







反向传播是为了更新参数,参数更新要用代价函数对参数求导,但是参数可能是经过很多层间接作用到最后一层的输出上的。 所以用先计算每层输入对最后代价函数的影响, 最后对参数的更新就可以表示为代价函数对每层的影响残差 (代价函数每一层的输入求偏导)再链式乘上输入对参数求偏导。最后参数的更新值就变为:每层的残差乘上上一层的输出。
而在计算每一层的残差时,l层的残差是建立在l+1层的残差之上的,因为我们最先能算出倒数第一层的残差,(代价函数对第l层的输入求偏导,相当于对l+1 层的输入求偏导,再乘上l+1层的输入对l层的输出求偏导,这两个值已经能得到)
激活函数详解:http://www.cnblogs.com/fanhaha/p/7061318.html


流程:
输入训练集
对于训练集中的每个样本x,设置输入层(Input layer)对应的激活值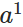 :
:
:
- 前向传播:
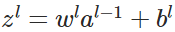 ,
,
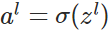
计算输出层产生的错误:
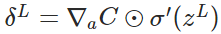
反向传播错误:
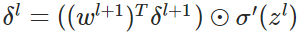
使用梯度下降(gradient descent),训练参数:
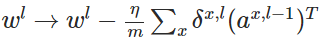
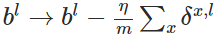
参考博文:http://www.cnblogs.com/Crysaty/p/6138390.html
补充问题: 防止过拟合?
梯度下降解释















 20万+
20万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









