






asyncio是从pytohn3.4开始添加到标准库中的一个强大的异步并发库,可以很好地解决python中高并发的问题,入门学习可以参考官方文档
并发访问能极大的提高爬虫的性能,但是requests访问网页是阻塞的,无法并发,所以我们需要一个更牛逼的库 aiohttp ,它的用法与requests相似,可以看成是异步版的requests,下面通过实战爬取猫眼电影专业版来熟悉它们的使用:
1. 分析
分析网页源代码发现猫眼专业版是一个动态网页,其中的数据都是后台传送的,打开F12调试工具,再刷新网页选择XHR后发现第一条就是后台发来的电影数据,由此得到接口 https://box.maoyan.com/promovie/api/box/second.json?beginDate=日期
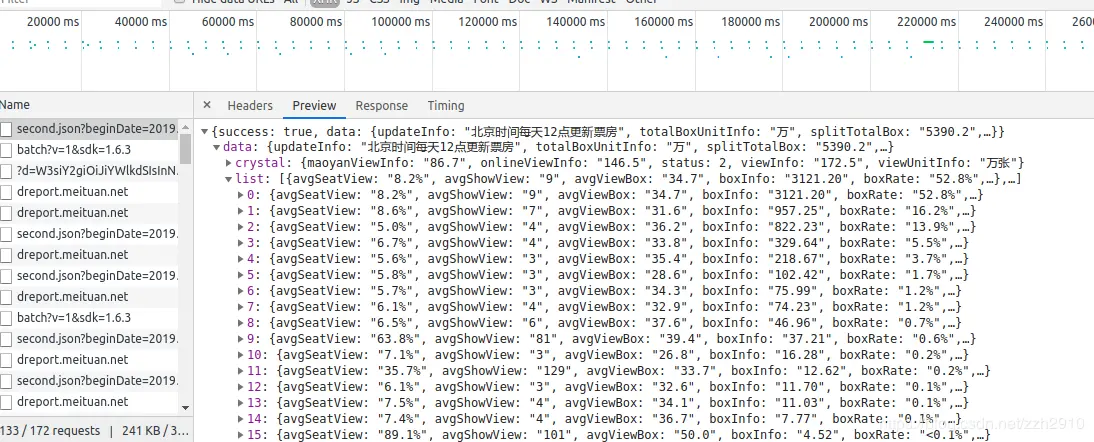
在这里插入图片描述
2. 异步爬取
创建20个任务来并发爬取20天的电影信息并写入csv文件,同时计算一下耗费的时间
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
|
import asyncio
from
aiohttp import ClientSession
import aiohttp
import time
import csv
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
headers = {
'User-Agent'
:
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/67.0.3396.99 Safari/537.36'
}
# 协程函数,完成一个无阻塞的任务
async def get_one_page(url):
try
:
conn = aiohttp.TCPConnector(verify_ssl=False) # 防止ssl报错
async with aiohttp.ClientSession(connector=conn)
as
session: # 创建session
async with session.
get
(url, headers=headers)
as
r:
# 返回解析为字典的电影数据
return
await r.json()
except Exception
as
e:
print(
'请求异常: '
+ str(e))
return
{}
# 解析函数,提取每一条内容并写入csv文件
def parse_one_page(movie_dict, writer):
try
:
movie_list = movie_dict[
'data'
][
'list'
]
for
movie
in
movie_list:
movie_name = movie[
'movieName'
]
release = movie[
'releaseInfo'
]
sum_box = movie[
'sumBoxInfo'
]
box_info = movie[
'boxInfo'
]
box_rate = movie[
'boxRate'
]
show_info = movie[
'showInfo'
]
show_rate = movie[
'showRate'
]
avg_show_view = movie[
'avgShowView'
]
avg_seat_view = movie[
'avgSeatView'
]
writer.writerow([movie_name, release, sum_box, box_info, box_rate,
show_info, show_rate, avg_show_view, avg_seat_view])
return
(
'写入成功'
)
except Exception
as
e:
return
(
'解析异常: '
+ str(e))
# 并发爬取
async def main():
# 待访问的20个URL链接
urls = [
'https://box.maoyan.com/promovie/api/box/second.json?beginDate=201904{}{}'
.format(i, j)
for
i
in
range(1, 3)
for
j
in
range(10)]
# 任务列表
tasks = [get_one_page(url)
for
url
in
urls]
# 并发执行并保存每一个任务的返回结果
results = await asyncio.gather(*tasks)
# 处理每一个结果
with open(
'pro_info.csv'
,
'w'
)
as
f:
writer = csv.writer(f)
for
result
in
results:
print(parse_one_page(result, writer))
if
__name__ ==
"__main__"
:
start = time.time()
# asyncio.run(main())
# python3.7之前的写法
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
loop.close()
print(time.time()-start)
|
3. 对比同步爬取
import requests
import csv import time headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) ' 'AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/67.0.3396.99 Safari/537.36'} def get_one_page(url): try: r = requests.get(url, headers=headers) r.raise_for_status() r.encoding = r.apparent_encoding return r.json() except Exception as e: print('请求异常: ' + e) return {} def parse_one_page(movie_dict, writer): try: movie_list = movie_dict['data']['list'] for movie in movie_list: movie_name = movie['movieName'] release = movie['releaseInfo'] sum_box = movie['sumBoxInfo'] box_info = movie['boxInfo'] box_rate = movie['boxRate'] show_info = movie['showInfo'] show_rate = movie['showRate'] avg_show_view = movie['avgShowView'] avg_seat_view = movie['avgSeatView'] writer.writerow([movie_name, release, sum_box, box_info, box_rate, show_info, show_rate, avg_show_view, avg_seat_view]) print('写入成功') except Exception as e: print('解析异常: ' + e) def main(): # 待访问的20个URL链接 urls = ['https://box.maoyan.com/promovie/api/box/second.json?beginDate=201903{}{}'.format(i, j) for i in range(1, 3) for j in range(10)] with open('out/pro_info.csv', 'w') as f: writer = csv.writer(f) for url in urls: # 逐一处理 movie_dict = get_one_page(url) parse_one_page(movie_dict, writer) if __name__ == '__main__': a = time.time() main() print(time.time() - a) 
在这里插入图片描述
可以看到使用asyncio+aiohttp的异步爬取方式要比简单的requests同步爬取快上不少,尤其是爬取大量网页的时候,这种差距会非常明显。















 810
810

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









