







背景:
IK分词器分为两种,粗粒度分词和细粒度分词,粗粒度会分为长词,细粒度分出的词比较多,会分出与词库中所有可匹配的词,现在我们想要这样的分词效果如:
关键词:“北京青年路”
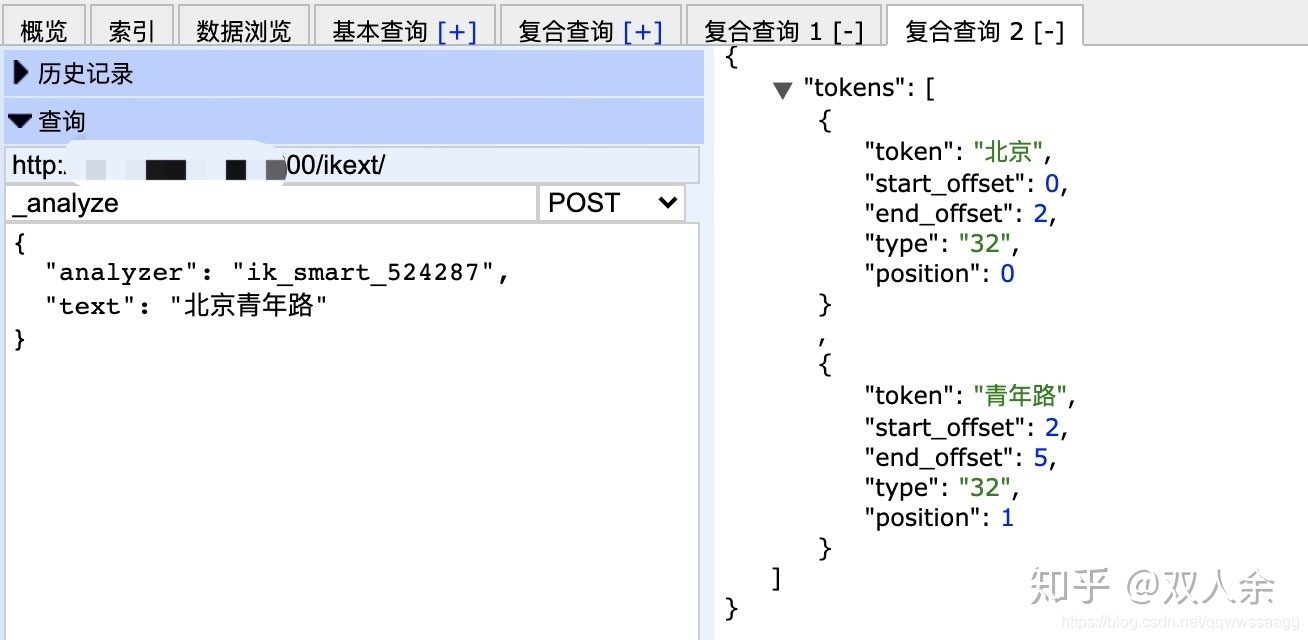
粗粒度会分出:
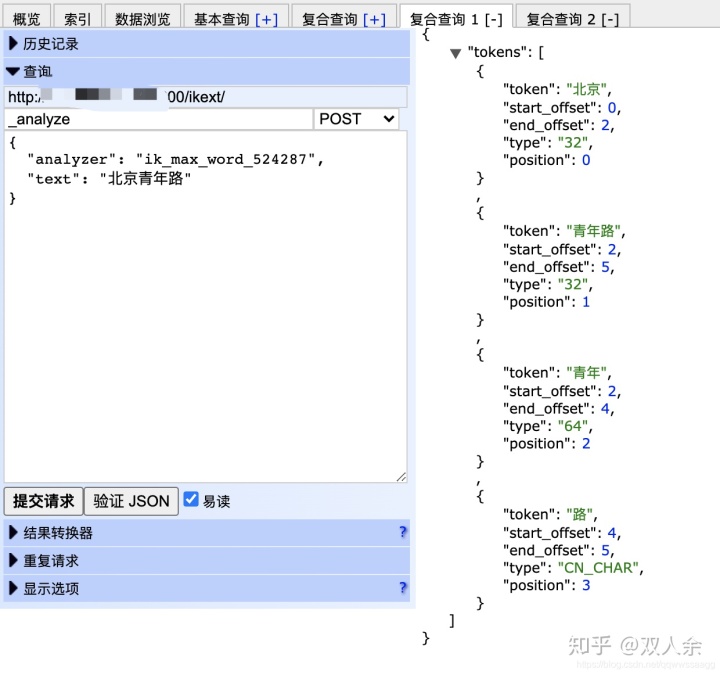
细粒度会分出:
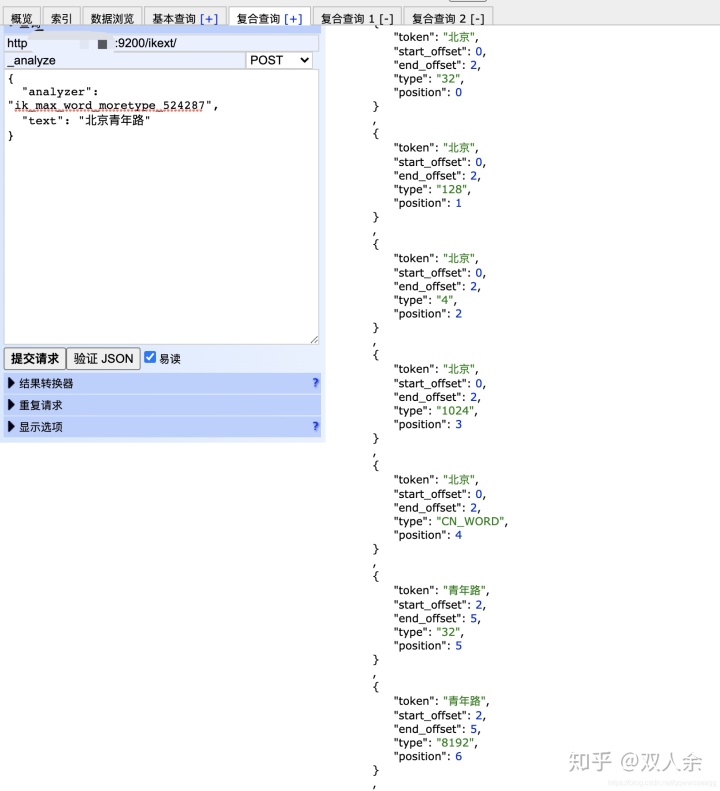
那么我们需要只分出整词、去掉包含词、相同词不去重 如下:
1、歧义词处理
这个功能实际上是用到了IK的歧义词处理,为什么粗粒度不展示包含词和重复词了?是因为做了歧义词过滤,过程如下:
在IKAegmennter.java的next方法中进行歧义词处理
背景:
IK分词器分为两种,粗粒度分词和细粒度分词,粗粒度会分为长词,细粒度分出的词比较多,会分出与词库中所有可匹配的词,现在我们想要这样的分词效果如:
关键词:“北京青年路”
粗粒度会分出:
细粒度会分出:
那么我们需要只分出整词、去掉包含词、相同词不去重 如下:
1、歧义词处理
这个功能实际上是用到了IK的歧义词处理,为什么粗粒度不展示包含词和重复词了?是因为做了歧义词过滤,过程如下:
在IKAegmennter.java的next方法中进行歧义词处理
 1061
1061











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章





















