






常用的排序算法
常用的排序算法包含两大类,一类是基础比较模型的,也就是排序的过程,是建立在两个数进行对比得出大小的基础上,这样的排序算法又可以分为两类:一类是基于数组的,一类是基于树的;基础数组的比较排序算法主要有:冒泡法,插入法,选择法,归并法,快速排序法;基础树的比较排序算法主要有:堆排序和二叉树排序;基于非比较模型的排序,主要有桶排序和位图排序
冒泡排序:
思路很具有意思:循环,两两向后比较。具体方法是针对循环中的每一元素,都与它后面的元素进行循环比较,交换大小值,每次循环“冒”一个最大值(或最小值)放在里里层循环的初始位置 。它优点是稳定,不需要大量额外的空间开销,确定是慢。
由大到小排列:
def bubbleSort(mylist):
length = len(mylist)
if length == 0 or length == 1:
return list
for i in range(length):
for j in range(0,length-i-1):
if mylist[j] < mylist[j + 1]:
temp = mylist[j]
mylist[j] = mylist [j + 1]
mylist[j + 1] = temp
print("Round:",i,":",mylist)
if __name__ == "__main__":
mylist = [1, 3, 5, 2, 4, 8]
bubbleSort(mylist)
选择排序:
比起冒泡法,它的方法巧妙了一些,它的出发点在于“挑选”,每次挑选数组的最值,与前置元素换位,然后继续挑选剩余元素的最值并重复操作。选择排序的意义不在于排序本身,而在于挑选和置换的方法
def selectedSort(mylist):
length = len(mylist)
for i in range(0,length - 1):
for j in range(i , length):
if mylist[j] < mylist[i]:
tmp = mylist[j]
mylist[j] = mylist[i]
mylist[i] = tmp
print("Rount: ",i ,":",mylist)
if __name__ =="__main__":
mylist = [1,4,5,0,6,8,3,2,30,10,20,15]
selectedSort(mylist)
插入排序:
插入法和之前两个排序对比,并不在于如何按顺序的“取”,而在于如何按数序的“插”。具体方法是,顺序地从数组里获取数据,并在一个已经排序好的序列里,插入到对应的位置
def insertSort(list):
length = len(list)
if length == 0 or length == 1:
return list
for i in range(1,length):
V = list[i]
j = i - 1
while j>=0 and list[j] <V:
list[j+1] = list[j]
j -= 1
list[j+1] = V
print("Round:" ,i, ":", list)
if __name__ == "__main__":
list = [1,5,9,3,8,6,2]
insertSort(list)
这三种方法,都不可避免的两两排序,也就是任意两个元素都相互的做过对比,所以它们不管给定的数组的数据特点,都很稳定的进行对比,复杂度也就是NXN。
归并排序:
归并排序的“分”和“合”的核心,就是将两个已经排序好的数组,合成一个排序的数组,首先归并排序使用了二分法,归根到底的思想还是分而治之。拿到一个长数组,将其不停的分为左边和右边两份,然后以此递归分下去。然后再将她们按照两个有序数组的样子合并起来。
import random
# 随机生成0~100之间的数值
def get_andomNumber(num):
lists = []
i = 0
while i < num:
lists.append(random.randint(0, 100))
i += 1
return lists
# 归并排序
def merge(left, right):
i, j = 0, 0
result = []
while i < len(left) and j < len(right):
if left[i] <= right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
result += left[i:]
result += right[j:]
return result
def merge_sort(lists):
if len(lists) <= 1:
return lists
num = len(lists) // 2
left = merge_sort(lists[:num])
right = merge_sort(lists[num:])
return merge(left, right)
a = get_andomNumber(10)
print("排序之前:%s" % a)
b = merge_sort(a)
print("排序之后:%s" % b)
由于递归拆分的时间复杂度是logN 然而,进行两个有序数组排序的方法复杂度是N,该算法的时间复杂度是N*logN,所以是NlogN。
快速排序:
作为排序算法中老大级的快速排序,难点在于它的“分”和“合”,即选取待排序数组中的一个元素,将数组中比这个元素大的元素作为一部分,而比这个元素小的元素作为另一部分,再将这两个部分和并.
如果不考虑空间的申请,也就是不在元素组就行排序的话,这个算法写起来就是基本的递归调用。
算法描述:
1.先从数列中取出一个数作为基准数。
2.分区过程,将比这个数大的数全放到它的右边,小于或等于它的数全放到它的左边。
3.再对左右区间重复第二步,直到各区间只有一个数。
def sub_sort(list,low,high):
K = list[low]
while low < high:
while low < high and list[high] >= K:
high -= 1
while low < high and list[high] <= K:
list[low] = list[high]
low += 1
list[high] = list[low]
list[low] = K
return low
def quick_sort(list,low,high):
if low < high:
K_index = sub_sort(list,low,high)
quick_sort(list,low,K_index)
quick_sort(list,K_index + 1,high)
if __name__ == "__main__":
list = [10,8,1,3,39,58,90,20,6,3,0,15]
print(list)
quick_sort(list,0,len(list)- 1)
print(list)
上面这几种,是比较模型中数组形式进行比较的,如果熟悉数据结构的话,当然会想到数组的另一个表示方式——树。使用树的方法进行对比的排序,这里讨论两个方法,堆排序和二叉树排序。
堆排序:
首先要知道的是,数组可以又一个二叉树来表示,既然是二叉树,它的表示也就是第一层一个节点,第二层两个节点,第三层四个节点,第四层八个节点。。。数组元素的放置位置就是挨着放,第一个元素放在第一层的唯一一个点,第二层的两个点放接下来的两个元素,即元素2和3,第三层的四个点,继续接下来的4个元素,即元素5、6、7、8。。。一直这么放下去,由于是二叉树,每次两分,所以树的深度是log2N。对于每一个节点,它的根节点在它的下一层,数组上的位置,就是2倍。
这就是一个数组的二叉树形式的理解,这是堆排序的基础(事实上这并不需要代码完成)。接下来的任务,是要把这个二叉树改造成所谓的堆。堆可以这样去理解,也就是对于二叉树来说,父节点的值大于子节点。在上面数组对应的二叉树中,我们需要将它改造成一个父节点值大于子节点值的二叉树。办法是从后向前的遍历每个父节点,每个父节点和两个子节点进行对比,并进行调整,直到形成一个堆——这个时候,根节点的值是最大的。
将这个跟节点的值和数组最后一个值进行换位,后然继续上面的调整,形成堆,找到根节点,与倒数第二个值换位。。。以此类推,直到数组排序完毕。这就是所谓的堆排序
如 维基百科http://zh.wikipedia.org/zh-cn/%E5%A0%86%E7%A9%8D%E6%8E%92%E5%BA%8F动图所示
一般用数组表示堆,若根结点存在序号0处, i结点的父结点下标就为(i-1)/2。i结点的左右子结点下标分别为2*i+1和2*i+2。(注:如果根结点是从1开始,则左右孩子结点分别是2i和2i+1。)
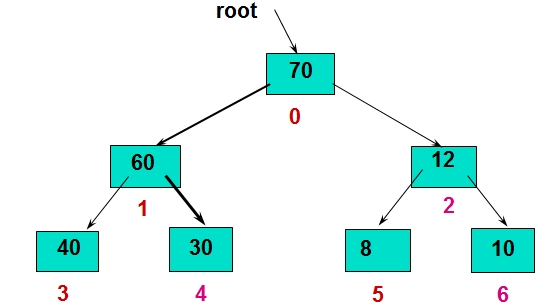
# 调整堆
def adjust_heap(lists, i, size):
lchild = 2 * i + 1
rchild = 2 * i + 2
max = i
if i < size / 2:
if lchild < size and lists[lchild] > lists[max]:
max = lchild
if rchild < size and lists[rchild] > lists[max]:
max = rchild
if max != i:
lists[max], lists[i] = lists[i], lists[max]
adjust_heap(lists,max,size)
# 创建堆
def build_heap(lists, size):
for i in range(0, (int(size/2)))[::-1]:
adjust_heap(lists, i, size)
# 堆排序
def heap_sort(lists):
size = len(lists)
build_heap(lists, size)
for i in range(0, size)[::-1]:
lists[0], lists[i] = lists[i], lists[0]
adjust_heap(lists, 0, i)
#return lists
print(lists)
if __name__ == "__main__":
list = [70, 60, 12, 40, 30, 8, 10 ]
heap_sort(list)
由于堆排序的堆的高度为log2N,而它每次调整的时候需要对比的次数趋向于N,所以整体的时间复杂度是N*log2N,但是它并不稳定的一种算法,依赖于给定的待排序数组。














 6018
6018











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









