







后台可回复【数据库】即可获取相关宝藏内容分享:)
前言:
Q: 为什么面试问你MySQL优化的知识 总是没有特别特别足的底气回复??
A: 因为你只是回答一些大而化之的调优原则,
比如:”建立合理索引”(什么样的索引合理?)
“分表分库”(用什么策略分表分库?)
“主从分离”(用什么中间件?)
并没有从细化到定量的层面去分析.
如qps提高了%N? 有没有减少文件排序?
语句的扫描行数减少了多少?
ps:QPS一般指每秒查询率。每秒查询率(QPS,Queries-per-second)
没有大量的数据供测试,一般在学习环境中,只是手工添加几百上万条数据,数据量小,看不出语句之间的明确区别.
Q: 如何提高MySQL的性能?
A: 需要优化,则说明效率不够理想.
因此我们首先要做的,不是优化,而是---诊断.
治病的前提,是诊病,找出瓶颈所在.
CPU,内存,IO? 峰值,单条语句?
今天文章分为两部分 :)
PART1 MySQL技术分享 / PART2 关于聚类算法分享
5 Minutes to Mysql:
PART 1 MySQL性能优化
学长五分钟带你走进数据库高端操作
首先在优化性能之前,我们需要懂得了解一些关于数据库索引内容/需要了解索引是什么,怎么去使用,有啥子原则规范等内容...如果你还不懂索引,就暂时先去翻翻新华字典。不仅近会告诉你啥叫“索引”还能让你体验一番。

索引的设计原则
创建索引的列并不一定是select操作中要查询的列,最适合做索引的列是出现在where子句中经常用作筛选条件或连表子句中作为表连接条件的列。具有唯一性的列,索引效果好;重复值较多的列,索引效果差。如果为字符串类型创建索引,最好指定一个前缀长度,创建短索引。短索引可以减少磁盘I/O而且在做比较时性能也更好,更重要的是MySQL底层的高速索引缓存能够缓存更多的键值。创建一个包含N列的复合索引(多列索引)时,相当于是创建了N个索引,此时应该利用最左前缀进行匹配。不要过度使用索引。索引并不是越多越好,索引需要占用额外的存储空间而且会影响写操作的性能(插入、删除、更新数据时索引也需要更新)。MySQL在生成执行计划时,要考虑各个索引的使用,这个也是需要耗费时间的。要注意可能使索引失效的场景,例如:模糊查询使用了前置通配符、使用负向条件进行查询等。
使用过程
过程,通常也称之为存储过程,它是事先编译好存储在数据库中的一组SQL的集合。调用存储过程可以简化应用程序开发人员的工作,减少与数据库服务器之间的通信,对于提升数据操作的性能是有帮助的/
数据分区
MySQL支持做数据分区,通过分区可以存储更多的数据、优化查询,获得更大的吞吐量并快速删除过期的数据。关于这个知识点建议大家看看MySQL的官方文档。数据分区有以下几种类型:RANGE分区:基于连续区间范围,把数据分配到不同的分区。CREATE TABLE tb_emp ( eno INT NOT NULL, ename VARCHAR(20) NOT NULL, job VARCHAR(10) NOT NULL, hiredate DATE NOT NULL, dno INT NOT NULL)PARTITION BY RANGE( YEAR(hiredate) ) ( PARTITION p0 VALUES LESS THAN (1960), PARTITION p1 VALUES LESS THAN (1970), PARTITION p2 VALUES LESS THAN (1980), PARTITION p3 VALUES LESS THAN (1990), PARTITION p4 VALUES LESS THAN MAXVALUE);LIST分区:基于枚举值的范围,把数据分配到不同的分区。HASH分区 / KEY分区:基于分区个数,把数据分配到不同的分区。CREATETABLEtb_emp (eno INTNOT NULL, ename VARCHAR(20) NOT NULL, job VARCHAR(10) NOT NULL, hiredate DATENOT NULL, dno INTNOT NULL)PARTITION BY HASH(dno)PARTITIONS 4;
SQL优化-查找问题
定位低效率的SQL语句 - 慢查询日志。查看慢查询日志相关配置mysql> show variables like 'slow_query%';修改全局慢查询日志配置。mysql> set global slow_query_log='ON';mysql> set global long_query_time=1;或者直接修改MySQL配置文件启用慢查询日志。[mysqld]slow_query_log=ONslow_query_log_file=/usr/local/mysql/data/slow.loglong_query_time=1通过explain了解SQL的执行计划。例如:explain select ename, job, sal from tb_emp where dno=20\G***************************1. row ***************************id: 1 select_type: SIMPLE table: tb_emp type: refpossible_keys: fk_emp_dno key: fk_emp_dno key_len: 5 ref: const rows: 7 Extra: NULL1 row inset (0.00 sec)select_type:查询类型(SIMPLE - 简单查询、PRIMARY - 主查询、UNION - 并集、SUBQUERY - 子查询)。table:输出结果集的表。type:访问类型(ALL - 全表查询性能最差、index、range、ref、eq_ref、const、NULL)。possible_keys:查询时可能用到的索引。key:实际使用的索引。key_len:索引字段的长度。rows:扫描的行数,行数越少肯定性能越好。extra:额外信息。通过show profiles和show profile for query分析SQL。MySQL从5.0.37开始支持剖面系统来帮助用户了解SQL执行性能的细节,可以通过下面的方式来查看MySQL是否支持和开启了剖面系统。select @@have_profiling;select @@profiling;如果没有开启剖面系统,可以通过下面的SQL来打开它。set profiling=1;接下来就可以通过剖面系统来了解SQL的执行性能,例如:mysql> select count(*) from tb_emp;mysql> show profiles;mysql> show profile for query 1;优化CRUD操作。USE INDEX:建议MySQL使用指定的索引。IGNORE INDEX:建议MySQL忽略掉指定的索引。FORCE INDEX:强制MySQL使用指定的索引。分页查询时,一个比较头疼的事情是如同limit 1000, 20,此时MySQL已经排序出前1020条记录但是仅仅返回第1001到1020条记录,前1000条实际都用不上,查询和排序的代价非常高。一种常见的优化思路是在索引上完成排序和分页的操作,然后根据返回的结果做表连接操作来得到最终的结果,这样可以避免出现全表查询,也避免了外部排序。select * from tb_emp order by ename limit 1000, 20;select * from tb_emp t1 inner join (select eno from tb_emp order by ename limit 1000, 20) t2 on t1.eno=t2.eno;上面的代码中,第2行SQL是优于第1行SQL的,当然我们的前提是已经在ename字段上创建了索引。如果条件之间是or关系,则只有在所有条件都用到索引的情况下索引才会生效。MySQL从4.1开始支持嵌套查询(子查询),这使得可以将一个查询的结果当做另一个查询的一部分来使用。在某些情况下,子查询可以被更有效率的连接查询取代,因为在连接查询时MySQL不需要在内存中创建临时表来完成这个逻辑上需要多个步骤才能完成的查询。在使用group by子句分组时,如果希望避免排序带来的开销,可以用order by null禁用排序。如果where子句的条件和order by子句的条件相同,而且排序的顺序与索引的顺序相同,如果还同时满足排序字段都是升序或者降序,那么只靠索引就能完成排序。在insert语句后面跟上多组值进行插入在性能上优于分开insert。如果有多个连接向同一个表插入数据,使用insert delayed可以获得更好的性能。如果要从一个文本文件装载数据到表时,使用load data infile比insert性能好得多。优化insert语句优化order by语句优化group by语句优化嵌套查询优化or条件优化分页查询使用SQL提示
配置优化
可以使用下面的命令来查看MySQL服务器配置参数的默认值。show variables;show variables like 'key_%';show variables like '%cache%';show variables like 'innodb_buffer_pool_size';通过下面的命令可以了解MySQL服务器运行状态值。showstatus;showstatuslike'com_%';showstatuslike'innodb_%';showstatuslike'connections';showstatuslike'slow_queries';调整max_connections:MySQL最大连接数量,默认151。在Linux系统上,如果内存足够且不考虑用户等待响应时间这些问题,MySQL理论上可以支持到万级连接,但是通常情况下,这个值建议控制在1000以内。调整back_log:TCP连接的积压请求队列大小,通常是max_connections的五分之一,最大不能超过900。调整table_open_cache:这个值应该设置为max_connections的N倍,其中N代表每个连接在查询时打开的表的最大个数。调整innodb_lock_wait_timeout:该参数可以控制InnoDB事务等待行锁的时间,默认值是50ms,对于反馈响应要求较高的应用,可以将这个值调小避免事务长时间挂起;对于后台任务,可以将这个值调大来避免发生大的回滚操作。调整innodb_buffer_pool_size:InnoDB数据和索引的内存缓冲区大小,以字节为单位,这个值设置得越高,访问表数据需要进行的磁盘I/O操作就越少,如果可能甚至可以将该值设置为物理内存大小的80%。
架构优化
通过拆分提高表的访问效率。垂直拆分水平拆分
逆范式理论。数据表设计的规范程度称之为范式(Normal Form),要提升表的规范程度通常需要将大表拆分为更小的表,范式级别越高数据冗余越小,而且在插入、删除、更新数据时出问题的可能性会大幅度降低,但是节省了空间就意味着查询数据时可能花费更多的时间,原来的单表查询可能会变成连表查询。为此,项目实践中我们通常会进行逆范式操作,故意降低范式级别增加冗余来减少查询的时间开销。1NF:列不能再拆分2NF:所有的属性都依赖于主键3NF:所有的属性都直接依赖于主键(消除传递依赖)BCNF:消除非平凡多值依赖使用中间表提高统计查询速度。使用insert into 中间表 select ... where ...这样的语句先将需要的数据筛选出来放到中间表中,然后再对中间表进行统计,避免不必要的运算和处理。主从复制和读写分离,具体内容请参考网络。后期学长也搞一遍分享出来。配置MySQL集群。说明:本章内容参考了网易出品的《深入浅出MySQL》一书,该书和《高性能MySQL》一样,都对MySQL进行了深入细致的讲解,虽然总体感觉后者更加高屋建瓴,但是前者也算得上是提升MySQL技能的佳作(作者的文字功底稍显粗糙,深度也不及后者),建议有兴趣的读者可以阅读这两本书。
看到这里的同学有福啦,学长分享一波宝藏收藏资源
后台可回复【数据库】即可获取相关内容分享:)
好!回归每周的闲言碎语!
PART2 >今天来分享一个关于算法的内容
分享灵感来源周五的部门技术开会-
一. 先从上周五的一次会议说起
一个慵懒的周五下午,一次长达数小时的项目需求分享,身为“默默无名”开发的学长,恍恍惚惚听了一下午,没有任何张口机会,不过以为同事分享的关于算法聚类的内容吸引到了我,瞬间精神~回忆起之前的知识感觉还是蛮不错的。之前了解的聚类算法_层次聚类_密度聚类(dbscan,meanshift)_划分聚类(Kmeans),基本忘得差不多了,恰好他提起,就复习一下。
二. 温故而知新
DBSCAN聚类算法(源于我之前学习博客)
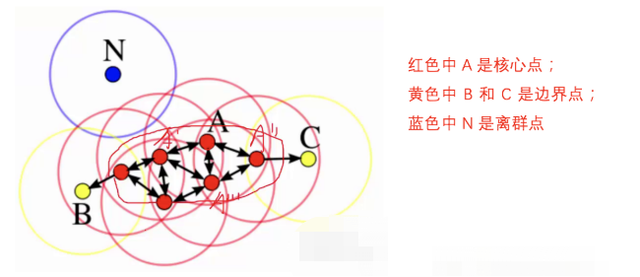
下面这几个点是分布在样本空间的众多样本,现在我们的目标是把这些在样本空间中距离相近的聚成一类。我们发现A点附近的点密度较大,红色的圆圈根据一定的规则在这里滚啊滚,最终收纳了A附近的5个点,标记为红色也就是定为同一个簇。其它没有被收纳的根据一样的规则成簇。(形象来说,我们可以认为这是系统在众多样本点中随机选中一个,围绕这个被选中的样本点画一个圆,规定这个圆的半径以及圆内最少包含的样本点,如果在指定半径内有足够多的样本点在内,那么这个圆圈的圆心就转移到这个内部样本点,继续去圈附近其它的样本点,类似传销一样,继续去发展下线。等到这个滚来滚去的圈发现所圈住的样本点数量少于预先指定的值,就停止了。那么我们称最开始那个点为核心点,如A,停下来的那个点为边界点,如B、C,没得滚的那个点为离群点,如N)。
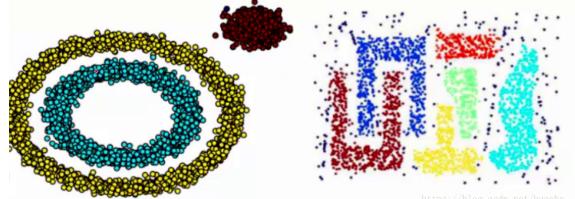
基于密度这点有什么好处呢,我们知道kmeans聚类算法只能处理球形的簇,也就是一个聚成实心的团(这是因为算法本身计算平均距离的局限)。但往往现实中还会有各种形状,比如下面两张图,环形和不规则形,这个时候,那些传统的聚类算法显然就悲剧了。于是就思考,样本密度大的成一类呗。呐这就是DBSCAN聚类算法。
参数选择
上面提到了红色圆圈滚啊滚的过程,这个过程就包括了DBSCAN算法的两个参数,这两个参数比较难指定,公认的指定方法简单说一下:
半径:半径是最难指定的 ,大了,圈住的就多了,簇的个数就少了;反之,簇的个数就多了,这对我们最后的结果是有影响的。我们这个时候K距离可以帮助我们来设定半径r,也就是要找到突变点,比如:

以上虽然是一个可取的方式,但是有时候比较麻烦 ,大部分还是都试一试进行观察,用k距离需要做大量实验来观察,很难一次性把这些值都选准。
MinPts:这个参数就是圈住的点的个数,也相当于是一个密度,一般这个值都是偏小一些,然后进行多次尝试
DBSCAN算法迭代可视化展示
国外有一个特别有意思的网站:
https://www.naftaliharris.com/blog/visualizing-dbscan-clustering/
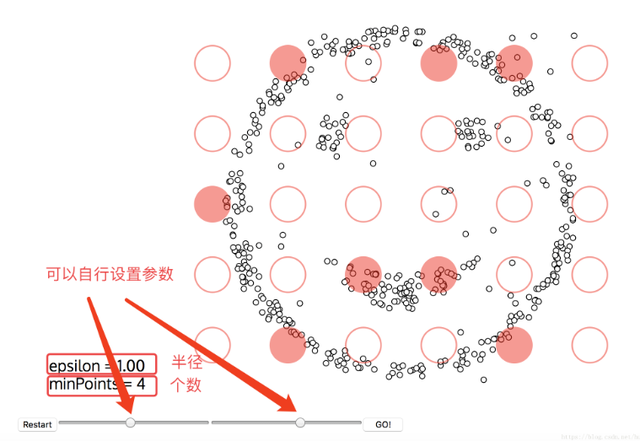
它可以把我们DBSCAN的迭代过程动态图画出来
设置好参数,点击GO! 就开始聚类了!
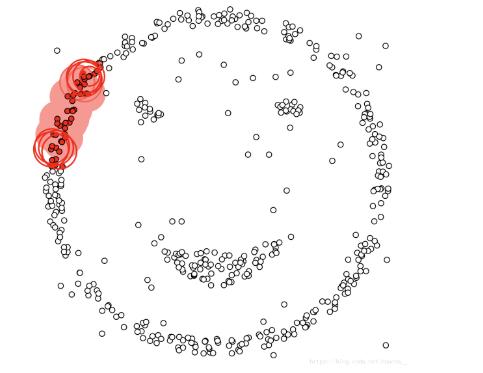
直接跳到最后看一下DBSCAN的聚类结果,如下:
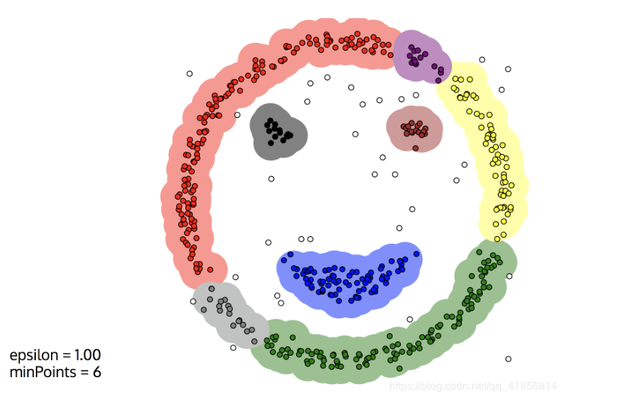
如果minPoints参数设置再大一点,那么这个笑脸可能会更好看。没有颜色标注的就是圈不到的样本点,也就是离群点,DBSCAN聚类算法在检测离群点的任务上也有较好的效果。
如果是传统的Kmeans聚类,我们也来看一下效果:
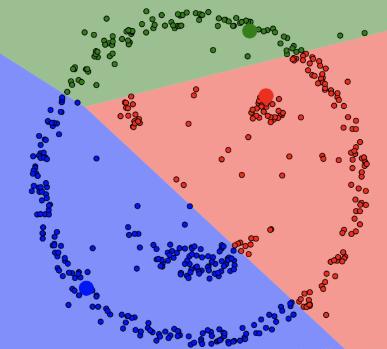
是不是好丑,这完美的体现出来DBSCAN算法基于密度聚类的优势了啊.
分享内容看似高端实则也不过如此
Pandas系列文章
【技术分析】数据处理工具Pandas 下
【技术分析】数据处理工具Pandas 上
关于数据分析的内容停更一期
我们下期见
django系列文章
【Django教程】第15天:ORM性能优化和提升【Django教程】第14天:debugtoolbar开发工具【Django教程】第13天:Email-邮件发送【Django教程】第12天:后台管理-admi【Django教程】第11天:自定义模板过滤【Django教程】第10天:模板语【Django教程】第09天:验证码【Django教程】第08天:会话机制Cookie&Sessio【Django教程】第07天:上传/显示图【Django教程】第06天:HttpRequest对象【Django教程】第05天:ORM模型操作汇【Django教程】第04天:前后端分离开发【Django教程】第03天:导出Excel报表【Django教程】第02天:深入模型【Django教程】第01天:快速上手
PS:公号内回复 :Python,即可获取最新最全学习资源!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









