







数据库中的集合操作主要包括3个方面:
1. Union合并行
union的作用是为了合并两个查询结果,而且在合并的同时把相同的行去重。
例如:

如果我们需要显示全部的并集,即不去重,可以使用union all,如下:
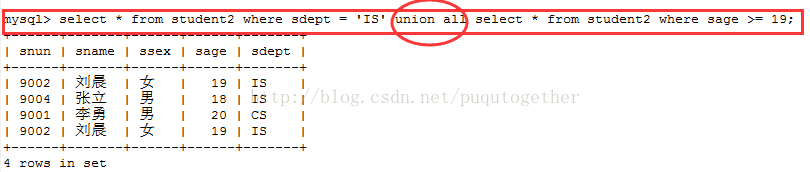
我们只需要使用union来连接两个select-from-where语句块即可。
union有如下几个注意点:
1)union是可交换的操作,A union B的结果和B union A的结果相同;
2)理论上,select语句块在union中出现的顺序对于运行速度没有影响,但是在实际应用中可能有影响。我们尽量把小表的查询放在union的前面,因为优化器合并中间结果和除去重复行的方式不同。当然,不同的DBMS的影响可能不同;
3)intersect的优先级比union、except要高。其中,intersect是查找相同行,except是查找不同行。这也是和不同DBMS有关的;
4)在可以使用组合的select-from-where语句块的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1501
1501











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









