








一、概述
Kylin依赖Hadoop集群来处理大型数据集。您需要准备一个Hadoop集群,其中包含HDFS、YARN、MapReduce、Hive、HBase、Zookeeper等服务,以便Kylin运行。我这里下载的kylin版本是2.6.5,基于HDP3.1.4进行安装的,各个组件的版本如下:
HDFS |
3.1.1.3.1 |
Hive |
3.1.0 |
HBase |
2.0.2 |
| Kylin | 2.6.5 |
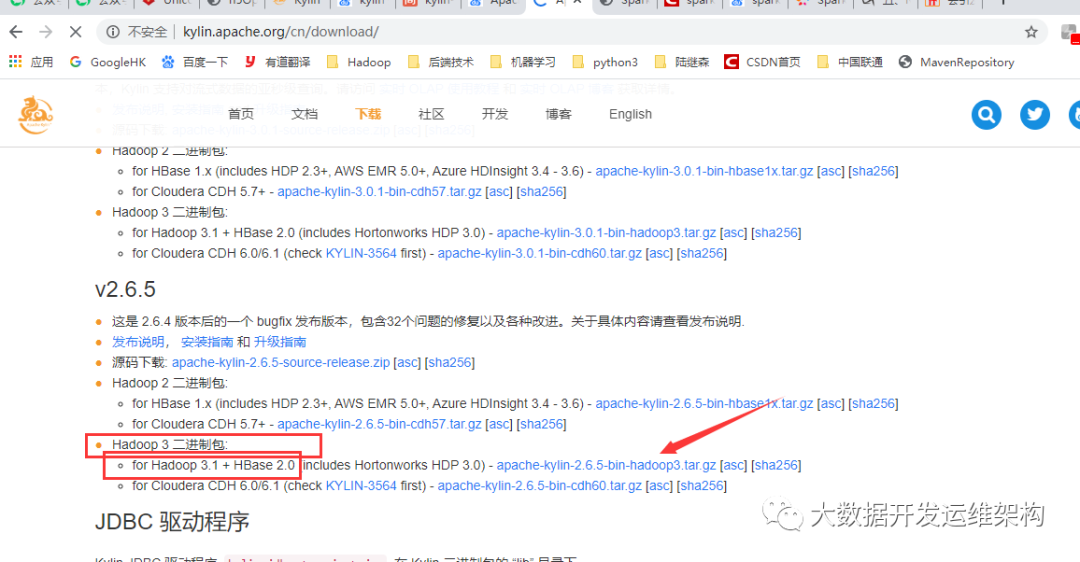
从官网下载kylin时,需要下载hadoop3版本对应的tar包,截图如下:
二、安装配置
Kylin可以在Hadoop集群的任何节点上启动。为了方便,您可以在主节点上运行Kylin。为了更好的稳定性,建议将Kylin部署在一个干净的Hadoop客户端节点上,并安装Hive、HBase、HDFS和其他命令行并配置客户端。
运行Kylin的Linux帐户必须能够访问Hadoop集群,包括创建/写入HDFS文件夹、Hive表、HBase表和提交MapReduce任务的权限,如果没有操作权限也可以手动在创建,然后授权即可,这里我就是手动提前创建然后授权,下面会详细讲解。
1.解压tar包,并重命名,命令如下:
tar -zxvf apache-kylin-2.6.5-bin-hadoop3.tar.gzmv apache-kylin-2.6.5-bin-hadoop3 kylin-2.6.52.从v2.6.1开始,Kylin将不再发布Spark二进制;您需要单独安装Spark,然后将SPARK_HOME系统环境变量指向它:
export SPARK_HOME=/path/to/spark 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 575
575











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









