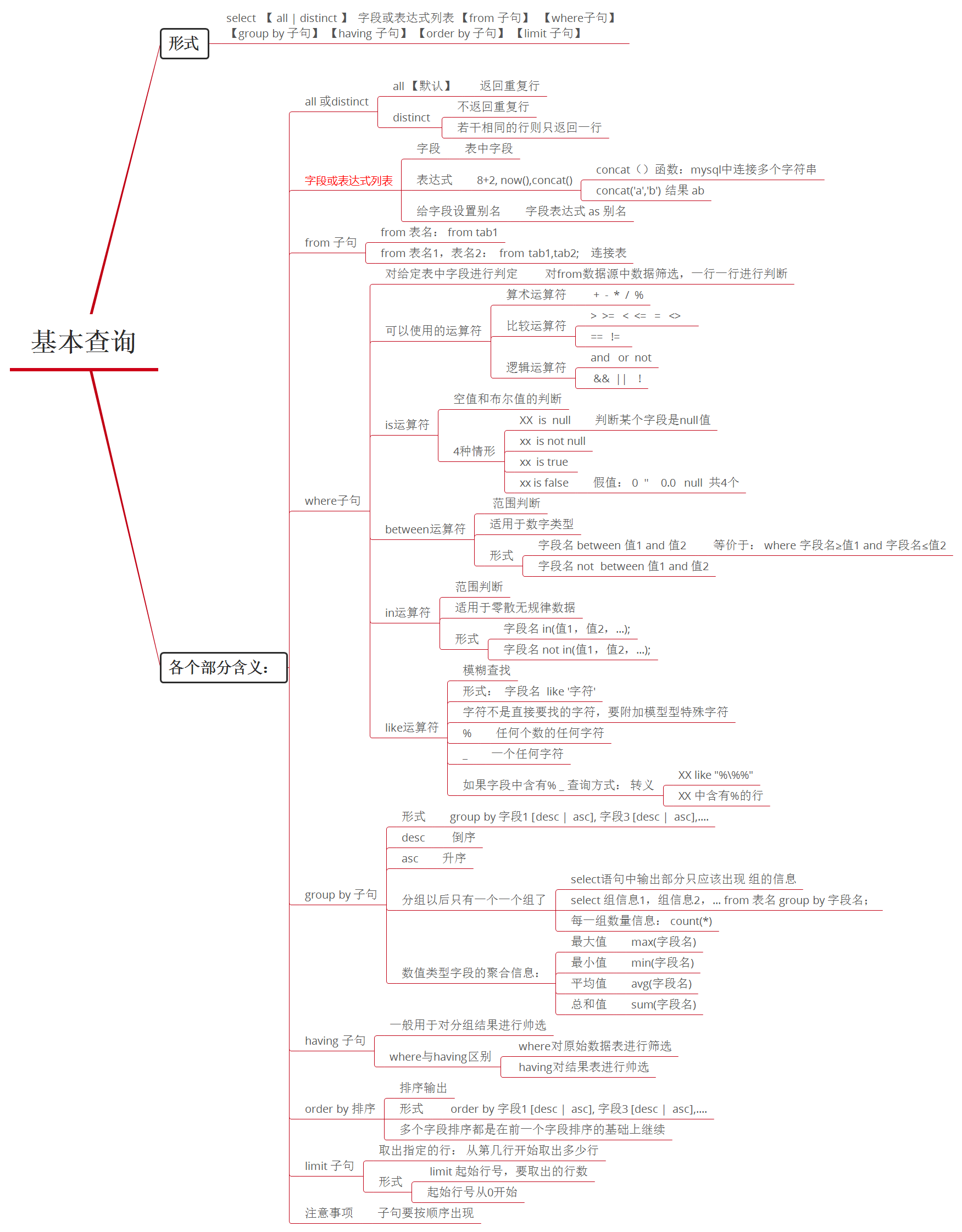
数据查询语言DQL
形式:
select 【all | distinct】 字段或表达式列表 【from子句】 【where子句】 【group by子句】 【having子句】 【order by子句】【limit 子句】
【】可以省略, 如果出现,需要按上述顺序书写。
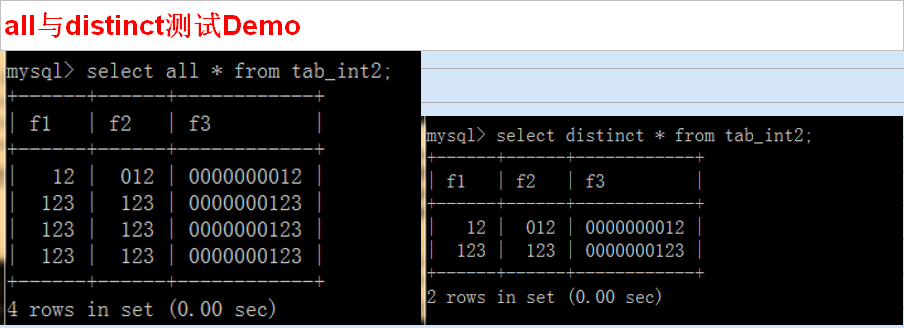
all 与 distinct
用于设定select出来的数据,是否消除“重复行”,可以不写,默认是all
是否返回取得的数据中的重复行。
all 表示会返回重复行。
distinct表示不返回重复行。即重复的若干行数据就只返回一行。
字段或表达式列表
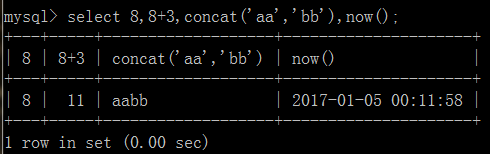
字段,来自于“表”。 表达式类似这样的一个内容: 8+3, now()
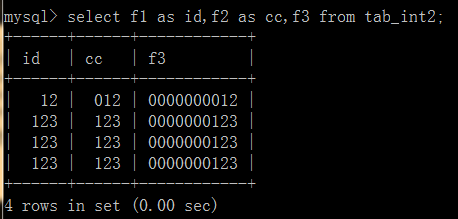
每“输出项”(字段或表达式或结果),都可以给其设定一个别名(字段别名)。形式为: 字段表达式 as 别名
concat()函数是mysql中的系统函数,用于"连接"多个字符串
子句
1) from子句
情形1: from 表名;
情形2: from 表1,表2,表3,...
2) where子句
where子句就是对from子句中的“数据源”中的数据进行筛选的条件设定
常使用的运算符:
1. 算术运算符: + - * / %
2. 比较运算符: > >= ==(等于) !=(不等于)
3. 逻辑运算符: and or not 。也可以用 && || !
4. is运算符: 空值和布尔值的判断
假值的4种情形: 0 0.0 null ''
1) XX is null 判断某个字段是"null"值---就是没有值
2) XX is not null 判断某个字段不是"null"值3) XX istrue 判断某个字段为“真"(true)4) XX is fasle 判断某个字段为“假"(false)
【点击查看】is运算符的4种形式
5. between 运算符: 范围判断, 适用于数字类型
# 表示该字段的值在给定的两个值之间,包含该两值
形式1: 字段名between 值1 and值2
形式2: 字段名not between 值1 and值2 (相反含义)
#如:where id between 1 and 5, 则返回id≥1且id≤5的数据。
# 相当于 id≥1 and id≤5;
【点击查看】between使用形式
6. in运算符: 给定确定数据范围的判断
#找出字段值等于所给定的那些值之一的数据行。 一般是零散无规律的数据。
形式1: 字段名in(值1,值2,.........)
形式2: 字段名not in(值1,值2,.........).
#如:where id in (5,7,8), 则会返回id等于5或7或8的数据行。
#where id not in(5,7,8),表示除了这3个的其他所有
【点击查看】where语句的使用
7. like运算符: 对字符串进行模糊查找
#从字符串中找出含有指定字符的数据--”模糊查找“
字段名 like '要查找的内容'#要附上一些表示模糊性的特殊字符。
#依赖于以下2个特殊的”符号“1) %: 它代表”任何个数的任何字符“2) _: 下划线它代表”一个任何字符“
#常见形式使用:1) name like '%张%': 表示name中含"张"这个字的所有数据行2) name like '张%': 表示name中以"张"开头的所有数据行3) name like '%张': 表示name中以"张"这个字结尾的所有数据行4) name like '张_': 表示name中以"张"这个字开头,并且只有2个字符的所有数据行5) name like '_张': 表示name中以"张"这个字结尾,并且只有2个字符的所有数据行
#要找某个字段中含”%“或”_“的行 =>转义;1) XX like "%\%%": 表示XX中含有%的多有行2) \%: 代表%本身 \_: 代表下划线本身
【点击查看】like使用
3)group by 子句
形式: group by 字段1 【desc | asc】,字段2 【desc | asc】,........
分组:就是多行数据,以某种标准(即指定的字段)来进行分类存放
#在select 语句中”输出“(取出)部分,只应该出现”组的信息“select 组信息1,组信息2,..... from 数据源 group by字段;
#应用中分组之后,一般只有如下可供查询的“组信息”(即可以出现在select中的)1) 分组依赖本身的信息,其实就是该分组依据的字段名。2) 每一组的“数量信息”就是用count(*)获得3)原来数据中的“数值类型字段的聚合信息”,包括如下几个:
最大值:max(字段名)
最小值:min(字段名)
平均值:avg(字段名)
总和值:sum(字段名)
【点击查看】分组信息查询
4)having 子句
where对原始数据进行筛选,既原表中存在的字段数据
having 对查询结果集的数据进行筛选,既查询出的字段数据
5)order by 子句
形式: order by 字段1 【asc | desc】,字段2 【asc | desc】,......
对前面的结果数据以指定的一个或多个字段排序。多个字段的排序,都是在前一个字段排序基础上,如果还有“想等值”,就继续后续字段排序
6)limit 子句
将“前述取得的数据”,按指定的行取出来:从第几行开始取出多少行。
形式:limit 起始行号,要取出的行数;
起始行号从0开始
简略形式:limit 行数; 表示直接从第0行开始取出指定的行数,
1) 在形式上,select的很多子句都可以省略,只要出现他们必须按照顺序写出。2) where子句依赖于from子句。即没有from即不能有where3) 各子句的“内部执行过程“,基本都是按照该顺序进行的
即从from的数据源中获得”所有权,然后使用where对这些数据进行筛选,
之后再使用group by子句对筛选出的数据进行分组,
接下来使用having对这些分组的数据进行筛选,
然后orderby 和limit.
【点击查看】select查询
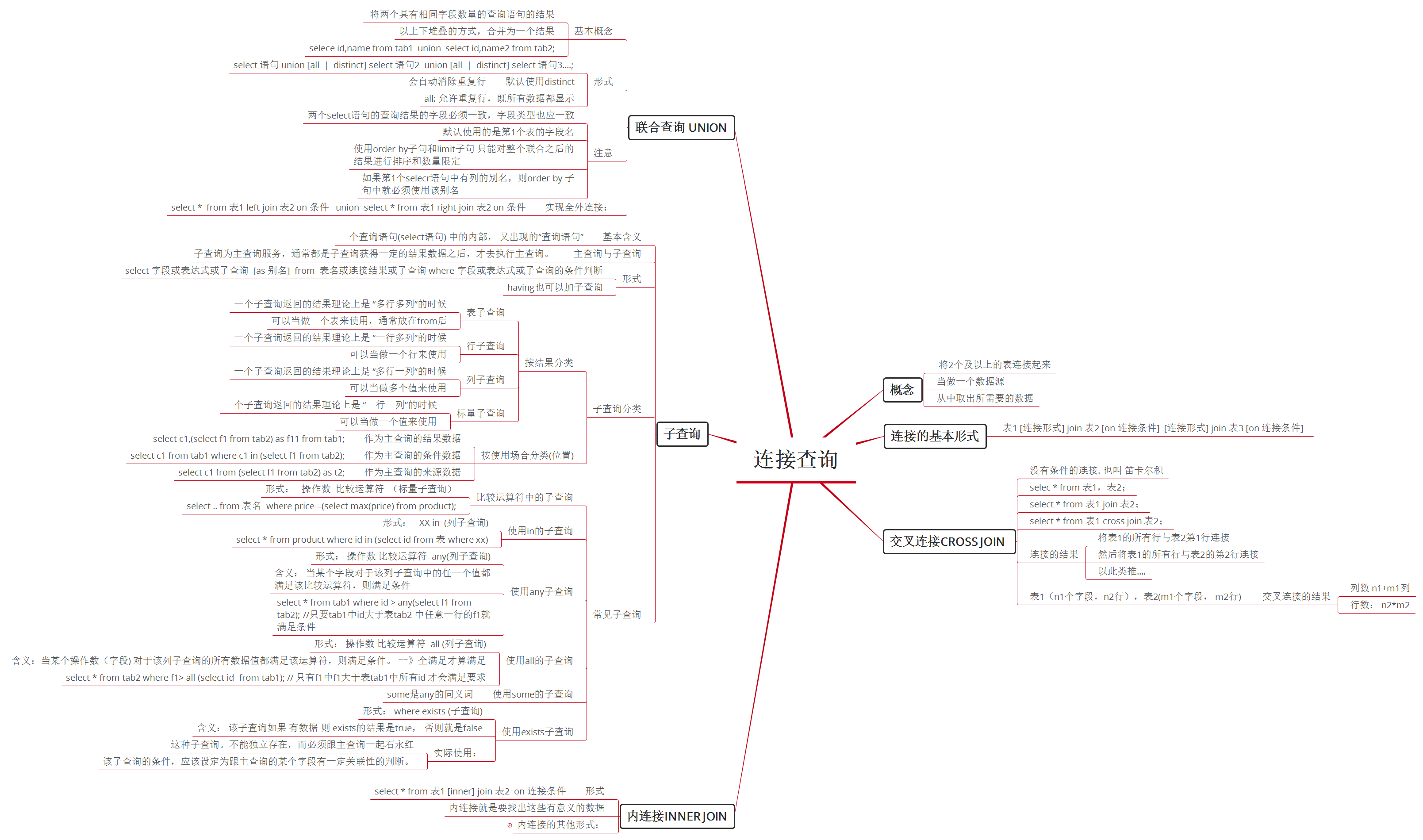
连接查询
概念:就是将2个或2个以上的表,”连接起来“,当作一个数据源,并从中去取得所需要的数据
连接的基本形式: 表1 [连接形式] join 表2 [on 连接条件] [连接形式] join 表3 [on 连接条件] ....
交叉连接cross join
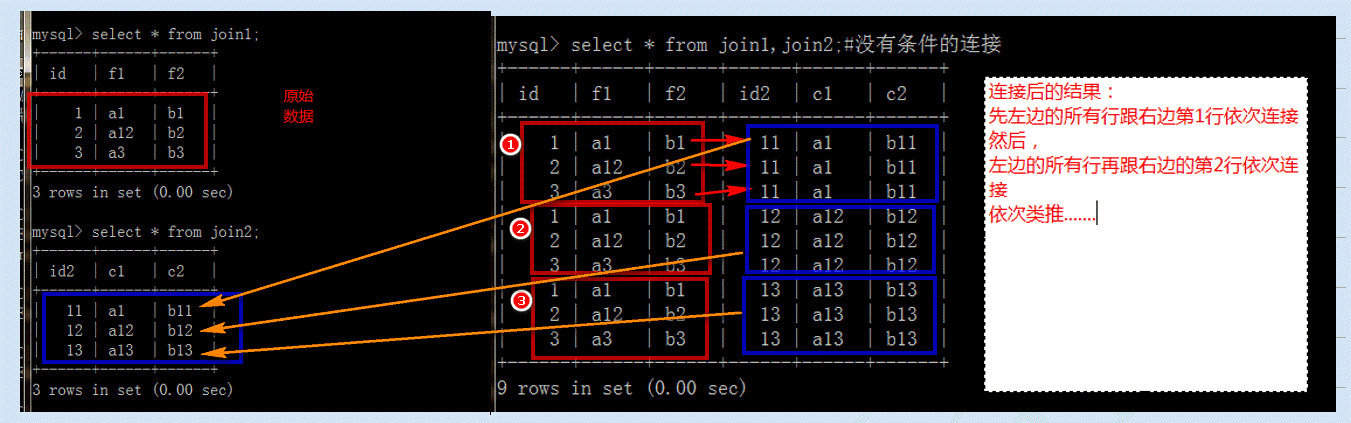
概念: 没有条件的连接. 也叫 笛卡尔积
连接的结果:将表1的所有行与表2第1行连接,然后将表1的所有行与表2的第2行连接,....
表1(n1个字段,n2行),表2(m1个字段, m2行) 交叉连接的结果: 列数 n1+m1列 行数: n2*m2
select * from表1,表2;select * from 表1 join表2;select * from 表1 cross join 表2;
无条件的连接形式
内连接 inner join
形式: select * from 表1 [inner] join 表2 on 连接条件
内连接的其他形式:
左(外)连接:left (outer) join
形式: 表1 left [outer] join 表2 on 连接条件
结果: 表1与表2内连接的结果,再加上左边表的不符合 内连接所设定的条件的那些数据的结果
左表的数据全部取出, 右表不存在对应时,显示为NULL
右(外)连接:right (outer) join
形式: 表1 right [outer] join 表2 on 连接条件
结果: 表1与表2内连接的结果,再加上右边表的不符合 内连接所设定的条件的那些数据的结果
右表的数据全部取出, 左表不存在对应时,显示为NULL
全连接: full (outer) join
形式: MySQL不支持
含义:将2个表的内连接的结果,加上左边表的不符合内连接设定条件的数据,再加上右边表的不符合 内连接所设定条件的数据
子查询
基本含义:一个查询语句(select语句) 中的内部, 又出现的“查询语句”
主查询与子查询:子查询为主查询服务,通常都是子查询获得一定的结果数据之后,才去执行主查询。
形式:select 字段或表达式或子查询 [as 别名] from 表名或连接结果或子查询 where 字段或表达式或子查询的条件判断
having也可以加子查询
子查询分类:
按结果分类:
表子查询: 一个子查询返回的结果理论上是 “多行多列”的时候。可以当做一个表来使用,通常放在from后
行子查询: 一个子查询返回的结果理论上是 “一行多列”的时候。可以当做一个行来使用
列子查询:一个子查询返回的结果理论上是 “多行一列”的时候。可以当做多个值来使用
标量子查询:一个子查询返回的结果理论上是 “一行一列”的时候。可以当做一个值来使用
按使用场合分类(位置):
作为主查询的结果数据:select c1,(select f1 from tab2) as f11 from tab1;
作为主查询的条件数据:select c1 from tab1 where c1 in (select f1 from tab2);
作为主查询的来源数据:select c1 from (select f1 from tab2) as t2;
常见子查询:
1)比较运算符中的子查询
形式: 操作数 比较运算符 (标量子查询)
例子: select .. from 表名 where price =(select max(price) from product);
2)使用in的子查询
形式: XX in (列子查询)
select * from product where id in (select id from 表 where xx)
3)使用any子查询
形式: 操作数 比较运算符 any(列子查询)
含义: 当某个字段对于该列子查询中的任一个值都满足该比较运算符,则满足条件
select * from tab1 where id > any(select f1 from tab2); //只要tab1中id大于表tab2 中任意一行的f1就满足条件
4)使用all的子查询
形式: 操作数 比较运算符 all (列子查询)
含义:当某个操作数(字段) 对于该列子查询的所有数据值都满足该运算符,则满足条件。 ==》全满足才算满足
select * from tab2 where f1> all (select id from tab1); // 只有f1中f1大于表tab1中所有id 才会满足要求
5) 使用some的子查询
some是any的同义词
使用exists子查询
形式: where exists (子查询)
含义: 该子查询如果 有数据 则 exists的结果是true, 否则就是false
实际使用:这种子查询。不能独立存在,而必须跟主查询一起石永红
该子查询的条件,应该设定为跟主查询的某个字段有一定关联性的判断。
联合查询
基本概念:将两个具有相同字段数量的查询语句的结果,以“上下堆叠”的方式,合并为一个结果
语法形式:select 语句 union [all|distinct] select 语句2 union [all|distinct] select 语句3......;
实现全外连接: select * from 表1 left join 表2 on 条件 union select * from 表1 right join 表2 on 条件
注:1)select语句的查询结果的字段数量必须一致,一般字段类型也一致。
2)默认会自动消除重复行,既默认选择的是distinct。 要显示包括重复行的所有数据,应选择all .
3) 联合查询的结果默认使用第1个select语句中的字段名
4) 使用order by 和 limit子句 默认是对联合之后的结果进行排序和数量限定。
5)如果第1个select语句中的列设置了别名, 则order by 子句中必须使用该别名















 116
116











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









