






re模块:
就其本质而言,正则表达式(或RE)是一种小型的、高度专业化的编程语言,它内嵌在python中,并通过re模块来实现。
对字符串进行处理,解决模糊匹配
元字符:.^$*+?{}[] | () \
1. . 通配符,什么都能匹配,除了换行符\n

2. ^ 只能在字符串的开头匹配

3. $ 只能在结尾匹配

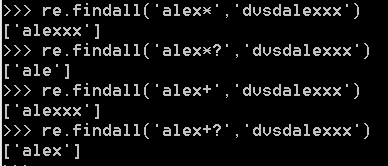
4. * 按*前紧挨着的字符去重复[0,无穷](贪婪匹配)

4. + 按+前紧挨着的字符去重复[1,无穷](贪婪匹配)

5. ? 按?前紧挨着的字符去重复 [0,1]

6. {} 万能的,可以自定义范围{0,}==* (贪婪匹配)
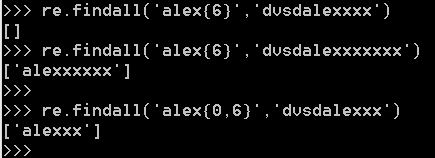
7. *,+前加上?就变成惰性匹配
8. [] 或者的关系,只要匹配到[]里的任意一个字符就可以([]里没有特殊符号)
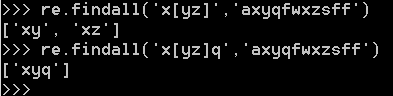
([]里没有特殊符号)但 - ^ \ 是特殊(-代表范围,^代表非,\是转义字符)


9. \后跟元字符去除特殊功能
\后跟普通字符实现特殊功能
\d代表任意十进制数

\D匹配任意非数字字符

\s匹配任何空白字符,\S匹配任何非空白字符

\w匹配任何数字字母字符,\W匹配任何非数字字母字符

10. \ 转义字符
经过两层,一层是python,一层是re
11. | 分为两部分,当成整体

12. () 分组 组的名字自己定义,以下有“name”,"age"

re 模块之方法:
1.search() 只匹配一次 匹配不成功不返回结果,匹配成功返回对象
2.match() 在开头匹配且只匹配一次

3.split() 先按‘a’分,分为‘ ’和‘bcd’,然后把‘bcd’按‘b’分

4.sub() 替换

5.compile() 不用调用re方法,也不用写第一个参数:规则

6.finditer() 把结果放到迭代器里了,然后通过next方法一个一个拿出来

7.注意:
如果要匹配的内容里有分组,python会优先匹配分组里的内容,而不会显示完整的要匹配的内容
加上 ?: 可以去掉优先级


8.group()
正则表达式中,group()用来提出分组截获的字符串,()用来分组
import re a = "123abc456" print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(0) #123abc456,返回整体 print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(1) #123 print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(2) #abc print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(3) #456
1. 正则表达式中的三组括号把匹配结果分成三组
- group() 同group(0)就是匹配正则表达式整体结果
- group(1) 列出第一个括号匹配部分,group(2) 列出第二个括号匹配部分,group(3) 列出第三个括号匹配部分。
2. 没有匹配成功的,re.search()返回None
3. 当然郑则表达式中没有括号,group(1)肯定不对了。















 8595
8595

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









